La réplication transactionnelle SQL Server est l'une des techniques de réplication les plus courantes utilisées pour copier ou distribuer des données sur plusieurs destinations.
Dans les articles précédents, nous avons discuté de la réplication SQL Server, de son fonctionnement interne et de la configuration de la réplication via l'assistant de réplication ou l'approche T-SQL. Maintenant, nous nous concentrons sur les problèmes de réplication SQL et les dépannons correctement.
Problèmes de réplication SQL
La majorité des clients qui utilisent la réplication transactionnelle SQL Server se concentrent principalement sur l'obtention de données en temps quasi réel disponibles dans les instances de base de données de l'abonné. Par conséquent, l'administrateur de base de données qui gère la réplication doit être conscient des divers problèmes liés à la réplication SQL qui pourraient survenir. De plus, le DBA doit être en mesure de résoudre ces problèmes dans un court laps de temps.
Nous pouvons classer tous les problèmes de réplication SQL dans les catégories ci-dessous (selon mon expérience) :
Problèmes de configuration
- Taille maximale de réplication de texte
- Le service SQL Server Agent n'est pas configuré pour démarrer le mode automatique
- Les instances de réplication non surveillées passent à un état d'abonnements non initialisé
- Problèmes connus dans SQL Server
Problèmes d'autorisation
- Problèmes d'autorisation de tâche de l'Agent SQL Server
- Les informations d'identification de la tâche de l'Agent d'instantané ne peuvent pas accéder au chemin du dossier d'instantanés
- Les informations d'identification de la tâche de l'agent de lecture du journal ne peuvent pas se connecter à la base de données de l'éditeur/de la distribution
- Les informations d'identification du poste d'agent de distribution ne peuvent pas se connecter à la base de données de distribution/d'abonnés
Problèmes de connectivité
- Le serveur de l'éditeur est introuvable ou n'est pas accessible
- Le serveur de distribution est introuvable ou n'est pas accessible
- Le serveur d'abonné n'a pas été trouvé ou n'était pas accessible
Problèmes d'intégrité des données
- Erreurs de violation de clé primaire ou de clé unique
- Erreurs de ligne introuvable
- Erreurs de violation de clé étrangère ou d'autres contraintes
Problèmes de performances
- Transactions actives de longue durée dans la base de données de l'éditeur
- Opérations INSERT/UPDATE/DELETE en masse sur les articles
- Modifications considérables des données en une seule transaction
- Blocages dans la base de données de distribution
Problèmes liés à la corruption
- Corruptions de la base de données de l'éditeur
- Corruptions du fichier journal des transactions de l'éditeur
- Corruptions de la base de données de distribution
- Corruptions de la base de données des abonnés
Préparation de l'environnement DEMO
Avant de plonger dans les détails des problèmes de réplication SQL, nous devons préparer notre environnement pour la démonstration. Comme indiqué dans mes articles précédents, toutes les modifications de données qui se produisent sur la base de données de l'abonné dans la réplication transactionnelle ne seront pas visibles directement dans la base de données de l'éditeur. Ainsi, nous allons apporter certaines modifications directement dans la base de données Abonnés à des fins d'apprentissage.
Soyez extrêmement prudent et ne modifiez rien dans les bases de données de production. Cela aura un impact sur l'intégrité des données des bases de données des abonnés. Je prendrai les scripts de sauvegarde pour chaque modification effectuée et utiliserai ces scripts pour résoudre les problèmes de réplication SQL.
Modification 1 - Insertion d'enregistrements dans la table Person.ContactType
Avant d'insérer des enregistrements dans Person.ContacType table, examinons cette structure de table, quelques contraintes par défaut et des propriétés étendues rédigées dans le script ci-dessous :
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
J'ai choisi ce tableau car il a moins de colonnes. C'est plus pratique à des fins de test. Voyons maintenant ce que nous savons de sa structure :
- Identifiant du type de contact est défini comme une COLONNE D'IDENTITÉ - il générera automatiquement les valeurs de clé primaire et PAS POUR LA RÉPLICATION.
- NOT FOR REPLICATION est une propriété spéciale qui peut être utilisée sur divers types d'objets tels que les tables, les contraintes telles que les contraintes de clé étrangère, les contraintes de vérification, les déclencheurs et les colonnes d'identité sur l'éditeur ou l'abonné tout en utilisant l'une des méthodologies de réplication uniquement. Il permet au DBA de planifier ou d'implémenter la réplication pour s'assurer que certaines fonctionnalités se comportent différemment dans l'éditeur/l'abonné lors de l'utilisation de la réplication.
- Dans notre cas, nous demandons à SQL Server d'utiliser les valeurs IDENTITY générées uniquement sur la base de données Publisher. La propriété IDENTITY ne doit pas être utilisée sur Person.ContactType table dans la base de données des abonnés. De même, nous pouvons modifier les contraintes ou les déclencheurs pour qu'ils se comportent différemment lorsque la réplication est configurée à l'aide de cette option.
- 2 autres colonnes NOT NULL sont disponibles dans le tableau.
- La table a une clé primaire définie sur ContactTypeId . Pour rappel, la clé primaire est une condition obligatoire pour la réplication. Sans cela sur un tableau, nous ne serions pas en mesure de reproduire un article de tableau.
Maintenant, INSÉRONS un exemple d'enregistrement dans Personne .TypeContact tableau dans AdventureWorks_REPL base de données :
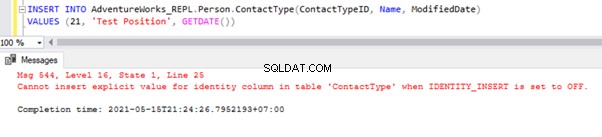
L'insertion directe sur la table échouera sur la base de données de l'abonné car la propriété d'identité est désactivée uniquement pour la réplication par l'option NOT FOR REPLICATION. Chaque fois que nous effectuons l'opération INSERT manuellement, nous devons toujours utiliser l'option SET IDENTITY_INSERT comme ceci :
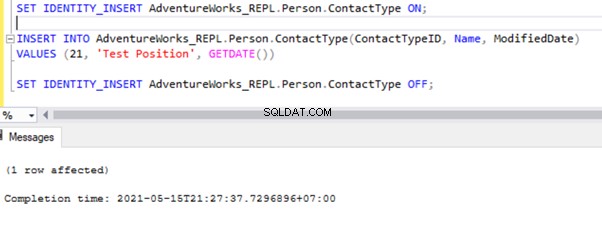
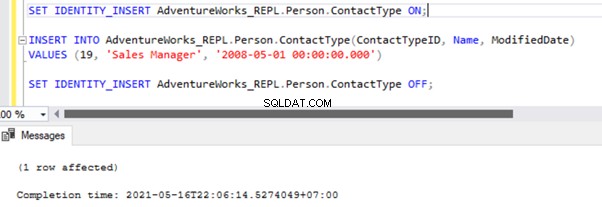
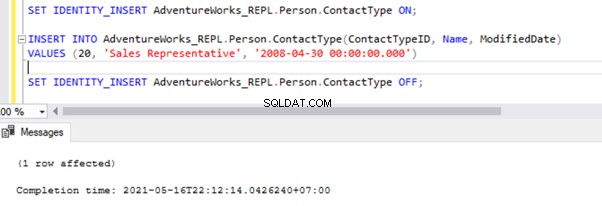
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Après avoir ajouté l'option SET IDENTITY_INSERT, nous pouvons INSERT enregistrer avec succès dans le Person.ContactType tableau.
L'exécution de SELECT sur la table affiche le nouvel enregistrement inséré :
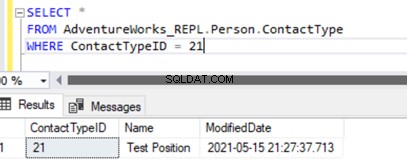
Nous avons ajouté un nouvel enregistrement uniquement à la base de données des abonnés qui n'est pas disponible dans la base de données de l'éditeur sur Person.ContactType tableau.
L'exécution d'un SELECT sur la même table de la base de données Publisher n'affiche aucun enregistrement. Ainsi, toutes les modifications apportées à la base de données de l'abonné ne sont pas répliquées dans la base de données de l'éditeur.
Modification 2 - Suppression de 2 enregistrements de la table Person.ContactType
Nous nous en tenons à notre familier Person.ContactType table. Avant de supprimer des enregistrements de la base de données des abonnés, nous devons vérifier si ces enregistrements existent à la fois sur l'éditeur et sur l'abonné. Voir ci-dessous :
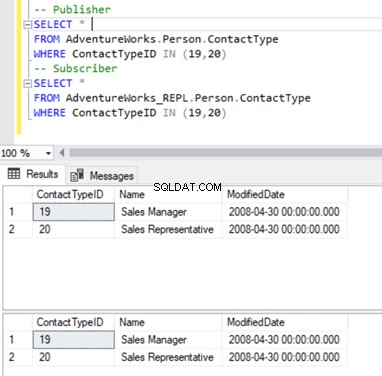
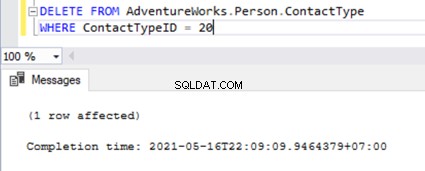
Maintenant, nous pouvons supprimer ces 2 ContactTypeId en utilisant l'instruction suivante :
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Le script ci-dessus nous permet de supprimer 2 enregistrements du Person.ContactType table dans la base de données des abonnés :
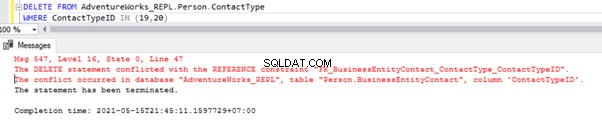
Nous avons la référence de clé étrangère qui empêche la suppression de ces 2 enregistrements de Person.ContactType table. Nous pouvons gérer ce scénario en désactivant temporairement la contrainte de clé étrangère sur la table enfant. Le script est ci-dessous :
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Une fois les clés étrangères désactivées, nous pouvons supprimer avec succès les enregistrements de Person.ContactType tableau :
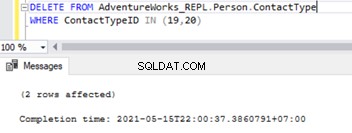
Cela a également modifié la contrainte référentielle de clé étrangère sur les 2 tables. Nous pouvons essayer de simuler des problèmes de réplication SQL en fonction de ce scénario.
Dans notre scénario actuel, nous savons que le Person.ContactType table n'avait pas de données synchronisées entre l'éditeur et l'abonné.
Croyez-moi, dans quelques environnements de production, les développeurs ou les administrateurs de base de données effectuent des corrections de données sur la base de données des abonnés. comme toutes les modifications que nous avons effectuées précédemment, cela a causé des problèmes d'intégrité des données dans les bases de données de l'éditeur et de l'abonné dans la même table. En tant que DBA, j'ai besoin d'un mécanisme plus simple pour vérifier ces types de divergences. Sinon, cela rendrait la vie du DBA pathétique.
Voici la solution de Microsoft qui nous permet de vérifier les écarts de données entre les tables de l'éditeur et de l'abonné. Oui, vous avez bien deviné. C'est l'utilitaire TableDiff dont nous avons parlé dans les articles précédents.
Utilitaire TableDiff
L'utilitaire TableDiff est principalement utilisé dans les environnements de réplication. Nous pouvons également l'utiliser pour d'autres cas où nous devons comparer 2 tables SQL Server pour la non-convergence. Nous pouvons les comparer et identifier les différences entre ces 2 tables. Ensuite, l'utilitaire aide à synchroniser la Destination tableau à la Source tableau en générant les scripts INSERT/UPDATE/DELETE nécessaires.
TableDiff est un programme autonome tablediff.exe installé par défaut sur C:\Program Files\Microsoft SQL Server\130\COM une fois que nous avons installé les composants de réplication. Veuillez noter que le chemin par défaut peut varier en fonction des paramètres d'installation de SQL Server. Le nombre 130 dans le chemin indique la version de SQL Server (SQL Server 2016). Par conséquent, cela variera pour chaque version différente de l'installation de SQL Server.
Vous pouvez accéder à l'utilitaire TableDiff via l'invite de commande ou à partir de fichiers de commandes uniquement. L'utilitaire n'a pas d'assistant sophistiqué ni d'interface graphique à utiliser. La syntaxe détaillée de l'utilitaire TableDiff se trouve dans l'article MSDN. Notre article actuel se concentre uniquement sur certaines options nécessaires.
Pour comparer 2 tables à l'aide de l'utilitaire TableDiff, nous devons fournir des détails obligatoires pour les tables source et destination, telles que le nom du serveur source, le nom de la base de données source, le nom du schéma source, le nom de la table source, le nom du serveur de destination, le nom de la base de données de destination, la destination. Nom du schéma et nom de la table de destination.
Essayons de tester TableDiff avec le Person.ContactType tableau présentant des différences entre l'éditeur et l'abonné.
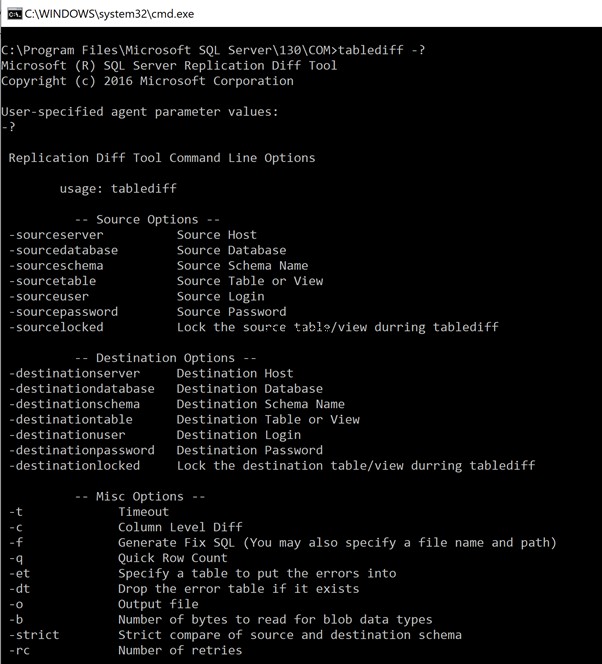
Ouvrez l'invite de commande et accédez au chemin de l'utilitaire TableDiff (si ce chemin n'est pas ajouté aux variables d'environnement).
Pour afficher la liste de tous les paramètres disponibles, tapez la commande "tablediff-?" pour lister toutes les options et tous les paramètres disponibles. Les résultats sont ci-dessous :
Vérifions le Person.ContactType table dans nos bases de données d'éditeurs et d'abonnés en exécutant la commande ci-dessous :
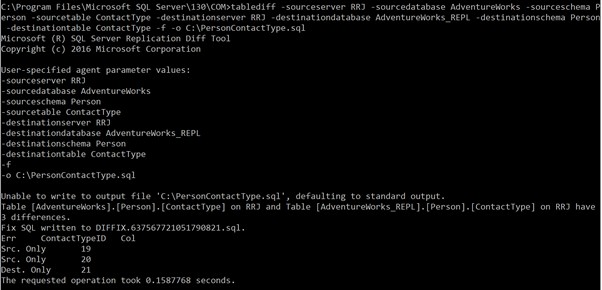
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeNotez que je n'ai pas fourni le sourceuser , mot de passe source , utilisateur de destination , et mot de passe de destination puisque ma connexion Windows a accès aux tables. Si vous souhaitez utiliser les informations d'identification SQL au lieu de l'authentification Windows, les paramètres ci-dessus sont obligatoires pour accéder aux tableaux de comparaison . Sinon, vous recevrez des erreurs.
Les résultats de l'exécution correcte de la commande :
Cela montre que nous avons 3 écarts. L'un est un nouvel enregistrement dans la base de données de destination et deux enregistrements ne sont pas disponibles dans la base de données de destination.
Maintenant, jetons un coup d'œil aux Divers options disponibles pour l'utilitaire TableDiff.
- -et – enregistre le résumé des résultats dans la table de destination
- -dt – supprime la table de destination des résultats si elle existe déjà
- -f – génère un script T-SQL DML avec des instructions INSERT/UPDATE/DELETE pour amener la table de destination à la convergence avec la table source.
- -o – nom du fichier de sortie si l'option -f est utilisé pour générer le fichier de convergence.
Nous allons créer un fichier de convergence avec le -f et -o options à notre commande précédente :
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlLe fichier de convergence est créé avec succès :
Comme vous pouvez le voir, la création d'un nouveau fichier dans le dossier racine du lecteur C:n'est pas autorisée pour des raisons de sécurité. Par conséquent, il affiche un message d'erreur et crée le fichier de sortie fichier DIFFIX.*.sql dans le dossier de l'utilitaire TableDiff. Lorsque nous ouvrons ce fichier, nous pouvons voir les détails ci-dessous :

Les scripts INSERT ont été créés pour les 2 enregistrements supprimés et les scripts DELETE ont été créés pour les enregistrements nouvellement insérés dans la base de données de l'abonné. L'outil se soucie également d'utiliser les options IDENTITY_INSERT comme requis pour la Destination table. Par conséquent, cet outil sera d'une grande utilité chaque fois qu'un DBA aura besoin de synchroniser deux tables.
Dans notre cas, je n'exécuterai pas les scripts, car nous avons besoin de ces écarts pour simuler nos problèmes de réplication SQL.
Avantages de l'utilitaire TableDiff
- TableDiff est un utilitaire gratuit qui fait partie de l'installation des composants de réplication SQL Server et qui est utilisé pour la comparaison ou la convergence de tables.
- Les scripts de création de convergence peuvent être créés sans intervention manuelle.
Limites de l'utilitaire TableDiff
- L'utilitaire TableDiff ne peut être exécuté qu'à partir de l'invite de commande ou du fichier batch.
- À partir de l'invite de commande, vous ne pouvez effectuer qu'une seule comparaison de table à la fois, sauf si plusieurs invites de commande sont ouvertes en parallèle pour comparer plusieurs tables.
- La table source que vous devez comparer à l'aide de l'utilitaire TableDiff nécessite soit une clé primaire, soit une colonne d'identité définie, soit la colonne ROWGUID disponible pour effectuer la comparaison ligne par ligne. Si le -strict est utilisée, la table Destination nécessite également une clé primaire, ou une colonne Identité, ou la colonne ROWGUID disponible.
- Si la table source ou destination contient le sql_variant colonne de type de données, vous ne pouvez pas utiliser l'utilitaire TableDiff pour le comparer.
- Des problèmes de performances peuvent être constatés lors de l'exécution de l'utilitaire TableDiff sur des tables contenant des enregistrements volumineux, car il effectuera la comparaison ligne par ligne sur ces tables.
- Les scripts de convergence créés par l'utilitaire TableDiff n'incluent pas les colonnes de type de données de caractères BLOB, telles que varchar(max) , nvarchar(max) , varbinaire(max) , texte , ntexte , ou image colonnes et xml ou horodatage Colonnes. Par conséquent, vous avez besoin d'approches alternatives pour gérer les tables avec ces colonnes de type de données.
Cependant, même avec ces limitations, l'utilitaire TableDiff peut être utilisé sur n'importe quelle table SQL Server pour une vérification rapide des données ou un contrôle de convergence. Cependant, vous pouvez également acheter un bon outil tiers.
Examinons maintenant en détail les différents problèmes de réplication SQL.
Problèmes de configuration
D'après mon expérience, j'ai classé les options de configuration de réplication fréquemment manquées qui peuvent entraîner des problèmes critiques de réplication SQL comme Configuration questions. Certains d'entre eux sont ci-dessous.
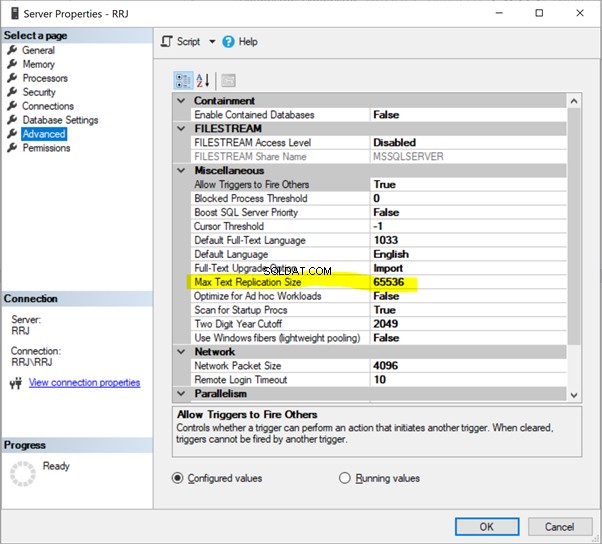
Taille maximale de réplication de texte
Taille maximale de remplacement du texte fait référence à la taille maximale de réplication de texte en octets . Il s'applique à tous les types de données comme char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, etimage .
SQL Server a une option par défaut pour limiter la longueur maximale de colonne de type de données de chaîne (en octets) à répliquer en tant que 65536 octets.
Nous devons évaluer avec soin la taille maximale de la réplication du texte chaque fois que la réplication est configurée pour une base de données. Pour cela, nous devons vérifier toutes les colonnes de type de données ci-dessus et identifier le maximum d'octets possibles qui seront transférés via la réplication.
Changer la valeur à -1 indique qu'il n'y a pas de limites. Cependant, nous vous recommandons d'évaluer la longueur de chaîne maximale et de configurer cette valeur.
Nous pouvons configurer Max Text Repl Size en utilisant SSMS ou T-SQL.
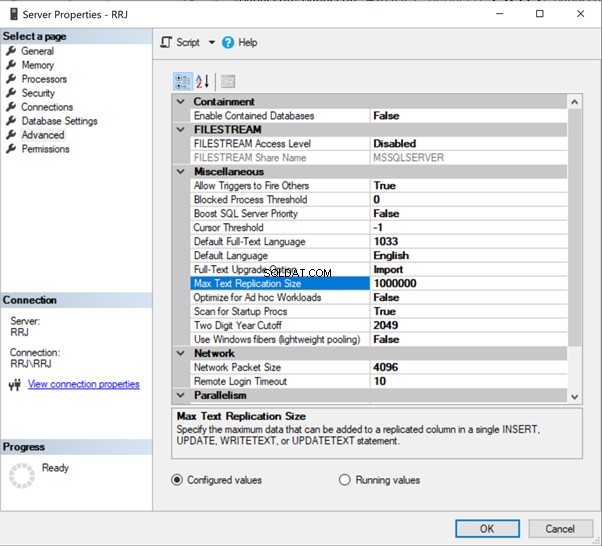
Dans SSMS, faites un clic droit sur le nom du serveur> Propriétés > Avancé :
Cliquez simplement sur 65536 pour le modifier. Pour les tests, j'ai changé 65536 en 1000000 et cliqué sur OK :
Pour configurer l'option Max Text Repl Size via T-SQL, ouvrez une nouvelle fenêtre de requête et exécutez le script ci-dessous sur la base de données principale :
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Cette requête permettra à Replication de ne pas limiter la taille des colonnes de type de données ci-dessus.
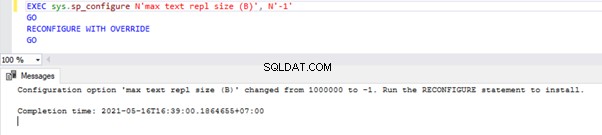
Pour vérifier, nous pouvons effectuer un SELECT sur sys.configurations DMV et vérifiez la value_in_use colonne comme ci-dessous :

Le service de l'Agent SQL Server n'est pas configuré pour démarrer le mode automatique
La réplication s'appuie sur des agents de réplication qui sont exécutés en tant que travaux de l'Agent SQL Server. Par conséquent, tout problème avec certains services de l'agent SQL Server aura un impact direct sur la fonctionnalité de réplication.
Nous devons nous assurer que le mode de démarrage de SQL Server et les services de l'agent SQL Server sont définis sur Automatique. S'il est défini sur Manuel, nous devons configurer certaines alertes. Ils aviseraient le DBA ou les administrateurs du serveur de démarrer le service SQL Server Agent lorsque le serveur redémarre, qu'il soit planifié ou non.
Si ce n'est pas fait, la réplication peut ne pas s'exécuter pendant une longue période, ce qui affecte également les autres travaux de l'Agent SQL Server.
Les instances de réplication non surveillées passent à un état d'abonnements non initialisés
Semblable à la surveillance du service de l'agent SQL Server, la configuration du service de messagerie de base de données dans n'importe quelle instance de SQL Server joue un rôle essentiel dans l'alerte du DBA ou de la personne configurée en temps opportun. Pour tout échec ou problème de travail, les travaux de l'Agent SQL Server comme l'Agent de lecture du journal ou l'Agent de distribution peuvent être configurés pour envoyer des alertes au DBA ou au membre de l'équipe concerné par e-mail. L'échec de l'exécution de la tâche Replication Agent peut entraîner les scénarios ci-dessous :
Non-exécution de la tâche de l'Agent de lecture du journal . Le fichier journal des transactions de la base de données de l'éditeur ne sera réutilisé qu'après la commande marqué pour réplication est lu par l'Agent de lecture du journal et envoyé avec succès à la base de données de distribution. Sinon, le log_reuse_wait_desc colonne de sys.databases affichera la valeur en tant que réplication, indiquant que le journal de la base de données ne peut pas être réutilisé tant qu'il n'a pas réussi à transférer les modifications vers la base de données de distribution. Par conséquent, la non-exécution de l'agent Log Reader continuera d'augmenter la taille du fichier journal transactionnel de la base de données de l'éditeur et nous rencontrerons des problèmes de performances lors de la sauvegarde complète ou des problèmes d'espace disque sur l'instance de la base de données de l'éditeur.
Non-exécution de la tâche d'agent de distribution. Le travail de l'Agent de distribution lit les données de la base de données de distribution et les envoie à la base de données de l'Abonné. Ensuite, il marque ces enregistrements pour suppression dans la base de données de distribution. Si le travail de l'agent de distribution ne s'exécute pas, il augmentera la taille de la base de données de distribution, ce qui entraînera des problèmes de performances pour les performances globales de réplication. Par défaut, la base de données de distribution est configurée pour conserver les enregistrements pendant un maximum de 0 à 72 heures, comme indiqué dans la propriété Transaction Retention ci-dessous. Si la réplication échoue pendant plus de 72 heures, l'abonnement correspondant sera marqué comme non initialisé, ce qui nous obligera soit à reconfigurer l'abonnement, soit à générer un nouvel instantané pour que la réplication fonctionne à nouveau.
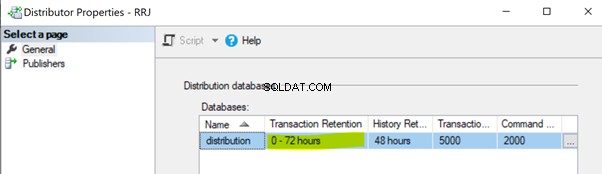
Non-exécution du nettoyage de distribution :tâche de distribution . Le travail de nettoyage de distribution est responsable de la suppression de tous les enregistrements répliqués de la base de données de distribution pour garder la taille de la base de données de distribution sous contrôle. La non-exécution de cette tâche entraîne une augmentation de la taille de la base de données de distribution, ce qui entraîne des problèmes de performances de réplication.
Pour nous assurer que nous ne rencontrons aucun de ces problèmes non surveillés, la messagerie de base de données doit être configurée pour signaler tous les échecs ou tentatives de travail aux membres de l'équipe respective pour une action rapide.
Problèmes connus dans SQL Server
Certaines versions de SQL Server présentaient des problèmes de réplication connus dans la version RTM ou des versions antérieures. Ces problèmes ont été résolus dans les Service Packs ou CU packs ultérieurs. Par conséquent, il est recommandé d'appliquer les derniers Service Packs ou CU packs une fois disponibles pour tous les SQL Server après les avoir testés dans l'environnement QA. Même s'il s'agit d'une recommandation générale pour les serveurs exécutant SQL Server, elle s'applique également à la réplication.
Problèmes d'autorisation
Dans un environnement avec la réplication transactionnelle SQL Server configurée, nous pouvons fréquemment observer les problèmes d'autorisations. Nous pouvons y faire face au moment de la configuration de la réplication ou de toute activité de maintenance sur l'éditeur, le distributeur ou les instances de base de données de l'abonné. Cela entraîne la perte d'informations d'identification ou d'autorisations. Observons maintenant quelques problèmes d'autorisation fréquents liés à la réplication.
Problèmes d'autorisation des tâches de l'Agent SQL Server
Tous les agents de réplication utilisent des travaux de l'Agent SQL Server. Chaque tâche de l'Agent SQL Server liée à l'instantané ou à l'Agent de lecture du journal, ou à la distribution est exécutée sous certaines informations d'identification de connexion Windows ou SQL, comme indiqué ci-dessous :
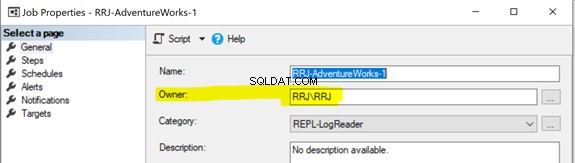
Pour démarrer une tâche de l'Agent SQL Server, vous devez posséder soit le rôle SQLAgentOperatorRole pour démarrer toutes les tâches ou soit SQLAgentUserRole ou le SQLAgentReaderRole pour commencer les emplois que vous possédez. Si une tâche n'a pas pu démarrer correctement, vérifiez si le propriétaire de la tâche dispose des droits nécessaires pour exécuter cette tâche.
Les informations d'identification du travail de l'agent d'instantané ne peuvent pas accéder au chemin du dossier d'instantané
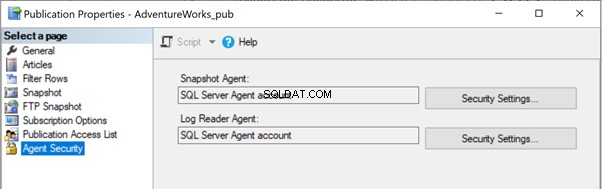
Dans nos articles précédents, nous avons remarqué que l'exécution de l'agent d'instantané créait l'instantané des articles dans le chemin du dossier local ou partagé à propager à la base de données de l'abonné via l'agent de distribution. L'emplacement du chemin de l'instantané peut être identifié sous les Propriétés de la publication > Instantané :
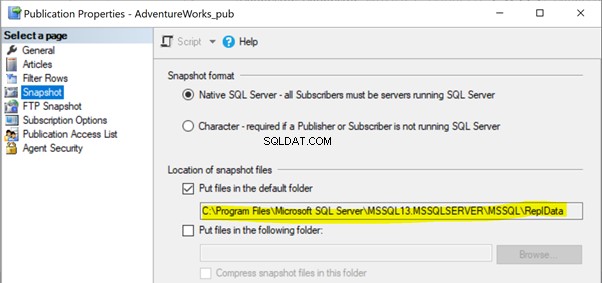
Si l'agent d'instantané n'a pas accès à cet emplacement de fichiers d'instantané, nous pouvons recevoir l'erreur :
L'accès au chemin "C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\" est refusé.
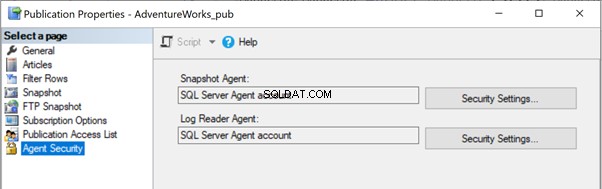
Pour résoudre le problème, il est préférable d'accorder un accès complet au chemin du dossier C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ pour le compte sous lequel l'Agent de capture instantanée s'exécute. Dans notre configuration, nous utilisons le compte SQL Server Agent et le service SQL Server Agent s'exécute sous le compte RRJ\RRJ.
Les informations d'identification du travail de l'agent de lecture du journal ne peuvent pas se connecter à la base de données de l'éditeur/de la distribution
L'agent de lecture du journal se connecte à la base de données de l'éditeur pour exécuter le sp_replcmds procédure pour rechercher les transactions marquées pour la réplication à partir des journaux transactionnels de la base de données de l'éditeur.
Si le propriétaire de la base de données de l'éditeur n'est pas défini correctement, nous pouvons recevoir les erreurs suivantes :
Le processus n'a pas pu exécuter 'sp_replcmds' sur 'RRJ.
Ou
Impossible d'exécuter en tant que principal de la base de données car le principal "dbo" n'existe pas, ce type de principal ne peut pas être emprunté ou vous n'avez pas l'autorisation.
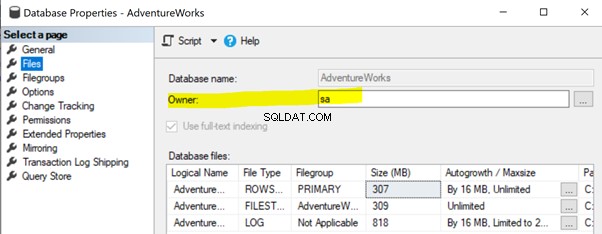
Pour résoudre ce problème, assurez-vous que la propriété du propriétaire de la base de données de la base de données de l'éditeur est définie sur sa ou un autre compte valide (voir ci-dessous).
Faites un clic droit sur Éditeur base de données (AdventureWorks ) > Propriétés > Fichiers . Assurez-vous que le Propriétaire le champ est défini sur sa ou tout identifiant valide et non vide .
Si des problèmes d'autorisation surviennent lorsque nous nous connectons à la base de données de l'éditeur ou de la distribution, vérifiez les informations d'identification utilisées pour l'agent de lecture du journal et accordez-leur les autorisations d'accès à ces bases de données.
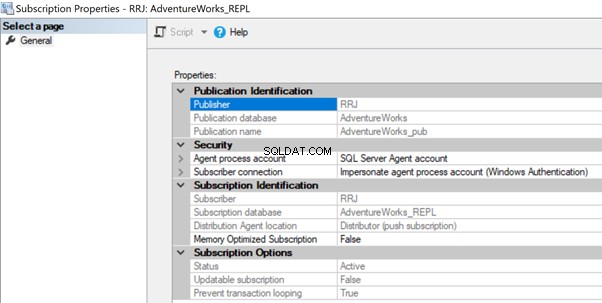
Les informations d'identification du poste d'agent de distribution ne peuvent pas se connecter à la base de données de distribution/d'abonnés
L'agent de distribution peut rencontrer des problèmes d'autorisation si le compte n'est pas autorisé à accéder à la base de données de distribution ou à se connecter à la base de données des abonnés. Dans ce cas, nous pouvons obtenir les erreurs suivantes :
Impossible de démarrer l'exécution de l'étape 2 (raison :erreur d'authentification du proxy RRJ\RRJ, erreur système :le nom d'utilisateur ou le mot de passe est incorrect.)
Le processus n'a pas pu se connecter à l'abonné 'RRJ.
Échec de la connexion pour l'utilisateur 'RRJ\RRJ'.
Pour le résoudre, vérifiez le compte utilisé dans les propriétés d'abonnement et assurez-vous qu'il dispose des autorisations nécessaires pour se connecter à la base de données de distribution ou d'abonné.
Problèmes de connectivité
Nous configurons généralement la réplication transactionnelle sur des serveurs au sein du même réseau ou sur des emplacements géographiquement distribués. Si la base de données de distribution est située sur un serveur dédié en dehors de l'éditeur ou de l'abonné, elle devient sensible aux pertes de paquets réseau - problèmes de connectivité.
En cas de tels problèmes, les agents de réplication (lecteur de journal ou agent de distribution) peuvent signaler les erreurs ci-dessous :
Le serveur de l'éditeur est introuvable ou n'est pas accessible
Le serveur de distribution n'a pas été trouvé ou n'était pas accessible
Le serveur d'abonné n'a pas été trouvé ou n'était pas accessible
Pour résoudre ces problèmes, nous pouvons essayer de nous connecter à la base de données de l'éditeur, du distributeur ou de l'abonné dans SSMS pour vérifier si nous sommes en mesure de nous connecter à ces instances SQL Server sans aucun problème ou non.
Si des problèmes de connectivité se produisent fréquemment, nous pouvons essayer d'envoyer un ping au serveur en continu pour identifier toute perte de paquets. De plus, nous devons travailler avec les membres de l'équipe nécessaires pour résoudre ces problèmes et faire en sorte que le serveur soit opérationnel pour que la réplication reprenne le transfert de données.
Problèmes d'intégrité des données
Étant donné que la réplication transactionnelle est un mécanisme à sens unique, toute modification de données qui se produit sur l'abonné (manuellement ou à partir de l'application) ne sera pas répercutée sur l'éditeur. Cela peut entraîner des écarts de données entre l'éditeur et l'abonné.
Passons en revue ces problèmes liés à l'intégrité des données et voyons comment les résoudre. Notez que nous avons inséré un enregistrement dans le Person.ContactType table et supprimé 2 enregistrements de Person.ContactType table dans la base de données des abonnés. Nous allons utiliser ces 3 enregistrements pour trouver les erreurs.
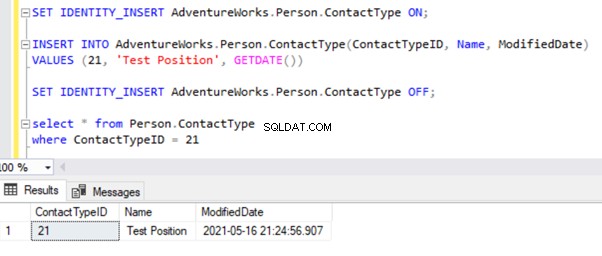
Erreurs de violation de clé primaire ou de clé unique
Je vais tester l'enregistrement INSERT sur le Person.ContactType table. Insérons cet enregistrement dans la base de données de l'éditeur et voyons ce qui se passe :
Lancez le moniteur de réplication pour voir comment cela se passe. Nous obtenons l'erreur :
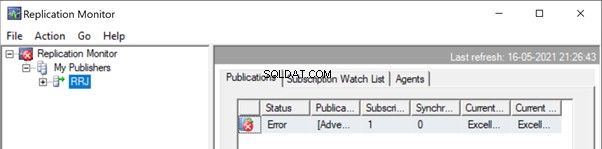
Extension de l'éditeur et Publication , nous obtenons les détails suivants :
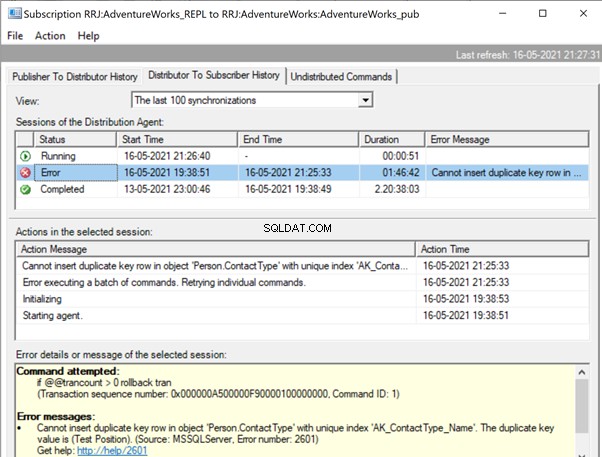
Si nous avons configuré les alertes de réplication et affecté les personnes respectives à recevoir leur alerte par e-mail, nous recevrons les notifications par e-mail appropriées avec le message d'erreur :Impossible d'insérer une ligne de clé en double dans l'objet 'Person.ContactType' avec l'index unique 'AK_ContactType_Name ' . La valeur de la clé en double est (Test Position). (Source :MSSQLServer, numéro d'erreur :2601)
Pour résoudre le problème concernant les violations de clé unique ou les problèmes de clé primaire, nous avons plusieurs options :
- Analysez pourquoi cette erreur s'est produite, comment l'enregistrement était disponible dans la base de données des abonnés et qui l'a inséré pour quelles raisons. Identifiez si cela était nécessaire ou non.
- Ajouter les skiperrors paramètre au profil de l'agent de distribution pour ignorer l'erreur numéro 2601 ou Erreur numéro 2627 en cas de violation de la clé primaire.
Dans notre cas, nous avons délibérément inséré des données pour recevoir cette erreur. Pour résoudre ce problème, supprimez cet enregistrement inséré manuellement pour continuer à répliquer les modifications reçues de l'éditeur.
DELETE from Person.ContactType
where ContactTypeID = 21
Pour étudier d'autres options et comparer les différences entre ces deux approches, je saute la première option (qui est efficace et recommandée) et passe à la deuxième option en ajoutant les -skiperrors paramètre au travail de l'Agent de distribution.
Nous pouvons l'implémenter en modifiant le travail d'agent de distribution > Étapes > cliquez sur 2 étape de tâche nommée Exécuter l'agent > cliquez sur Modifier pour voir la commande disponible :
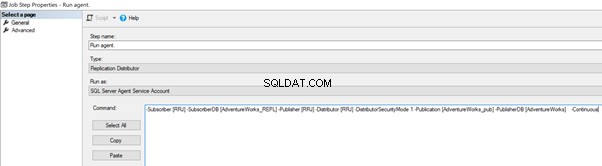
Maintenant, ajoutez le -SkipErrors 2601 mot-clé à la fin (2601 est le numéro d'erreur - nous pouvons ignorer tout numéro d'erreur reçu dans le cadre de la réplication) et cliquez sur OK .
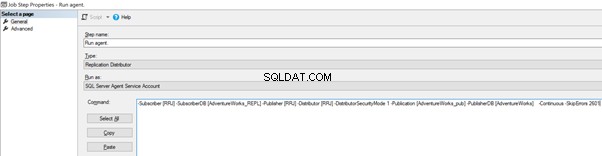
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
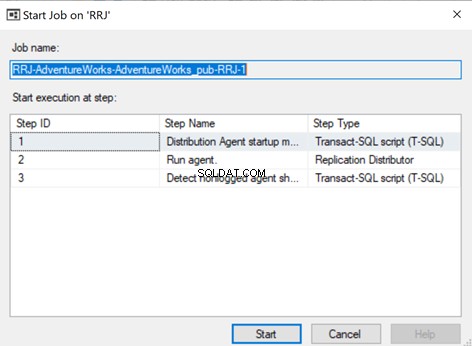
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
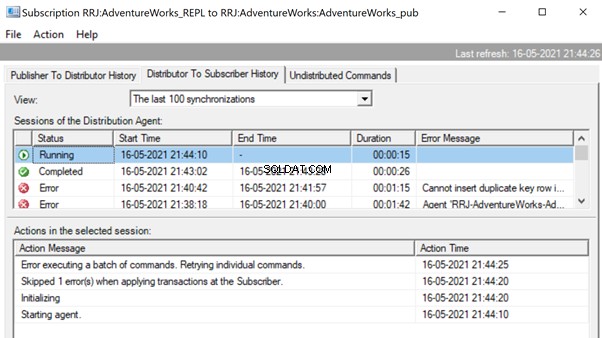
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
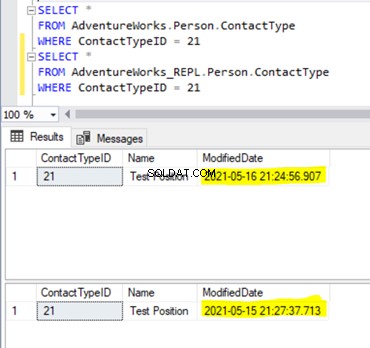
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors commande.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
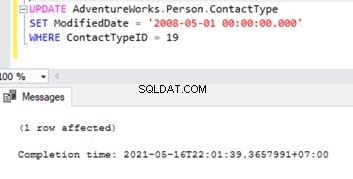
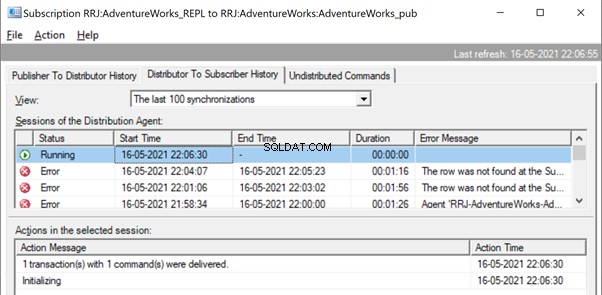
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
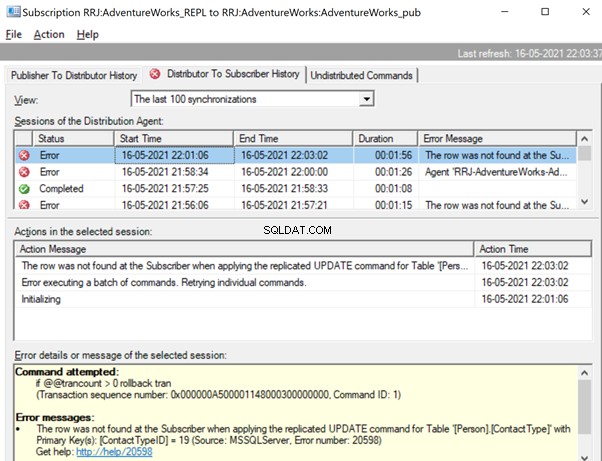
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors option. Instead, we’ll apply the INSERT approach.
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
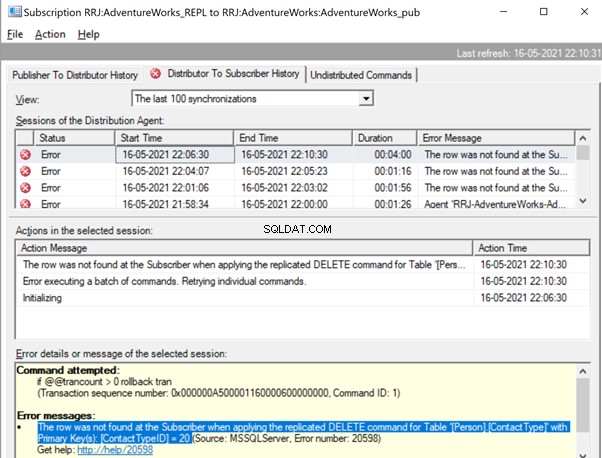
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Conclusion
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.



