SQL DISTINCT est-il bon (ou mauvais) lorsque vous devez supprimer les doublons dans les résultats ?
Certains disent que c'est bien et ajoutent DISTINCT lorsque des doublons apparaissent. Certains disent que c'est mauvais et suggèrent d'utiliser GROUP BY sans fonction d'agrégation. D'autres disent que DISTINCT et GROUP BY sont identiques lorsque vous devez supprimer des doublons.
Cet article plongera dans les détails pour obtenir des réponses correctes. Ainsi, éventuellement, vous utiliserez le meilleur mot-clé en fonction du besoin. Commençons.
Un bref rappel sur les bases de l'instruction SQL SELECT DISTINCT
Avant d'approfondir, rappelons ce qu'est l'instruction SQL SELECT DISTINCT. Une table de base de données peut inclure des valeurs en double pour de nombreuses raisons, mais nous pouvons souhaiter obtenir uniquement les valeurs uniques. Dans ce cas, SELECT DISTINCT est pratique. Cette clause DISTINCT oblige l'instruction SELECT à ne récupérer que des enregistrements uniques.
La syntaxe de l'instruction est simple :
SELECT DISTINCT column
FROM table_name
WHERE [condition];Ici, la condition WHERE est facultative.
L'instruction s'applique à la fois à une seule colonne et à plusieurs colonnes. La syntaxe de cette instruction appliquée à plusieurs colonnes est la suivante :
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Notez que le scénario d'interrogation de plusieurs colonnes suggérera d'utiliser la combinaison de valeurs dans toutes les colonnes définies par l'instruction pour déterminer l'unicité.
Et maintenant, explorons l'utilisation pratique et les pièges de l'application de l'instruction SELECT DISTINCT.
Comment SQL DISTINCT fonctionne pour supprimer les doublons
Obtenir des réponses n'est pas si difficile à trouver. SQL Server nous a fourni des plans d'exécution pour voir comment une requête sera traitée pour nous donner les résultats nécessaires.
La section suivante se concentre sur le plan d'exécution lors de l'utilisation de DISTINCT. Vous devez appuyer sur Ctrl-M dans SQL Server Management Studio avant d'exécuter les requêtes ci-dessous. Ou cliquez sur Inclure le plan d'exécution réel dans la barre d'outils.
Plans de requête dans SQL DISTINCT
Commençons par comparer 2 requêtes. La première n'utilisera pas DISTINCT, et la deuxième requête le fera.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Voici le plan d'exécution :
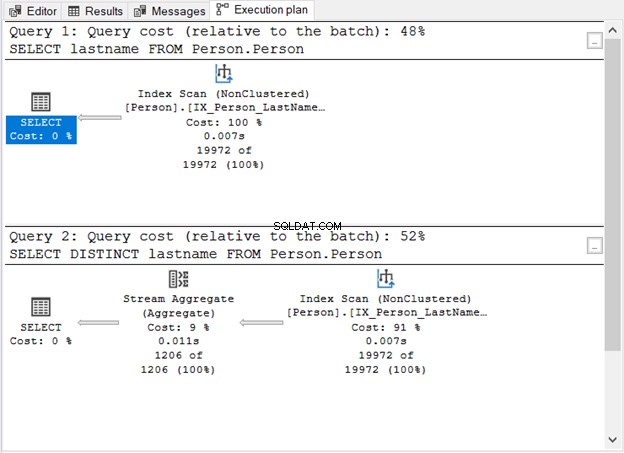
Que nous a montré la figure 1 ?
- Sans le mot-clé DISTINCT, la requête est simple.
- Une étape supplémentaire apparaît après l'ajout de DISTINCT.
- Le coût des requêtes avec DISTINCT est plus élevé que sans lui.
- Les deux ont des opérateurs Index Scan. Cela est compréhensible car il n'y a pas de clause WHERE spécifique dans nos requêtes.
- L'étape supplémentaire, l'opérateur Stream Aggregate, est utilisée pour supprimer les doublons.
Le nombre de lectures logiques est le même (107) si vous cochez les E/S STATISTIQUES. Pourtant, le nombre d'enregistrements est très différent. 19 972 lignes sont renvoyées par la première requête. Pendant ce temps, 1 206 lignes sont renvoyées par la deuxième requête.
Par conséquent, vous ne pouvez pas ajouter DISTINCT à tout moment. Mais si vous avez besoin de valeurs uniques, c'est une surcharge nécessaire.
Il existe des opérateurs utilisés pour générer des valeurs uniques. Examinons-en quelques-unes.
AGRÉGATION DE FLUX
Il s'agit de l'opérateur que vous avez vu dans la figure 1. Il accepte une seule entrée et génère un résultat agrégé. Dans la figure 1, l'entrée provient de l'opérateur Index Scan. Cependant, Stream Aggregate a besoin d'une entrée triée.
Comme vous pouvez le voir sur la figure 1, il utilise le IX_Person_LastName_FirstName_MiddleName , un index non unique sur les noms. Étant donné que l'index trie déjà les enregistrements par nom, le Stream Aggregate accepte l'entrée. Sans l'index, l'optimiseur de requête peut choisir d'utiliser un opérateur de tri supplémentaire dans le plan. Et ce sera plus cher. Ou, il peut utiliser une correspondance de hachage.
HASH MATCH (AGREGATE)
Un autre opérateur utilisé par DISTINCT est Hash Match. Cet opérateur est utilisé pour les jointures et les agrégations.
Lors de l'utilisation de DISTINCT, Hash Match agrège les résultats pour produire des valeurs uniques. Voici un exemple.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Et voici le plan d'exécution :
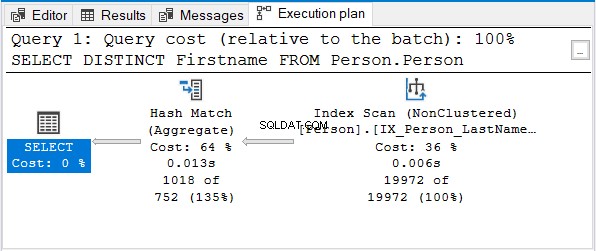
Mais pourquoi pas Stream Aggregate ?
Notez que le même index de nom est utilisé. Cet index trie avec Nom de famille première. Donc, un Prénom seule la requête deviendra non triée.
Hash Match (Aggregate) est le prochain choix logique pour supprimer les doublons.
HASH MATCH (FLOW DISTINCT)
Le Hash Match (Aggregate) est un opérateur bloquant. Ainsi, il ne produira pas la sortie qu'il a traitée tout le flux d'entrée. Si nous restreignons le nombre de lignes (comme utiliser TOP avec DISTINCT), cela produira une sortie unique dès que ces lignes seront disponibles. C'est ce qu'est Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
La requête utilise TOP 100 avec DISTINCT. Voici le plan d'exécution :
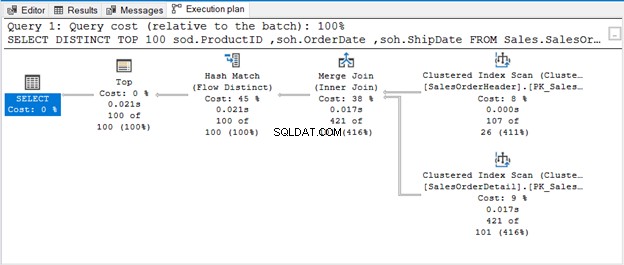
LORSQU'IL N'Y A AUCUN OPÉRATEUR POUR SUPPRIMER LES DOUPLES
Ouais. Cela peut arriver. Prenons l'exemple ci-dessous.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Ensuite, vérifiez le plan d'exécution :
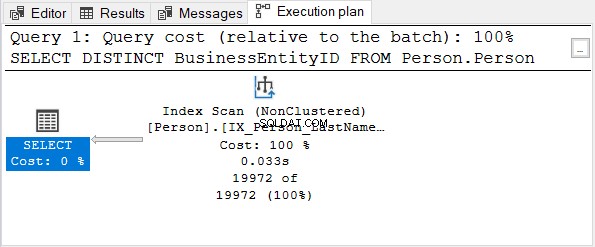
L'BusinessEntityID colonne est la clé primaire. Étant donné que cette colonne est déjà unique, il est inutile d'appliquer DISTINCT. Essayez de supprimer DISTINCT de l'instruction SELECT - le plan d'exécution est le même que dans la figure 4.
Il en va de même lorsque vous utilisez DISTINCT sur des colonnes avec un index unique.
SQL DISTINCT fonctionne sur TOUTES les colonnes de la liste SELECT
Jusqu'à présent, nous n'avons utilisé qu'une seule colonne dans nos exemples. Cependant, DISTINCT fonctionne sur TOUTES les colonnes que vous spécifiez dans la liste SELECT.
Voici un exemple. Cette requête s'assurera que les valeurs des 3 colonnes seront uniques.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
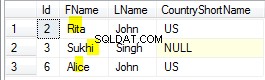
Remarquez les premières lignes du jeu de résultats de la figure 5.
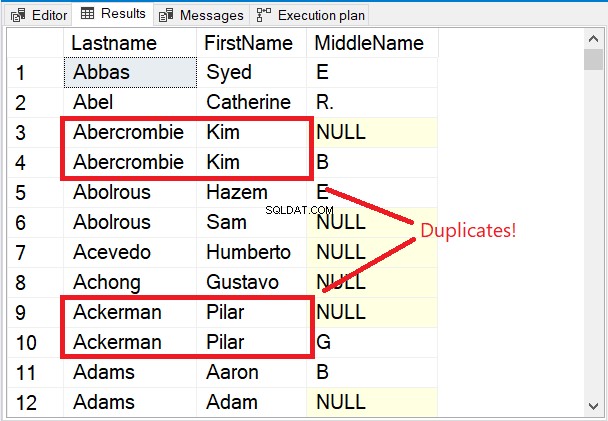
Les premières lignes sont toutes uniques. Le mot-clé DISTINCT s'assurait que le Deuxième prénom colonne est également prise en compte. Remarquez les 2 noms encadrés en rouge. Considérant le nom de famille et Prénom n'en fera que des doublons. Mais en ajoutant Deuxième prénom au mix a tout changé.
Que faire si vous souhaitez obtenir des prénoms et des noms de famille uniques, mais inclure le deuxième prénom dans le résultat ?
Vous avez 2 options :
- Ajoutez une clause WHERE pour supprimer les deuxièmes prénoms NULL. Cela supprimera tous les noms avec un deuxième prénom NULL.
- Ou, ajoutez une clause GROUP BY sur Lastname et Prénom Colonnes. Ensuite, utilisez la fonction d'agrégation MIN sur le Deuxième prénom colonne. Cela obtiendra 1 deuxième prénom avec les mêmes nom et prénom.
SQL DISTINCT contre GROUP BY
Lorsque vous utilisez GROUP BY sans fonction d'agrégation, il agit comme DISTINCT. Comment savons nous? Une façon de le savoir est d'utiliser un exemple.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Exécutez-les et consultez le plan d'exécution. Est-ce comme la capture d'écran ci-dessous ?
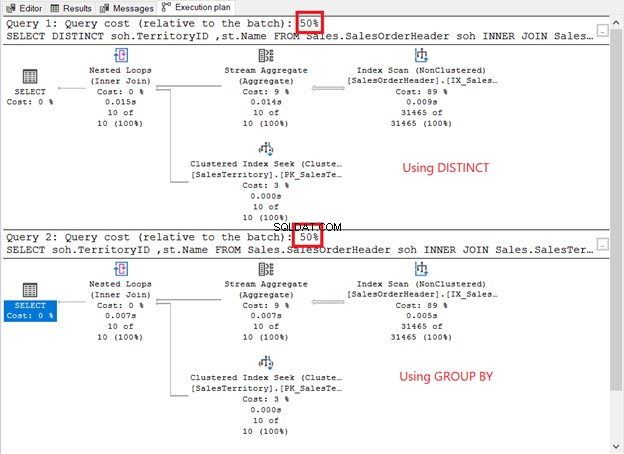
Comment se comparent-ils ?
- Ils ont les mêmes opérateurs de plan et la même séquence.
- Le coût de l'opérateur de chacun et les coûts de requête sont les mêmes.
Si vous cochez la case QueryPlanHash propriétés des 2 opérateurs SELECT, ils sont identiques. Par conséquent, l'optimiseur de requête a utilisé le même processus pour renvoyer les mêmes résultats.
En fin de compte, nous ne pouvons pas dire que l'utilisation de GROUP BY est meilleure que DISTINCT pour renvoyer des valeurs uniques. Vous pouvez le prouver en utilisant les exemples ci-dessus pour remplacer DISTINCT par GROUP BY.
C'est maintenant une question de préférence que vous utiliserez. Je préfère DISTINCT. Il indique explicitement l'intention de la requête - produire des résultats uniques. Et pour moi, GROUP BY sert à regrouper les résultats à l'aide d'une fonction d'agrégation. Cette intention est également claire et cohérente avec le mot-clé lui-même. Je ne sais pas si quelqu'un d'autre maintiendra mes requêtes un jour. Ainsi, le code doit être clair.
Mais ce n'est pas la fin de l'histoire.
Lorsque SQL DISTINCT n'est pas identique à GROUP BY
J'ai juste exprimé mon opinion, et puis ça ?
C'est vrai. Ils ne seront pas les mêmes tout le temps. Prenons cet exemple.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Bien que le jeu de résultats ne soit pas trié, les lignes sont les mêmes que dans l'exemple précédent. La seule différence est l'utilisation d'une sous-requête :
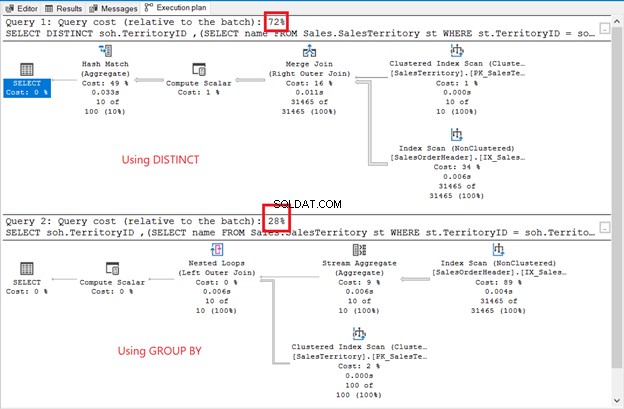
Les différences sont évidentes :opérateurs, coût de la requête, plan global. Cette fois, GROUP BY gagne avec seulement 28 % de coût de requête. Mais voici le problème.
Le but est de vous montrer qu'ils peuvent être différents. C'est tout. Ce n'est en aucun cas une recommandation. L'utilisation d'une jointure a un meilleur plan d'exécution (voir à nouveau la figure 6).
L'essentiel
Voici ce que nous avons appris jusqu'à présent :
- DISTINCT ajoute un opérateur de plan pour supprimer les doublons.
- DISTINCT et GROUP BY sans fonction d'agrégation donnent le même plan. En bref, ce sont les mêmes la plupart du temps.
- Parfois, DISTINCT et GROUP BY peuvent avoir des plans différents lorsqu'une sous-requête est impliquée dans la liste SELECT.
Alors, SQL DISTINCT est-il bon ou mauvais pour supprimer les doublons dans les résultats ?
Les résultats disent que c'est bon. Ce n'est ni meilleur ni pire que GROUP BY car les plans sont les mêmes. Mais c'est une bonne habitude de vérifier le plan d'exécution. Pensez à l'optimisation dès le départ. De cette façon, si vous rencontrez des différences dans DISTINCT et GROUP BY, vous les repérerez.
De plus, les outils modernes rendent cette tâche beaucoup plus simple. Par exemple, un produit populaire dbForge SQL Complete de Devart a une fonctionnalité spécifique qui calcule les valeurs dans les fonctions d'agrégation dans le jeu de résultats prêt de la grille de résultats SSMS. Les valeurs DISTINCT y sont également présentes.
Comme le poste? Ensuite, faites passer le mot en le partageant sur vos plateformes de médias sociaux préférées.
Articles connexes pour plus d'informations
- SQL GROUP BY :3 astuces simples pour regrouper les résultats comme un pro
- SQL INSERT INTO SELECT :5 façons simples de gérer les doublons
- Que sont les fonctions d'agrégation SQL ? (Conseils faciles pour les débutants)
- Optimisation des requêtes SQL : 5 éléments essentiels pour optimiser les requêtes