TeamCity est un serveur d'intégration continue et de livraison continue construit en Java. Il est disponible en tant que service cloud et sur site. Comme vous pouvez l'imaginer, les outils d'intégration et de livraison continues sont cruciaux pour le développement de logiciels, et leur disponibilité ne doit pas être affectée. Heureusement, TeamCity peut être déployé en mode hautement disponible.
Ce billet de blog couvrira la préparation et le déploiement d'un environnement hautement disponible pour TeamCity.
L'environnement
TeamCity se compose de plusieurs éléments. Il existe une application Java et une base de données qui la sauvegarde. Il utilise également des agents qui communiquent avec l'instance principale de TeamCity. Le déploiement hautement disponible se compose de plusieurs instances TeamCity, où l'une agit en tant que principale et les autres secondaires. Ces instances partagent l'accès à la même base de données et au répertoire de données. Un schéma utile est disponible sur la page de documentation de TeamCity, comme indiqué ci-dessous :

Comme nous pouvons le voir, il y a deux éléments partagés : le répertoire de données et la base de données. Nous devons veiller à ce que ceux-ci soient également hautement disponibles. Il existe différentes options que vous pouvez utiliser pour créer un montage partagé ; cependant, nous utiliserons GlusterFS. En ce qui concerne la base de données, nous utiliserons l'un des systèmes de gestion de bases de données relationnelles pris en charge :PostgreSQL, et nous utiliserons ClusterControl pour créer une pile à haute disponibilité autour de celle-ci.
Comment configurer GlusterFS
Commençons par les bases. Nous voulons configurer les noms d'hôte et /etc/hosts sur nos nœuds TeamCity, où nous déploierons également GlusterFS. Pour ce faire, nous devons configurer le référentiel pour les derniers packages de GlusterFS sur chacun d'eux :
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateEnsuite, nous pouvons installer GlusterFS sur tous nos nœuds TeamCity :
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS utilise le port 24007 pour la connectivité entre les nœuds ; nous devons nous assurer qu'il est ouvert et accessible par tous les nœuds.
Une fois la connectivité en place, nous pouvons créer un cluster GlusterFS en exécutant à partir d'un nœud :
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Maintenant, nous pouvons tester à quoi ressemble l'état :
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Il semble que tout va bien et la connectivité est en place.
Ensuite, nous devons préparer un périphérique de bloc à utiliser par GlusterFS. Ceci doit être exécuté sur tous les nœuds. Commencez par créer une partition :
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Ensuite, formatez cette partition :
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Enfin, sur tous les nœuds, nous devons créer un répertoire qui sera utilisé pour monter la partition et modifier fstab pour s'assurer qu'il sera monté au démarrage :
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabVérifions maintenant que cela fonctionne :
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Nous pouvons maintenant utiliser l'un des nœuds pour créer et démarrer le volume GlusterFS :
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successVeuillez noter que nous utilisons la valeur '3' pour le nombre de répliques. Cela signifie que chaque volume existera en trois exemplaires. Dans notre cas, chaque brique, chaque volume /dev/sdb1 sur tous les nœuds contiendra toutes les données.
Une fois les volumes démarrés, nous pouvons vérifier leur statut :
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksComme vous pouvez le voir, tout semble correct. Ce qui est important, c'est que GlusterFS a choisi le port 49152 pour accéder à ce volume, et nous devons nous assurer qu'il est accessible sur tous les nœuds sur lesquels nous allons le monter.
La prochaine étape consistera à installer le package client GlusterFS. Pour cet exemple, nous avons besoin qu'il soit installé sur les mêmes nœuds que le serveur GlusterFS :
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Ensuite, nous devons créer un répertoire sur tous les nœuds à utiliser comme répertoire de données partagé pour TeamCity. Cela doit se produire sur tous les nœuds :
example@sqldat.com:~# sudo mkdir /teamcity-storageEnfin, montez le volume GlusterFS sur tous les nœuds :
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageCeci termine les préparatifs du stockage partagé.
Construire un cluster PostgreSQL hautement disponible
Une fois la configuration du stockage partagé pour TeamCity terminée, nous pouvons maintenant créer notre infrastructure de base de données hautement disponible. TeamCity peut utiliser différentes bases de données; cependant, nous utiliserons PostgreSQL dans ce blog. Nous tirerons parti de ClusterControl pour déployer puis gérer l'environnement de base de données.
Le guide de TeamCity pour la création d'un déploiement multi-nœuds est utile, mais il semble omettre la haute disponibilité de tout autre que TeamCity. Le guide de TeamCity suggère un serveur NFS ou SMB pour le stockage des données, qui, à lui seul, n'a pas de redondance et deviendra un point de défaillance unique. Nous avons résolu ce problème en utilisant GlusterFS. Ils mentionnent une base de données partagée, car un nœud de base de données unique ne fournit évidemment pas une haute disponibilité. Nous devons construire une pile appropriée :

Dans notre cas. il se composera de trois nœuds PostgreSQL, un nœud principal et deux réplicas. Nous utiliserons HAProxy comme équilibreur de charge et utiliserons Keepalived pour gérer l'adresse IP virtuelle afin de fournir un point de terminaison unique auquel l'application se connectera. ClusterControl gérera les échecs en surveillant la topologie de réplication et en effectuant toute récupération requise si nécessaire, comme le redémarrage des processus défaillants ou le basculement vers l'un des réplicas si le nœud principal tombe en panne.
Pour commencer, nous allons déployer les nœuds de la base de données. N'oubliez pas que ClusterControl nécessite une connectivité SSH du nœud ClusterControl à tous les nœuds qu'il gère.

Ensuite, nous choisissons un utilisateur que nous utiliserons pour nous connecter au base de données, son mot de passe et la version de PostgreSQL à déployer :

Ensuite, nous allons définir les nœuds à utiliser pour déployer PostgreSQL :
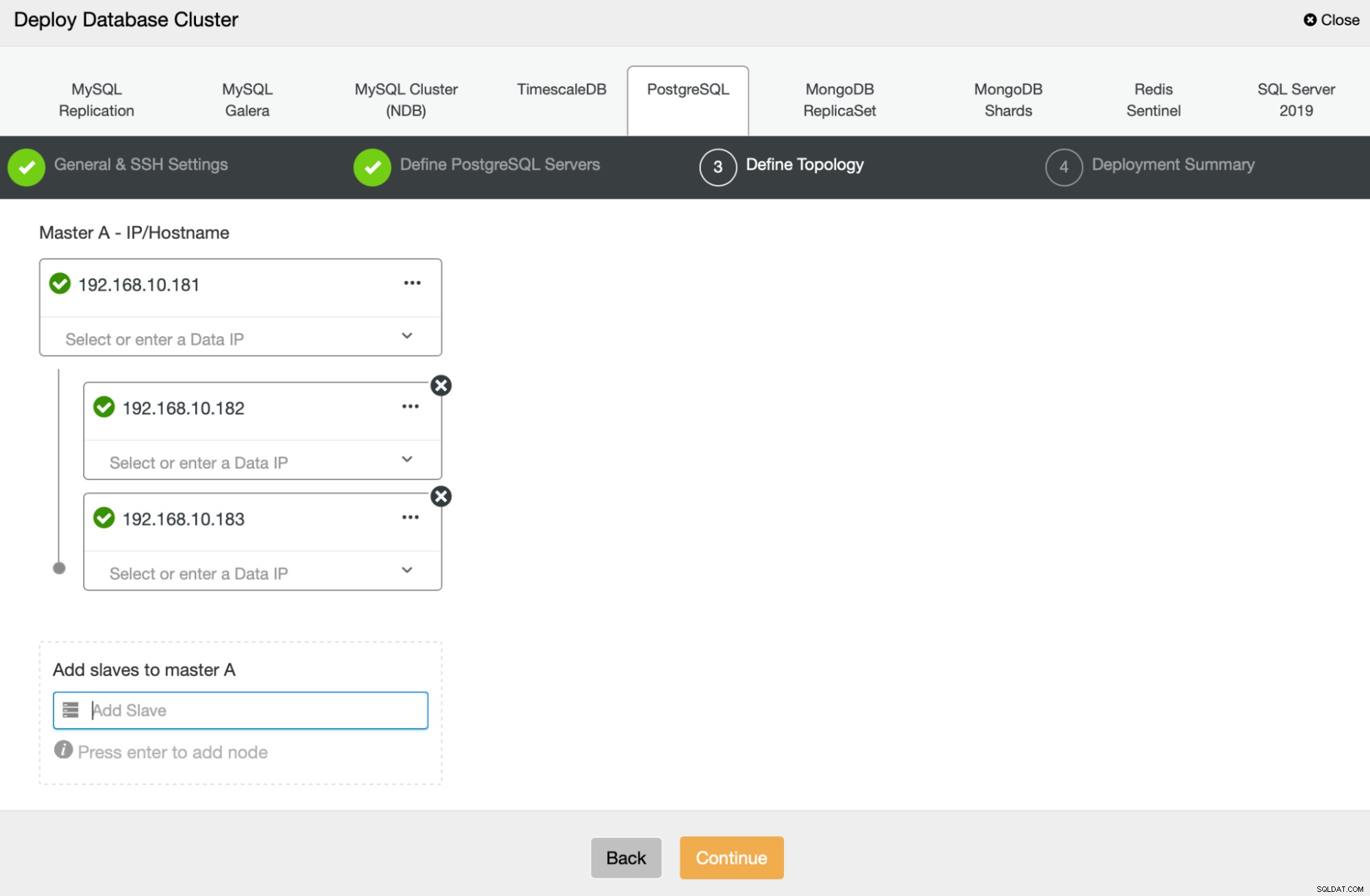
Enfin, nous pouvons définir si les nœuds doivent utiliser la réplication asynchrone ou synchrone. La principale différence entre les deux est que la réplication synchrone garantit que chaque transaction exécutée sur le nœud principal sera toujours répliquée sur les réplicas. Cependant, la réplication synchrone ralentit également la validation. Nous vous recommandons d'activer la réplication synchrone pour une durabilité optimale, mais vous devrez vérifier ultérieurement si les performances sont acceptables.

Une fois que nous avons cliqué sur "Déployer", une tâche de déploiement démarre. Nous pouvons surveiller sa progression dans l'onglet Activité de l'interface utilisateur de ClusterControl. Nous devrions finalement voir que la tâche est terminée et que le cluster a été déployé avec succès.

Déployez des instances HAProxy en accédant à Gérer -> Équilibreurs de charge. Sélectionnez HAProxy comme équilibreur de charge et remplissez le formulaire. Le choix le plus important est l'endroit où vous souhaitez déployer HAProxy. Nous avons utilisé un nœud de base de données dans ce cas, mais dans un environnement de production, vous souhaiterez probablement séparer les équilibreurs de charge des instances de base de données. Ensuite, sélectionnez les nœuds PostgreSQL à inclure dans HAProxy. Nous les voulons tous.

Maintenant, le déploiement HAProxy va commencer. Nous voulons le répéter au moins une fois pour créer deux instances HAProxy pour la redondance. Dans ce déploiement, nous avons décidé d'utiliser trois équilibreurs de charge HAProxy. Ci-dessous, une capture d'écran de l'écran des paramètres lors de la configuration du déploiement d'un deuxième HAProxy :
Lorsque toutes nos instances HAProxy sont opérationnelles, nous pouvons déployer Keepalived . L'idée ici est que Keepalived sera colocalisé avec HAProxy et surveillera le processus de HAProxy. L'une des instances avec HAProxy fonctionnel se verra attribuer une adresse IP virtuelle. Cette VIP doit être utilisée par l'application pour se connecter à la base de données. Keepalived détectera si ce HAProxy devient indisponible et passera à une autre instance HAProxy disponible.
L'assistant de déploiement nous demande de transmettre les instances HAProxy que nous voulons que Keepalived surveille. Nous devons également transmettre l'adresse IP et l'interface réseau pour VIP.

La dernière et dernière étape consistera à créer une base de données pour TeamCity :

Avec cela, nous avons conclu le déploiement du cluster PostgreSQL hautement disponible.
Déploiement de TeamCity en multi-nœud
L'étape suivante consiste à déployer TeamCity dans un environnement multi-nœuds. Nous utiliserons trois nœuds TeamCity. Tout d'abord, nous devons installer Java JRE et JDK qui correspondent aux exigences de TeamCity.
apt install default-jre default-jdkMaintenant, sur tous les nœuds, nous devons télécharger TeamCity. Nous installerons dans un répertoire local et non partagé.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzEnsuite, nous pouvons démarrer TeamCity sur l'un des nœuds :
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logUne fois TeamCity démarré, nous pouvons accéder à l'interface utilisateur et commencer le déploiement. Au départ, nous devons transmettre l'emplacement du répertoire de données. C'est le volume partagé que nous avons créé sur GlusterFS.

Ensuite, choisissez la base de données. Nous allons utiliser un cluster PostgreSQL que nous avons déjà créé.

Téléchargez et installez le pilote JDBC :

Ensuite, remplissez les détails d'accès. Nous utiliserons l'adresse IP virtuelle fournie par Keepalived. Veuillez noter que nous utilisons le port 5433. Il s'agit du port utilisé pour le backend de lecture/écriture de HAProxy; il pointera toujours vers le nœud principal actif. Ensuite, choisissez un utilisateur et la base de données à utiliser avec TeamCity.

Une fois cela fait, TeamCity commencera à initialiser la structure de la base de données.

Accepter le contrat de licence :

Enfin, créez un utilisateur pour TeamCity :

C'est tout ! Nous devrions maintenant pouvoir voir l'interface graphique de TeamCity :

Maintenant, nous devons configurer TeamCity en mode multi-nœuds. Tout d'abord, nous devons éditer les scripts de démarrage sur tous les nœuds :
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shNous devons nous assurer que les deux variables suivantes sont exportées. Veuillez vérifier que vous utilisez le nom d'hôte, l'adresse IP et les répertoires appropriés pour le stockage local et partagé :
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Une fois cela fait, vous pouvez démarrer les nœuds restants :
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startVous devriez voir la sortie suivante dans Administration -> Configuration des nœuds :un nœud principal et deux nœuds de secours.

Veuillez garder à l'esprit que le basculement dans TeamCity n'est pas automatisé. Si le nœud principal cesse de fonctionner, vous devez vous connecter à l'un des nœuds secondaires. Pour ce faire, accédez à "Configuration des nœuds" et faites-en le nœud "Principal". À partir de l'écran de connexion, vous verrez une indication claire qu'il s'agit d'un nœud secondaire :

Dans la "Configuration des nœuds", vous verrez que le nœud a supprimé du cluster :

Vous recevrez un message indiquant que vous ne pouvez pas écrire sur ce nœud. Ne vous inquiétez pas; l'écriture requise pour promouvoir ce nœud au statut "principal" fonctionnera parfaitement :

Cliquez sur "Activer" et nous avons réussi à promouvoir un nœud TimeCity secondaire :

Lorsque le nœud 1 devient disponible et que TeamCity est redémarré sur ce nœud, nous allons voyez-le rejoindre le cluster :

Si vous souhaitez améliorer davantage les performances, vous pouvez déployer HAProxy + Keepalived devant l'interface utilisateur TeamCity pour fournir un point d'entrée unique à l'interface graphique. Vous pouvez trouver des détails sur la configuration de HAProxy pour TeamCity dans la documentation.
Conclusion
Comme vous pouvez le constater, le déploiement de TeamCity pour une haute disponibilité n'est pas si difficile - la plupart d'entre eux ont été traités en détail dans la documentation. Si vous cherchez des moyens d'automatiser une partie de cela et d'ajouter un backend de base de données hautement disponible, envisagez d'évaluer ClusterControl gratuitement pendant 30 jours. ClusterControl peut rapidement déployer et surveiller le backend, en fournissant un basculement, une récupération, une surveillance, une gestion des sauvegardes automatisés, etc.
Pour plus de conseils sur les outils de développement logiciel et les meilleures pratiques, découvrez comment aider votre équipe DevOps à répondre à ses besoins en matière de base de données.
Pour obtenir les dernières nouvelles et les meilleures pratiques pour gérer votre infrastructure de base de données open source, n'oubliez pas de nous suivre sur Twitter ou LinkedIn et de vous abonner à notre newsletter. A bientôt !