Nous avons commencé à parler des problèmes de réplication transactionnelle de SQL Server plus tôt. Maintenant, nous allons continuer avec quelques démonstrations pratiques supplémentaires pour comprendre les problèmes de performances de réplication fréquemment rencontrés et comment les résoudre correctement.
Nous avons déjà discuté de problèmes tels que les problèmes de configuration, les problèmes d'autorisation, les problèmes de connectivité et les problèmes d'intégrité des données, ainsi que leur dépannage et leur résolution. Maintenant, nous allons nous concentrer sur divers problèmes de performances et de corruption ayant un impact sur la réplication SQL Server.
Étant donné que les problèmes de corruption sont un sujet énorme, nous discuterons de leur impact dans cet article uniquement et n'entrerons pas dans les détails. D'après mon expérience, j'ai sélectionné plusieurs scénarios pouvant relever de problèmes de performances et de corruption :
- Problèmes de performances
- Transactions actives de longue durée dans la base de données de l'éditeur
- Opérations INSERT/UPDATE/DELETE en masse sur les articles
- Modifications considérables des données en une seule transaction
- Blocages dans la base de données de distribution
- Problèmes liés à la corruption
- Corruptions de la base de données de l'éditeur
- Corruptions de la base de données de distribution
- Corruptions de la base de données des abonnés
- Corruptions de la base de données MSDB
Problèmes de performances
La réplication transactionnelle SQL Server est une architecture compliquée qui implique plusieurs paramètres tels que la base de données de l'éditeur, la base de données du distributeur (distribution), la base de données de l'abonné et plusieurs agents de réplication s'exécutant en tant que travaux de l'agent SQL Server.
Comme nous avons discuté de tous ces éléments en détail dans nos articles précédents, nous connaissons l'importance de chacun pour la fonctionnalité de réplication. Tout ce qui a un impact sur ces composants peut affecter les performances de la réplication SQL Server.
Par exemple, l'instance de base de données Publisher contient une base de données critique avec un grand nombre de transactions par seconde. Cependant, les ressources du serveur présentent un goulot d'étranglement tel que l'utilisation constante du processeur au-dessus de 90 % ou l'utilisation de la mémoire au-dessus de 90 %. Cela aura certainement un impact sur les performances du travail de l'agent de lecture du journal qui lit les données modifiées à partir des journaux transactionnels de la base de données de l'éditeur.
De même, de tels scénarios dans les instances de base de données de distributeur ou d'abonné peuvent avoir un impact sur l'agent de capture instantanée ou l'agent de distribution. Ainsi, en tant qu'administrateur de bases de données, vous devez vous assurer que les ressources du serveur telles que le processeur, la mémoire physique et la bande passante réseau sont configurées efficacement pour les instances de base de données de l'éditeur, du distributeur et de l'abonné.
En supposant que les serveurs de base de données de l'éditeur, de l'abonné et du distributeur sont configurés correctement, nous pouvons toujours avoir des problèmes de performances de réplication lorsque nous rencontrons les scénarios ci-dessous.
Transactions actives de longue durée dans la base de données de l'éditeur
Comme son nom l'indique, les transactions actives de longue durée indiquent qu'un appel d'application ou une opération utilisateur dans la portée de la transaction s'exécute depuis longtemps.
La recherche d'une transaction active de longue durée signifie que la transaction n'est pas encore validée et peut être annulée ou validée par l'application. Cela empêchera le journal des transactions d'être tronqué, ce qui entraînera une augmentation continue de la taille du fichier du journal des transactions.
L'agent de lecture du journal recherche tous les enregistrements validés qui sont marqués pour la réplication à partir des journaux transactionnels dans un ordre sérialisé basé sur le numéro de séquence du journal (LSN), en ignorant toutes les autres modifications apportées aux articles qui ne sont pas répliqués. Si les commandes de transaction active de longue durée ne sont pas encore validées, la réplication ignorera l'envoi de ces commandes et enverra toutes les autres transactions validées à la base de données de distribution. Une fois la transaction active de longue durée validée, les enregistrements seront envoyés à la base de données de distribution et jusque-là, la partie inactive du fichier journal des transactions de la base de données de l'éditeur ne sera pas effacée, ce qui entraînera une augmentation de la taille du fichier journal des transactions de la base de données de l'éditeur.
Nous pouvons tester le scénario Transaction active de longue durée en procédant comme suit :
Par défaut, l'agent de distribution nettoie toutes les modifications validées dans la base de données de l'abonné, en conservant le dernier enregistrement pour surveiller les nouvelles modifications en fonction du numéro de séquence du journal (LSN).
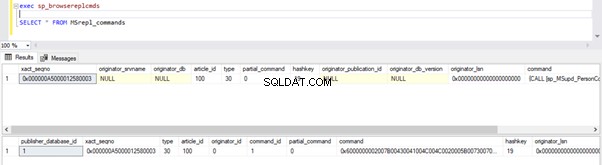
Nous pouvons exécuter les requêtes ci-dessous pour vérifier l'état des enregistrements disponibles dans MSRepl_Commands tables ou en utilisant sp_browsereplcmds procédure dans la base de données de distribution :
exec sp_browsereplcmds
GO
SELECT * FROM MSrepl_commands
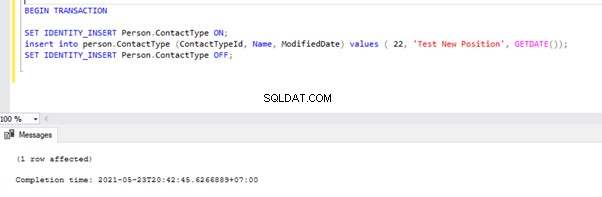
Maintenant, ouvrez une nouvelle fenêtre de requête et exécutez le script ci-dessous pour créer une transaction active de longue durée sur AdventureWorks base de données. Notez que le script ci-dessous n'inclut aucune commande ROLLBACK ou COMMIT TRANSACTION. Par conséquent, nous vous conseillons de ne pas exécuter ce type de commandes sur la base de données de production.
BEGIN TRANSACTION
SET IDENTITY_INSERT Person.ContactType ON;
insert into person.ContactType (ContactTypeId, Name, ModifiedDate) values ( 22, 'Test New Position', GETDATE());
SET IDENTITY_INSERT Person.ContactType OFF;
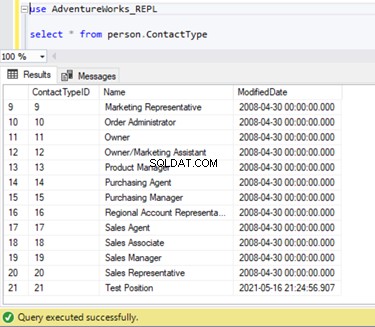
Nous pouvons vérifier que ce nouvel enregistrement n'a pas été répliqué dans la base de données de l'abonné. Pour cela, nous allons effectuer l'instruction SELECT sur le Person.ContactType table dans la base de données des abonnés :
Vérifions si la commande INSERT ci-dessus a été lue par l'agent de lecture du journal et écrite dans la base de données de distribution.
Exécutez à nouveau les scripts de la partie de l'étape 1. Les résultats affichent toujours le même ancien statut, confirmant que l'enregistrement n'a pas été lu à partir des journaux de transactions de la base de données de l'éditeur.
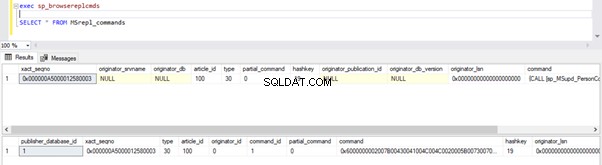
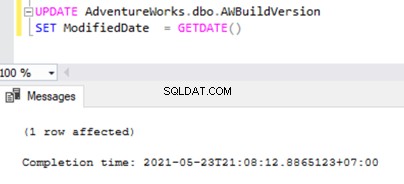
Ouvrez maintenant une Nouvelle requête fenêtre et exécutez le script UPDATE ci-dessous pour voir si l'Agent de lecture du journal a pu ignorer la transaction active de longue durée et lire les modifications apportées par cette instruction UPDATE.
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
Vérifiez la base de données de distribution si l'agent de lecture du journal peut capturer cette modification. Exécutez le script dans le cadre de l'étape 1 :
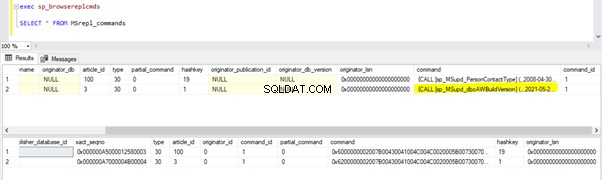
Étant donné que l'instruction UPDATE ci-dessus a été validée dans la base de données de l'éditeur, l'agent de lecture du journal peut analyser cette modification et l'insérer dans la base de données de distribution. Par la suite, il a appliqué cette modification à la base de données des abonnés comme indiqué ci-dessous :
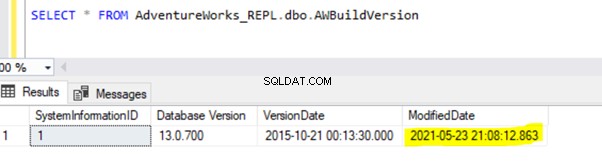
INSÉRER sur Person.ContactType sera répliqué dans la base de données de l'abonné uniquement après la validation de la transaction INSERT dans la base de données de l'éditeur. Avant de nous engager, nous pouvons vérifier rapidement comment identifier une transaction active de longue durée, la comprendre et la gérer efficacement.
Identifier une transaction active de longue durée
Pour vérifier les transactions actives de longue durée sur n'importe quelle base de données, ouvrez une nouvelle fenêtre de requête et connectez-vous à la base de données respective que nous devons vérifier. Exécutez le DBCC OPENTRAN commande console - il s'agit d'une commande de console de base de données pour afficher les transactions ouvertes dans la base de données au moment de l'exécution.
USE AdventureWorks
GO
DBCC OPENTRAN
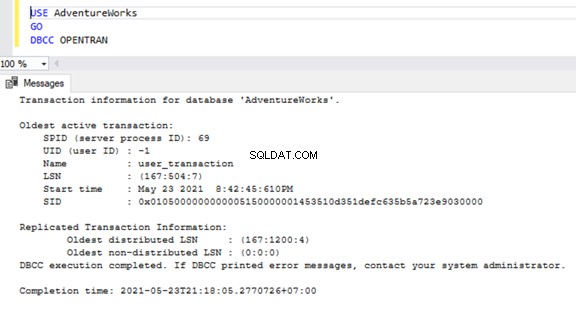
Nous savons maintenant qu'il y avait un SPID (ID de processus serveur ) 69 en cours d'exécution depuis longtemps. Vérifions quelle commande a été exécutée sur cette transaction à l'aide de DBCC INPUTBUFFER commande console (une commande de console de base de données utilisée pour identifier la commande ou l'opération qui se produit sur l'ID de processus serveur sélectionné).
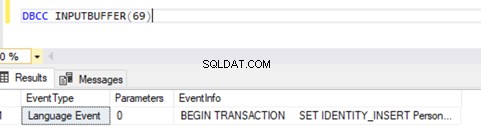
Pour plus de lisibilité, je copie EventInfo valeur du champ et le formater pour afficher la commande que nous avons exécutée précédemment.
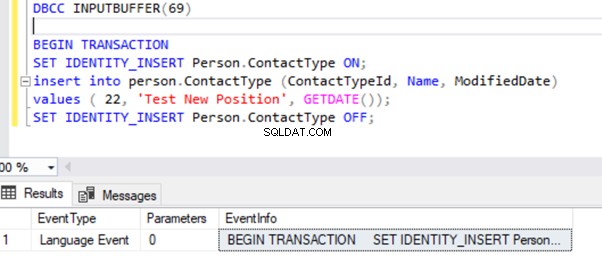
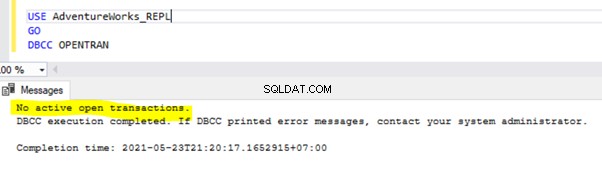
S'il n'y a pas de transactions actives de longue durée sur la base de données sélectionnée, nous recevrons le message ci-dessous :
Similaire au DBCC OPENTRAN commande console, nous pouvons SELECT de DMV nommé sys.dm_tran_database_transactions pour obtenir des résultats plus détaillés (reportez-vous à l'article MSDN pour plus de données).
Maintenant, nous savons comment identifier la transaction de longue durée. Nous pouvons valider la transaction et voir comment l'instruction INSERT est répliquée.
Allez à la fenêtre où nous avons inséré l'enregistrement au Person.ContactType table dans la portée de la transaction et exécutez COMMIT TRANSACTION comme indiqué ci-dessous :
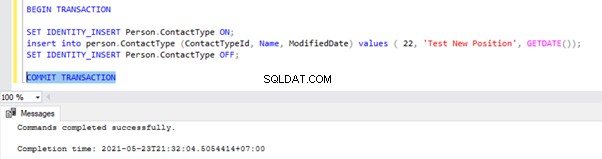
L'exécution de COMMIT TRANSACTION a validé l'enregistrement dans la base de données de l'éditeur. Par conséquent, il doit être visible dans la base de données de distribution et la base de données des abonnés :
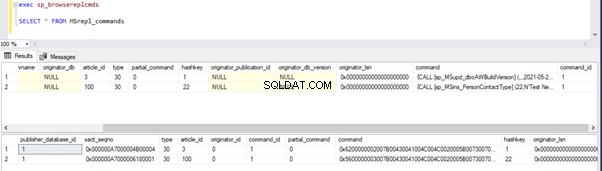
Si vous avez remarqué, les anciens enregistrements de la base de données de distribution ont été nettoyés par le travail de nettoyage de l'agent de distribution. Le nouvel enregistrement pour INSERT sur Person.ContactType la table était visible dans MSRepl_cmds tableau.
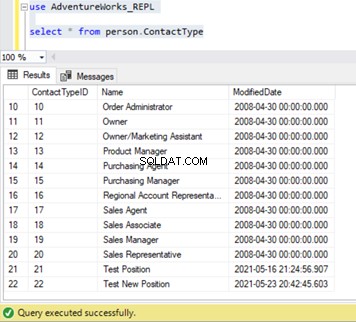
De nos tests, nous avons appris les choses suivantes :
- Le travail de l'agent de lecture du journal de la réplication transactionnelle SQL Server recherchera uniquement les enregistrements validés à partir des journaux transactionnels de la base de données de l'éditeur et INSERT dans la base de données de l'abonné.
- L'ordre des données modifiées sur la base de données de l'éditeur envoyées à l'abonné sera basé sur le statut et l'heure validés sur la base de données de l'éditeur, même si les données répliquées auront la même heure que la base de données de l'éditeur.
- L'identification des transactions actives de longue durée peut aider à résoudre la croissance du fichier journal des transactions de l'éditeur, du distributeur, de l'abonné ou de toute base de données.
Opérations SQL INSERT/UPDATE/DELETE en masse sur les articles
Avec d'énormes données résidant dans la base de données de l'éditeur, nous nous retrouvons souvent avec des exigences d'INSERER, de METTRE À JOUR ou de SUPPRIMER d'énormes enregistrements dans des tables répliquées.
Si les opérations INSERT, UPDATE ou DELETE sont effectuées dans une seule transaction, cela finira certainement dans la réplication bloquée pendant longtemps.
Disons que nous devons INSÉRER 10 millions d'enregistrements dans une table répliquée. L'insertion de ces enregistrements en une seule fois entraînera des problèmes de performances.
INSERT INTO REplicated_table
SELECT * FROM Source_table
Au lieu de cela, nous pouvons INSÉRER des enregistrements par lots de 0,1 ou 0,5 million d'enregistrements dans un PENDANT boucle ou boucle CURSOR , et cela assurera une réplication plus rapide. Nous ne recevrons peut-être pas de problèmes majeurs pour les instructions INSERT, sauf si la table impliquée contient de nombreux index. Cependant, cela aura un énorme impact sur les performances des instructions UPDATE ou DELETE.
Supposons que nous ayons ajouté une nouvelle colonne à la table répliquée contenant environ 10 millions d'enregistrements. Nous voulons mettre à jour cette nouvelle colonne avec une valeur par défaut.
Idéalement, la commande ci-dessous fonctionnera correctement pour METTRE À JOUR les 10 millions d'enregistrements avec la valeur par défaut Abc :
-- UPDATE 10 Million records on Replicated Table with some DEFAULT values
UPDATE Replicated_table
SET new_column = 'Abc'
Cependant, pour éviter les impacts sur la réplication, nous devons exécuter l'opération UPDATE ci-dessus par lots de 0,1 ou 0,5 million d'enregistrements pour éviter les problèmes de performances.
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
UPDATE TOP(100000) Replicated_Table
SET new_Column = 'Abc'
WHERE new_column is NULL
IF @@ROWCOUNT = 0
BREAK
END
De même, si nous devons SUPPRIMER environ 10 millions d'enregistrements d'une table répliquée, nous pouvons le faire par lots :
-- DELETE 10 Million records on Replicated Table with some DEFAULT values
DELETE FROM Replicated_table
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
DELETE TOP(100000) Replicated_Table
IF @@ROWCOUNT = 0
BREAK
END
La gestion efficace de BULK INSERT, UPDATE ou DELETE peut aider à résoudre les problèmes de réplication.
Conseil de pro :Pour INSÉRER des données volumineuses dans une table répliquée dans la base de données Publisher, utilisez l'assistant IMPORT/EXPORT dans SSMS, car il insérera des enregistrements par lots de 10 000 ou en fonction de la taille d'enregistrement plus rapidement calculée par SQL Server.
Énormes changements de données dans une seule transaction
Pour maintenir l'intégrité des données du point de vue de l'application ou du développement, de nombreuses applications ont des transactions explicites définies pour les opérations critiques. Cependant, si un grand nombre d'opérations (INSERT, UPDATE ou DELETE) s'exécutent dans une seule portée de transaction, l'agent de lecture du journal attendra d'abord que la transaction se termine, comme nous l'avons vu précédemment.
Une fois la transaction validée par l'application, l'agent de lecture du journal doit analyser ces énormes modifications de données effectuées sur les journaux de transactions de la base de données de l'éditeur. Au cours de cette analyse, nous pouvons voir les avertissements ou les messages d'information dans l'agent de lecture du journal comme
L'agent de lecture du journal analyse le journal des transactions à la recherche de commandes à répliquer. Environ xxxxxx enregistrements de journal ont été analysés au cours de la passe # xxxx dont ont été marqués pour la réplication, temps écoulé xxxxxxxxx (ms)
Avant d'identifier la solution pour ce scénario, nous devons comprendre comment l'agent de lecture du journal analyse les enregistrements des journaux transactionnels et insère des enregistrements dans la base de données de distribution MSrepl_transactions et MSrepl_cmds tableaux.
SQL Server possède en interne un numéro de séquence de journal (LSN) dans les journaux transactionnels. L'Agent de lecture du journal utilise les valeurs LSN pour analyser les modifications marquées pour la réplication SQL Server dans l'ordre.
L'agent de lecture du journal exécute le sp_replcmds procédure stockée étendue pour récupérer les commandes marquées pour la réplication à partir des journaux transactionnels de la base de données de l'éditeur.
Sp_replcmds accepte un paramètre d'entrée nommé @maxtrans pour récupérer le nombre maximum de transactions. La valeur par défaut serait 1, ce qui signifie qu'il analysera le nombre de transactions disponibles dans les journaux à envoyer à la base de données de distribution. S'il y a 10 opérations INSERT effectuées via une seule transaction et validées dans la base de données de l'éditeur, un seul lot peut contenir 1 transaction avec 10 commandes.
Si de nombreuses transactions avec des commandes inférieures sont identifiées, l'agent de lecture du journal combinera plusieurs transactions ou le XACT numéro de séquence à un seul lot de réplication. Mais il stocke comme un XACT différent Séquence numéro dans les MSRepl_transactions table. Les commandes individuelles appartenant à cette transaction seront capturées dans les MSRepl_commands tableau.
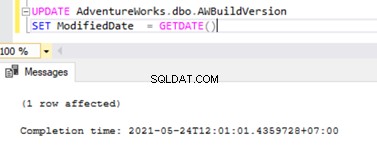
Pour vérifier les éléments dont nous avons discuté ci-dessus, je mets à jour la ModifiedDate colonne de dbo.AWBuildVersion tableau à la date d'aujourd'hui et voyez ce qui se passe :
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
Avant d'exécuter la MISE À JOUR, nous vérifions les enregistrements présents dans les MSrepl_commands et MSrepl_transactions tableaux :
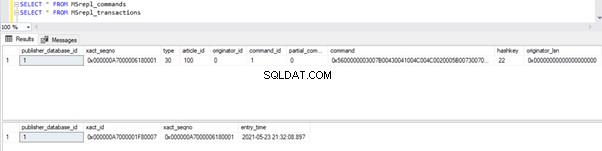
Maintenant, exécutez le script UPDATE ci-dessus et vérifiez les enregistrements présents dans ces 2 tables :
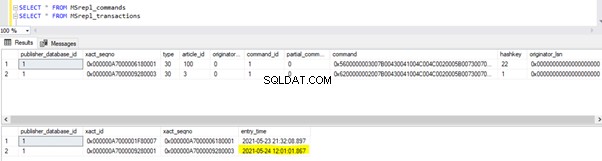
Un nouvel enregistrement avec l'heure UPDATE a été inséré dans le MSrepl_transactions table avec entry_time à proximité . Vérification de la commande sur ce xact_seqno affichera la liste des commandes groupées logiquement à l'aide de sp_browsereplcmds procédure.

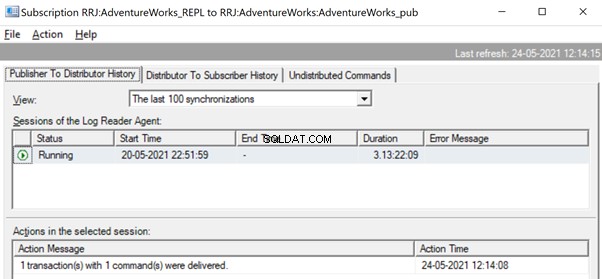
Dans le moniteur de réplication, nous pouvons voir une seule instruction UPDATE capturée sous 1 transaction(s) avec 1 commande(s) de l'éditeur au distributeur.
Et nous pouvons voir la même commande être livrée du distributeur à l'abonné en une fraction de seconde de différence. Cela indique que la réplication se déroule correctement.
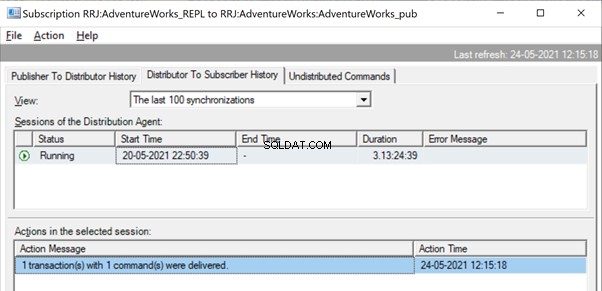
Maintenant, s'il y a un grand nombre de transactions combinées dans un seul xact_seqno , nous pouvons voir des messages comme 10 transaction(s) avec 5000 commande(s) ont été livrées .
Vérifions cela en exécutant UPDATE sur 2 tables différentes en même temps :
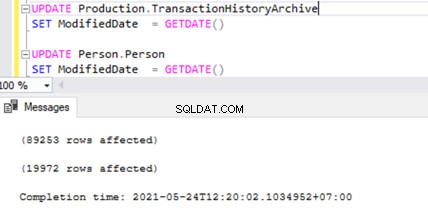
Nous pouvons voir deux enregistrements de transaction dans MSrepl_transactions table correspondant aux deux opérations UPDATE, puis le no. d'enregistrements dans cette table correspondant au no. d'enregistrements mis à jour.
Le résultat des MSrepl_transactions tableau :
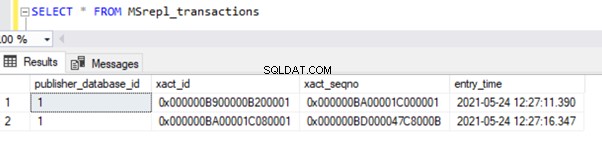
Le résultat des MSrepl_commands tableau :
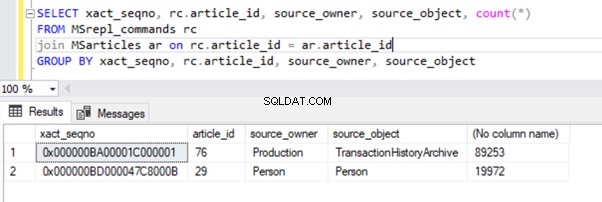
Cependant, nous avons remarqué que ces 2 transactions sont logiquement regroupées par l'agent de lecture du journal et combinées en un seul lot en 2 transactions avec 109225 commandes.
Mais avant cela, nous pourrions voir des messages comme Delivering Replicated transactions, xact count :1, command count 46601 .
Cela se produira jusqu'à ce que l'agent de lecture du journal analyse l'ensemble complet des modifications et identifie que 2 transactions UPDATE ont été entièrement lues à partir des journaux transactionnels.
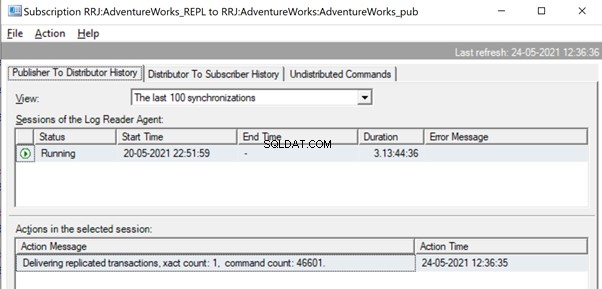
Une fois que les commandes sont entièrement lues à partir des journaux transactionnels, nous voyons que 2 transactions avec 109225 commandes ont été livrées par l'agent Log Reader :
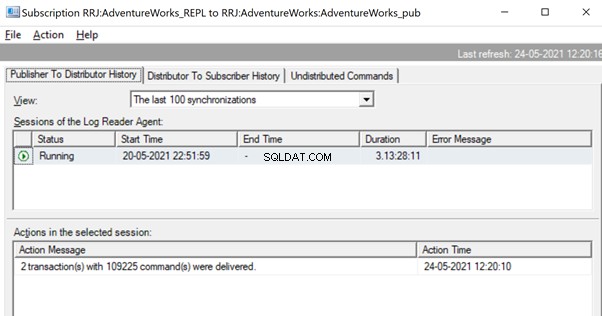
Étant donné que l'agent de distribution attend qu'une énorme transaction soit répliquée, nous pourrions voir un message comme Delivering Replicated transactions indiquant qu'une énorme transaction a été répliquée et que nous devons attendre qu'elle soit complètement répliquée.
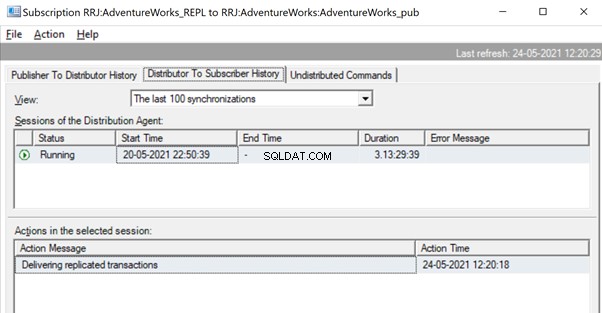
Une fois répliqué, nous pouvons également voir le message ci-dessous dans l'Agent de distribution :
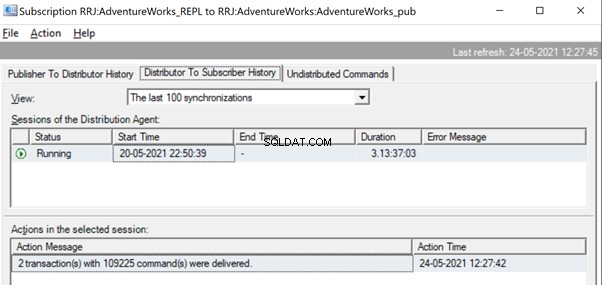
Plusieurs méthodes sont utiles pour résoudre ces problèmes.
Méthode 1 :CRÉER une nouvelle procédure stockée SQL
Vous devez créer une nouvelle procédure stockée et y encapsuler la logique d'application dans le cadre de Transaction.
Une fois créé, ajoutez cet article de procédure stockée à la réplication et modifiez la propriété de l'article Répliquer en Exécution de la procédure stockée option.
Cela aidera à exécuter l'article sur la procédure stockée sur l'abonné au lieu de répliquer toutes les modifications de données individuelles qui se produisaient.
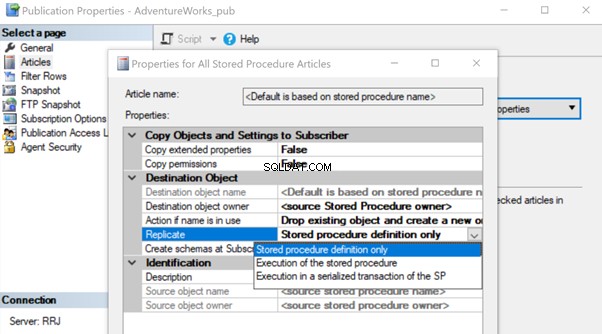
Voyons comment l'exécution de la procédure stockée L'option de réplication réduit la charge sur la réplication. Pour ce faire, nous pouvons créer une procédure stockée de test comme indiqué ci-dessous :
CREATE procedure test_proc
AS
BEGIN
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Production.TransactionHistoryArchive
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Person.Person
SET ModifiedDate = GETDATE()
END
La procédure ci-dessus mettra à jour un seul enregistrement sur AWBuildVersion table et 10 enregistrements chacun sur Production.TransactionHistoryArchive et Personne.Personne tableaux totalisant jusqu'à 21 changements d'enregistrements.
Après avoir créé cette nouvelle procédure sur l'éditeur et l'abonné, ajoutez-la à la réplication. Pour cela, faites un clic droit sur Publication et choisissez l'article de procédure à répliquer avec la définition de procédure stockée uniquement par défaut option.
Une fois cela fait, nous pouvons vérifier les enregistrements disponibles dans le MSrepl_transactions et MSrepl_commands tableaux.
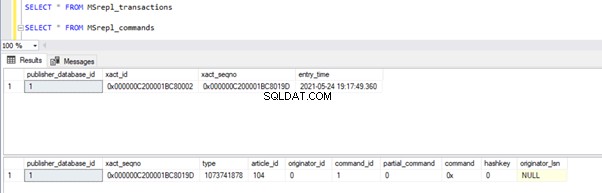
Maintenant, exécutons la procédure dans la base de données de l'éditeur pour voir combien d'enregistrements sont suivis.
Nous pouvons voir ce qui suit sur les tables de distribution MSrepl_transactions et MSrepl_commands :
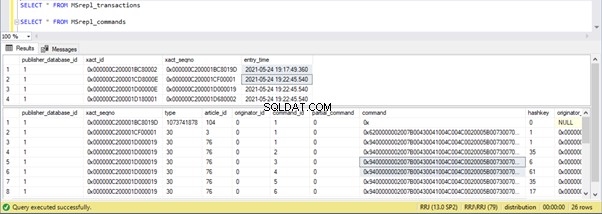
Trois xact_seqno ont été créés pour trois opérations UPDATE dans MSrepl_transactions table, et 21 commandes ont été insérées dans les MSrepl_commands tableau.
Ouvrez Replication Monitor et voyez s'ils sont envoyés sous forme de 3 lots de réplication différents ou d'un seul lot avec 3 transactions ensemble.
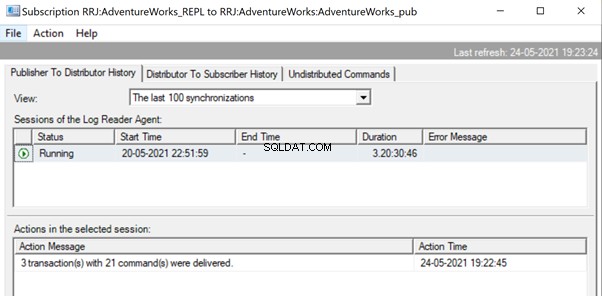
Nous pouvons voir que trois xact_seqno a été consolidé en un seul lot de réplication. Par conséquent, nous pouvons voir que 3 transactions avec 21 commandes ont été livrées avec succès.
Supprimons la procédure de la réplication et rajoutons-la avec la seconde Exécution de la procédure stockée option. Maintenant, exécutez la procédure et voyez comment les enregistrements sont répliqués.
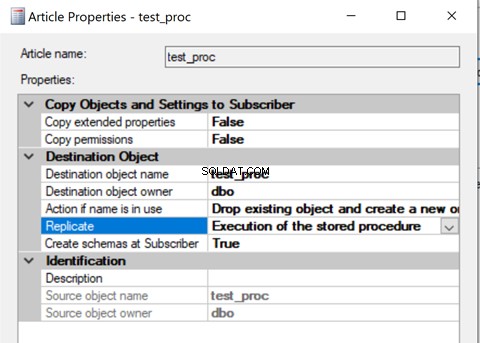
La vérification des enregistrements des tables de distribution affiche les détails ci-dessous :
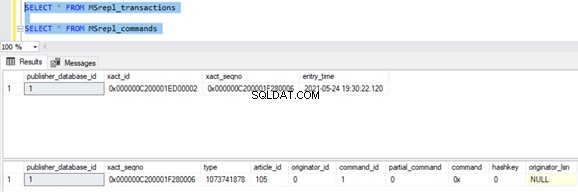
Maintenant, exécutez la procédure sur la base de données Publisher et voyez combien d'enregistrements sont enregistrés dans les tables de distribution. L'exécution d'une procédure a mis à jour 21 enregistrements (1 enregistrement, 10 enregistrements et 10 enregistrements) comme précédemment.
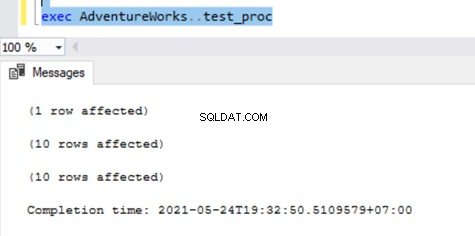
La vérification des tables de distribution affiche les données ci-dessous :
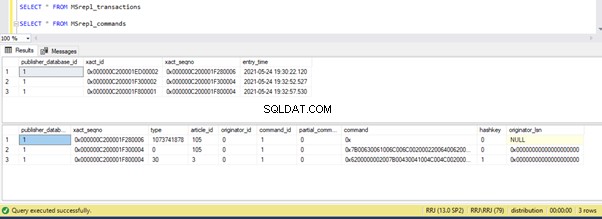
Jetons un coup d'œil à sp_browsereplcmds pour voir la commande réellement reçue :

La commande est "{call "dbo"."test_proc" }" qui sera exécuté sur la base de données des abonnés.
Dans le moniteur de réplication, nous pouvons voir que seulement 1 transaction(s) avec 1 commande(s) ont été livrées via la réplication :
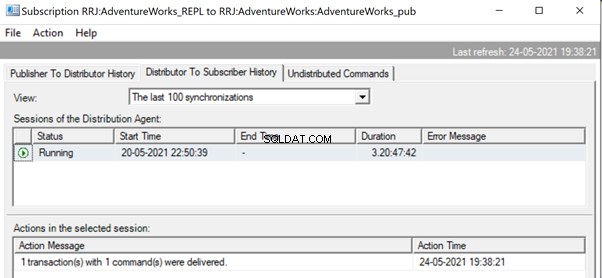
Dans notre cas de test, nous avons utilisé une procédure avec seulement 21 changements de données. Cependant, si nous faisons cela pour une procédure compliquée impliquant des millions de modifications, alors l'approche de la procédure stockée avec l'exécution de la procédure stockée sera efficace pour réduire la charge de réplication.
Nous devons valider cette approche en vérifiant si la procédure a la logique de mettre à jour uniquement le même ensemble d'enregistrements dans les bases de données de l'éditeur et de l'abonné. Sinon, cela créera des problèmes d'incohérence des données entre l'éditeur et l'abonné.
Méthode 2 :Configuration des paramètres de l'agent de lecture de journal MaxCmdsInTran, ReadBatchSize et ReadBatchThreshold
MaxCmdsInTran - indique le nombre maximum de commandes pouvant être regroupées de manière logique dans une transaction lors de la lecture des données des journaux transactionnels de la base de données de l'éditeur et écrites dans la base de données de distribution.
Lors de nos tests précédents, nous avons remarqué qu'environ 109 225 commandes s'accumulaient dans une seule séquence exacte de réplication, ce qui entraînait une légère lenteur ou latence. Si nous définissons le MaxCmdsInTran paramètre à 10000, la seule séquence xact le nombre sera divisé en 11 séquences xact entraînant une livraison plus rapide des commandes de l'éditeur au distributeur . Même si cette option permet de réduire la contention de la base de données de distribution et de répliquer plus rapidement les données de l'éditeur vers la base de données de l'abonné, soyez prudent lorsque vous utilisez cette option. Il peut finir par fournir les données à la base de données de l'abonné et y accéder à partir des tables de la base de données de l'abonné avant la fin de la portée de la transaction d'origine.
ReadBatchSize – Ce paramètre peut ne pas être utile pour un seul scénario de transaction énorme. Cependant, cela aide lorsqu'il y a beaucoup, beaucoup de petites transactions qui se produisent sur la base de données de l'éditeur.
Si le nombre de commandes par transaction est inférieur, l'Agent de lecture du journal combinera plusieurs modifications en une seule étendue de transaction de commande de réplication. La taille du lot de lecture indique le nombre de transactions pouvant être lues dans le journal des transactions avant d'envoyer les modifications à la base de données de distribution. Les valeurs peuvent être comprises entre 500 et 10 000.
ReadBatchThreshold – indique le nombre de commandes à lire dans le journal transactionnel de la base de données de l'éditeur avant d'être envoyées à l'Abonné avec une valeur par défaut de 0 pour scanner le fichier journal complet. Cependant, nous pouvons réduire cette valeur pour envoyer des données plus rapidement en la limitant à 10000 ou 100000 commandes comme ça.
Méthode 3 :Configurer les meilleures valeurs pour le paramètre SubscriptionStreams
Flux d'abonnement – indique le nombre de connexions qu'un agent de distribution peut exécuter en parallèle pour extraire des données de la base de données de distribution et les propager à la base de données de l'abonné. La valeur par défaut est 1 suggérant un seul flux ou une seule connexion de la distribution à la base de données des abonnés. Les valeurs peuvent être comprises entre 1 et 64. Si d'autres flux d'abonnement sont ajoutés, cela peut entraîner une congestion CXPACKET (autrement dit, le parallélisme). Par conséquent, vous devez faire attention lors de la configuration de cette option en production.
Pour résumer, essayez d'éviter les énormes INSERT, UPDATE ou DELETE en une seule transaction. S'il est impossible d'éliminer ces opérations, la meilleure option serait de tester les méthodes ci-dessus et de choisir celle qui convient le mieux à vos conditions spécifiques.
Blocages dans la base de données de distribution
La base de données de distribution est le cœur de la réplication transactionnelle SQL Server et si elle n'est pas maintenue correctement, il y aura de nombreux problèmes de performances.
Pour résumer toutes les pratiques recommandées pour la configuration de la base de données de distribution, nous devons nous assurer que les configurations ci-dessous sont effectuées correctement :
- Les fichiers de données des bases de données de distribution doivent être placés sur des disques à IOPS élevés. Si la base de données de l'éditeur comporte de nombreuses modifications de données, nous devons nous assurer que la base de données de distribution est placée sur un lecteur avec un IOPS élevé. Il recevra en permanence des données de l'agent Log Reader, en envoyant des données à la base de données de l'abonné via l'agent de distribution. Toutes les données répliquées seront purgées de la base de données de distribution toutes les 10 minutes via la tâche de nettoyage de distribution.
- Configurez la taille initiale du fichier et les propriétés de croissance automatique de la base de données de distribution avec les valeurs recommandées en fonction des niveaux d'activité de la base de données de l'éditeur. Sinon, cela entraînera une fragmentation des données et des fichiers journaux entraînant des problèmes de performances.
- Inclure les bases de données de distribution dans les tâches de maintenance d'index régulières configurées sur les serveurs sur lesquels se trouve la base de données de distribution.
- Incluez les bases de données de distribution dans la planification des tâches de sauvegarde complète pour résoudre tout problème spécifique.
- Assurez-vous que le nettoyage de la distribution :distribution le travail s'exécute toutes les 10 minutes selon la planification par défaut. Sinon, la taille de la base de données de distribution ne cesse d'augmenter et entraîne des problèmes de performances.
Comme nous l'avons remarqué jusqu'à présent, dans la base de données de distribution, les tables clés impliquées sont MSrepl_transactions et MSrepl_commands . Les enregistrements y sont insérés par le travail de l'agent de lecture du journal, sélectionnés par le travail de l'agent de distribution, appliqués à la base de données de l'abonné, puis supprimés ou nettoyés par le travail de l'agent de nettoyage de la distribution.
Si la base de données de distribution n'est pas configurée correctement, nous pouvons rencontrer des blocages de session sur ces 2 tables, ce qui entraînera des problèmes de performances de réplication SQL Server.
Nous pouvons exécuter la requête ci-dessous sur n'importe quelle base de données pour afficher les sessions de blocage disponibles dans l'instance actuelle de SQL Server :
SELECT *
FROM sys.sysprocesses
where blocked > 0
order by waittime desc
Si la requête ci-dessus renvoie des résultats, nous pouvons identifier les commandes sur ces sessions bloquées en exécutant le DBCC INPUTBUFFER(spid) commande de la console et prendre des mesures en conséquence.
Problèmes liés à la corruption
Une base de données SQL Server utilise son algorithme ou sa logique pour stocker des données dans des tables et les conserver dans des étendues ou des pages. La corruption de la base de données est un processus par lequel l'état physique des fichiers/extensions/pages liés à la base de données passe de l'état normal à l'état instable ou de non-récupération, ce qui rend la récupération des données plus difficile ou impossible.
Toutes les bases de données SQL Server sont sujettes aux corruptions de base de données. Les causes peuvent être :
- Défaillances matérielles telles que des problèmes de disque, de stockage ou de contrôleur ;
- Défaillances du système d'exploitation du serveur, telles que les problèmes de correctifs ;
- Pannes de courant entraînant un arrêt brutal des serveurs ou un arrêt incorrect de la base de données.
Si nous pouvons récupérer ou réparer des bases de données sans aucune perte de données, la réplication SQL Server ne sera pas affectée. Cependant, s'il y a des pertes de données lors de la récupération ou de la réparation de bases de données corrompues, nous commencerons à recevoir de nombreux problèmes d'intégrité des données dont nous avons discuté dans notre article précédent.
Les corruptions peuvent se produire au niveau de divers composants, tels que :
- Corruptions des données de l'éditeur/du fichier journal
- Corruption des données d'abonné/du fichier journal
- Corruptions des données/fichiers journaux de la base de données de distribution
- Corruptions des données/fichiers journaux de la base de données Msdb
If we receive a lot of data integrity issues after fixing up Corruption issues, it is recommended to remove the Replication completely, fix all Corruption issues in the Publisher, Subscriber, or Distributor database and then reconfigure Replication to fix it. Otherwise, data integrity issues will persist and lead to data inconsistency across the Publisher and Subscriber. The time required to fix the Data integrity issues in case of Corrupted databases will be much more compared to configuring Replication from scratch. Hence identify the level of Corruption encountered and take optimal decisions to resolve the Replication issues faster.
Wondering why msdb database corruption can harm Replication? Since msdb database hold all details related to SQL Server Agent Jobs including Replication Agent jobs, any corruption on msdb database will harm Replication. To recover quickly from msdb database corruptions, it is recommended to restore msdb database from the last Full Backup of msdb database. This also signifies the importance of taking Full Backups of all system databases including msdb database.
Conclusion
Thanks for successfully going through the final power-packed article about the Performance issues in the SQL Server Transactional Replication. If you have gone through all articles carefully, you should be able to troubleshoot almost any Transactional Replication-based issues and fix them out efficiently.
If you need any further guidance or have any Transactional Replication-related issues in your environment, you can reach out to me for consultation. And if I missed anything essential in this article, you are welcome to point to that in the Comments section.