Stocker ~3,5 To de données et insérer environ 1K/sec 24h/24 et 7j/7, et aussi interroger à un taux non spécifié, c'est possible avec SQL Server, mais il y a plus de questions :
- quelle exigence de disponibilité avez-vous pour cela ? 99,999 % de disponibilité, ou 95 % suffisent-ils ?
- quelle exigence de fiabilité avez-vous ? L'oubli d'un encart vous coûte-t-il 1 million de dollars ?
- quelle exigence de récupération avez-vous ? Si vous perdez une journée de données, est-ce important ?
- quelle exigence de cohérence avez-vous ? Une écriture doit-elle être garantie d'être visible lors de la lecture suivante ?
Si vous avez besoin de toutes ces exigences que j'ai soulignées, la charge que vous proposez va coûter des millions en matériel et en licences sur un système relationnel, n'importe quel système, quels que soient les gadgets que vous essayez (sharding, partitionnement, etc.). Un système nosql, par sa définition même, ne répondrait pas à tous ces exigences.
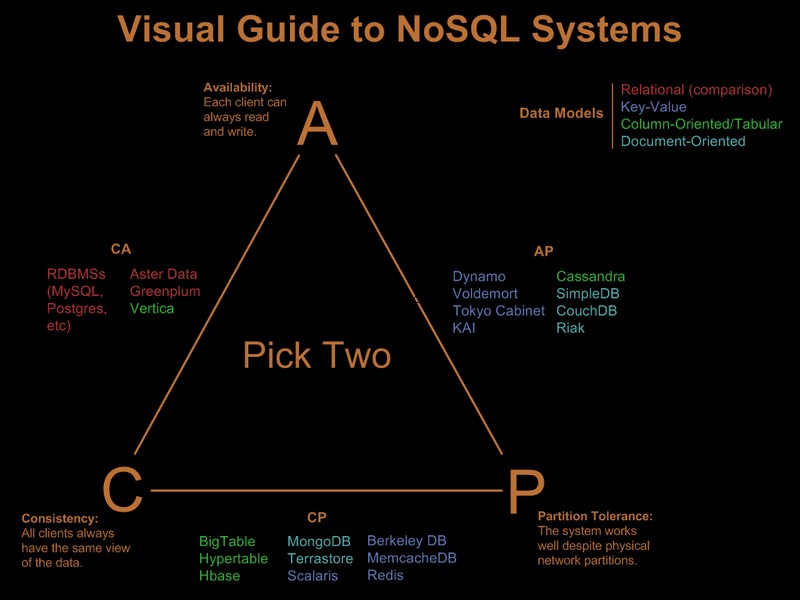
Il est donc évident que vous avez déjà assoupli certaines de ces exigences. Il existe un joli guide visuel comparant les offres nosql basées sur le paradigme "choisir 2 sur 3" dans Visual Guide to NoSQL Systems :
Après la mise à jour du commentaire OP
Avec SQL Server, ce serait une implémentation simple :
- une seule clé groupée de table (GUID, heure). Oui, va être fragmenté, mais la fragmentation affecte les lectures anticipées et les lectures anticipées ne sont nécessaires que pour les balayages de plage importants. Étant donné que vous n'interrogez que des GUID et des plages de dates spécifiques, la fragmentation n'aura pas beaucoup d'importance. Oui, est une clé large, donc les pages sans feuille auront une faible densité de clé. Oui, cela conduira à un mauvais facteur de remplissage. Et oui, des fractionnements de page peuvent se produire. Malgré ces problèmes, compte tenu des exigences, c'est toujours le meilleur choix de clé groupée.
- partitionnez la table par heure afin de pouvoir implémenter une suppression efficace des enregistrements arrivés à expiration, via une fenêtre glissante automatique. Complétez cela avec une reconstruction de partition d'index en ligne du mois dernier pour éliminer le faible facteur de remplissage et la fragmentation introduits par le clustering GUID.
- activer la compression de page. Étant donné que les clés groupées sont d'abord groupées par GUID, tous les enregistrements d'un GUID seront côte à côte, ce qui donne à la compression de page une bonne chance de déployer la compression de dictionnaire.
- vous aurez besoin d'un chemin d'E/S rapide pour le fichier journal. Vous êtes intéressé par un débit élevé, et non par une faible latence pour qu'un journal puisse suivre 1 000 insertions/s. La suppression est donc indispensable.
Le partitionnement et la compression des pages nécessitent chacun un serveur SQL Enterprise Edition, ils ne fonctionneront pas sur l'édition Standard et les deux sont assez importants pour répondre aux exigences.
En remarque, si les enregistrements proviennent d'une batterie de serveurs Web frontaux, je mettrais Express sur chaque serveur Web et au lieu de INSERT sur le backend, je mettrais SEND les informations au back-end, en utilisant une connexion/transaction locale sur l'Express co-localisée avec le serveur Web. Cela donne une bien meilleure histoire de disponibilité à la solution.
Voici donc comment je le ferais dans SQL Server. La bonne nouvelle est que les problèmes auxquels vous serez confrontés sont bien compris et que les solutions sont connues. cela ne signifie pas nécessairement que c'est mieux que ce que vous pourriez réaliser avec Cassandra, BigTable ou Dynamo. Je laisserai quelqu'un de plus compétent dans les choses non-sql-ish pour plaider leur cause.
Notez que je n'ai jamais mentionné le modèle de programmation, le support .Net et autres. Je pense honnêtement qu'ils ne sont pas pertinents dans les grands déploiements. Ils font une énorme différence dans le processus de développement, mais une fois déployés, peu importe la rapidité du développement, si la surcharge ORM tue les performances :)