Les bases de données relationnelles représentent les données d'une organisation dans des tables qui utilisent des colonnes avec différents types de données leur permettant de stocker des valeurs valides. Les développeurs et les administrateurs de bases de données doivent connaître et comprendre le type de données approprié pour chaque colonne afin d'améliorer les performances des requêtes.
Cet article traitera des types de données populaires VARCHAR() et NVARCHAR(), de leur comparaison et des évaluations des performances dans SQL Server.
VARCHAR [ ( n | max ) ] en SQL
Le VARCHAR le type de données représente le non-Unicode type de données chaîne de longueur variable. Vous pouvez y stocker des lettres, des chiffres et des caractères spéciaux.
- N représente la taille de la chaîne en octets.
- La colonne de type de données VARCHAR stocke un maximum de 8 000 caractères non Unicode.
- Le type de données VARCHAR prend 1 octet par caractère. Si vous ne spécifiez pas explicitement la valeur de N, cela prend un stockage de 1 octet.
Remarque :Ne confondez pas N avec une valeur représentant le nombre de caractères dans une chaîne.
La requête suivante définit le type de données VARCHAR avec 100 octets de données.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Il renvoie la longueur sous la forme 17 en raison de 1 octet par caractère, y compris un espace.
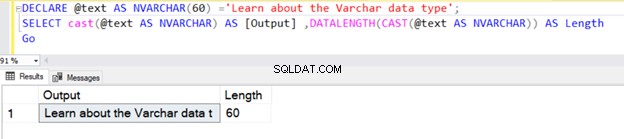
La requête suivante définit le type de données VARCHAR sans aucune valeur de N . Par conséquent, SQL Server considère la valeur par défaut comme 1 octet, comme indiqué ci-dessous.
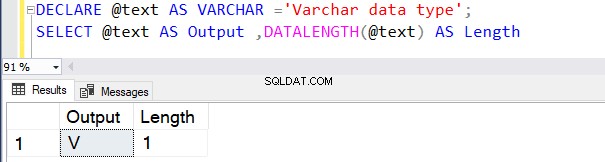
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
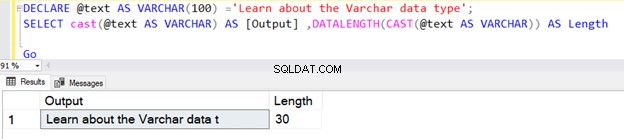
Nous pouvons également utiliser VARCHAR en utilisant la fonction CAST ou CONVERT. Par exemple, dans les deux exemples ci-dessous, nous avons déclaré une variable d'une longueur de 100 octets et avons ensuite utilisé l'opérateur CAST.
La première requête renvoie la longueur sous la forme 30, car nous n'avons pas spécifié N dans le type de données VARCHAR de l'opérateur CAST. La longueur par défaut est 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
Cependant, si la longueur de la chaîne est inférieure à 30, il prend la taille réelle de la chaîne.

NVARCHAR [ ( n | max ) ] en SQL
Le NVARCHAR le type de données est pour Unicode type de données caractère de longueur variable. Ici, N fait référence au jeu de caractères de la langue nationale et est utilisé pour définir la chaîne Unicode. Vous pouvez stocker à la fois des caractères non Unicode et Unicode (Kanji japonais, Hangul coréen, etc.).
- N représente la taille de la chaîne en octets.
- Il peut stocker un maximum de 4 000 caractères Unicode et non-Unicode.
- Le type de données VARCHAR prend 2 octets par caractère. Il prend 2 octets de stockage si vous ne spécifiez aucune valeur pour N.
La requête suivante définit le type de données VARCHAR avec 100 octets de données.
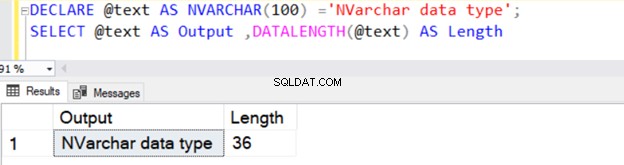
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Il renvoie la longueur de chaîne de 36 car NVARCHAR prend 2 octets par stockage de caractères.
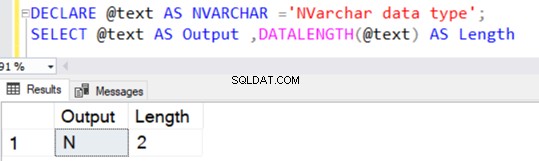
Semblable au type de données VARCHAR, NVARCHAR a également une valeur par défaut de 1 caractère (2 octets) sans spécifier de valeur explicite pour N.
Si nous appliquons la conversion NVARCHAR à l'aide de la fonction CAST ou CONVERT sans aucune valeur explicite de N, la valeur par défaut est de 30 caractères, soit 60 octets.
Stocker les valeurs Unicode et non Unicode dans le type de données VARCHAR
Supposons que nous disposions d'un tableau qui enregistre les commentaires des clients d'un portail d'achat en ligne. A cet effet, nous avons une table SQL avec la requête suivante.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
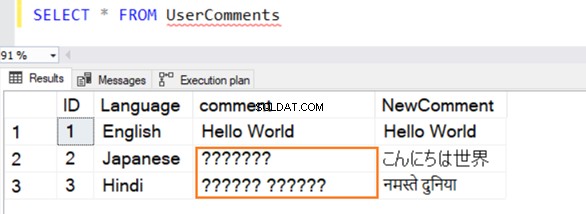
Nous insérons plusieurs exemples d'enregistrements dans cette table en anglais, japonais et hindi. Le type de données pour [Commentaire] est VARCHAR et [NouveauCommentaire] est NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
La requête s'exécute avec succès et donne les lignes suivantes lors de la sélection d'une valeur. Pour les lignes 2 et 3, il ne reconnaît pas les données si elles ne sont pas en anglais.
Types de données VARCHAR et NVARCHAR :comparaison des performances
Nous ne devons pas mélanger l'utilisation des types de données VARCHAR et NVARCHAR dans les prédicats JOIN ou WHERE. Il invalide les index existants car SQL Server requiert les mêmes types de données des deux côtés de JOIN. SQL Server essaie d'effectuer la conversion implicite à l'aide de la fonction CONVERT_IMPLICIT() en cas de non-concordance.
SQL Server utilise la priorité des types de données pour déterminer quel est le type de données cible. NVARCHAR a une priorité plus élevée que le type de données VARCHAR. Par conséquent, lors de la conversion du type de données, SQL Server convertit les valeurs VARCHAR existantes en NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Maintenant, exécutons deux instructions SELECT qui récupèrent les enregistrements selon leurs types de données.
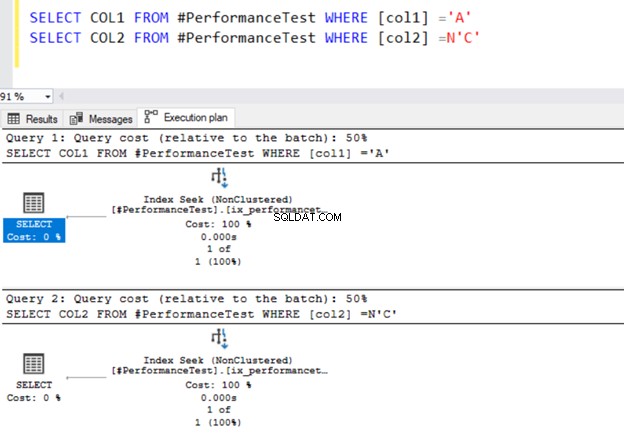
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Les deux requêtes utilisent l'opérateur de recherche d'index et les index que nous avons définis précédemment.
Maintenant, nous basculons les valeurs de type de données pour comparaison avec le prédicat WHERE. La colonne 1 a un type de données VARCHAR, mais nous spécifions N'A' pour le mettre en tant que type de données NVARCHAR.
De même, col2 est le type de données NVARCHAR, et nous spécifions la valeur "C" qui fait référence au type de données VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'Dans le plan d'exécution réel de la requête, vous obtenez une analyse d'index et l'instruction SELECT comporte un symbole d'avertissement.
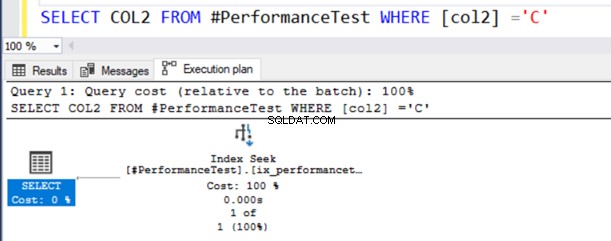
Cette requête fonctionne correctement car le type de données NVARCHAR() peut avoir à la fois des valeurs Unicode et non Unicode.
Maintenant, la deuxième requête utilise un parcours d'index et émet un symbole d'avertissement sur l'opérateur SELECT.
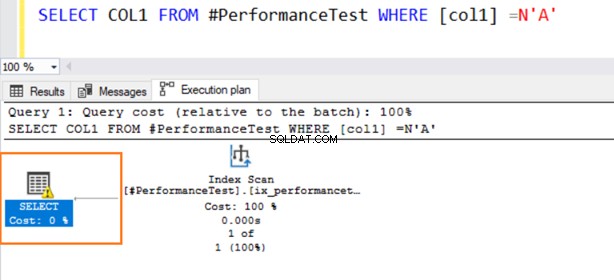
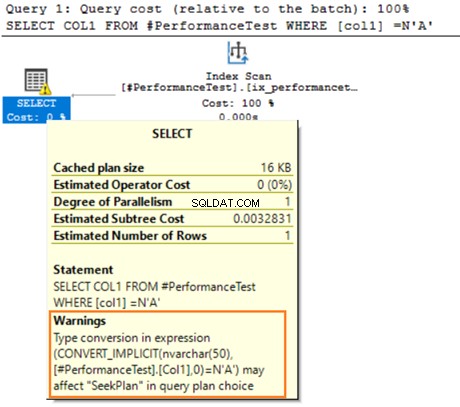
Passez la souris sur l'instruction SELECT qui émet un avertissement concernant la conversion implicite. SQL Server n'a pas pu utiliser correctement l'index existant. Cela est dû aux différents algorithmes de tri des données pour les types de données VARCHAR et NVARCHAR.
Si la table contient des millions de lignes, SQL Server doit effectuer un travail supplémentaire et convertir implicitement les données à l'aide de la conversion de données. Cela pourrait avoir un impact négatif sur les performances de votre requête. Par conséquent, vous devez éviter de mélanger et de faire correspondre ces types de données lors de l'optimisation des requêtes.
Conclusion
Vous devez revoir vos exigences en matière de données lors de la conception appropriée des tables de base de données et du type de données de leurs colonnes. Généralement, le type de données VARCHAR répond à la plupart de vos besoins en données. Toutefois, si vous devez stocker à la fois des types de données Unicode et non Unicode dans une colonne, vous pouvez envisager d'utiliser NVARCHAR. Cependant, vous devez examiner son implication sur les performances et la taille de stockage avant de prendre la décision finale.