Ceci est le premier article d'une série d'articles sur l'OLTP en mémoire. Il vous aide à comprendre le fonctionnement interne du nouveau moteur Hekaton. Nous nous concentrerons sur les détails des tables et des index optimisés en mémoire. Il s'agit de l'article d'entrée de gamme, ce qui signifie que vous n'avez pas besoin d'être un expert SQL Server, cependant, vous devez avoir quelques connaissances de base sur le moteur SQL Server traditionnel.
Présentation
Le moteur OLTP en mémoire SQL Server 2014 (projet Hekaton) a été créé à partir de zéro pour utiliser des téraoctets de mémoire disponible et un grand nombre de cœurs de traitement. L'OLTP en mémoire permet aux utilisateurs de travailler avec des tables et des index optimisés en mémoire et des procédures stockées compilées en mode natif. Vous pouvez l'utiliser avec les tables et les index sur disque et les procédures stockées T-SQL, que SQL Server a toujours fournies.
Les composants internes et les capacités du moteur OLTP en mémoire diffèrent considérablement du moteur relationnel standard. Vous devez réviser presque tout ce que vous saviez sur la gestion de plusieurs processus simultanés.
Le moteur SQL Server est optimisé pour le stockage sur disque. Il lit les pages de données de 8 Ko dans la mémoire pour le traitement et réécrit les pages de données de 8 Ko sur le disque après les modifications. Bien sûr, SQL Server corrige avant tout les modifications apportées au disque dans le journal des transactions. La lecture de pages de données de 8 Ko à partir du disque et leur réécriture peuvent générer beaucoup d'E/S et entraîner un coût de latence plus élevé. Même lorsque les données sont dans le cache tampon, le serveur SQL est conçu pour supposer que ce n'est pas le cas, ce qui entraîne une utilisation inefficace du processeur.
Compte tenu des limites des structures de stockage traditionnelles sur disque, l'équipe SQL Server a commencé à créer un moteur de base de données optimisé pour une grande mémoire principale et des processeurs multicœurs. L'équipe s'est fixé les objectifs suivants :
- Optimisé pour les données entièrement stockées en mémoire, mais également durables lors des redémarrages de SQL Server
- Entièrement intégré au moteur SQL Server existant
- Très hautes performances pour les opérations OLTP
- Conçu pour les processeurs modernes
L'OLTP en mémoire de SQL Server répond à tous ces objectifs.
À propos de l'OLTP en mémoire
SQL Server 2014 In-Memory OLTP fournit un certain nombre de technologies pour travailler avec des tables optimisées en mémoire, ainsi que des tables sur disque. Par exemple, il vous permet d'accéder aux données en mémoire à l'aide d'interfaces standard telles que T-SQL et SSMS. L'illustration suivante présente des tables et des index optimisés en mémoire, dans le cadre de l'OLTP en mémoire (à gauche) et des tables sur disque (à gauche) qui nécessitent la lecture et l'écriture de pages de données de 8 Ko. L'OLTP en mémoire prend également en charge les procédures stockées compilées en mode natif et fournit un nouveau compilateur OLTP en mémoire.
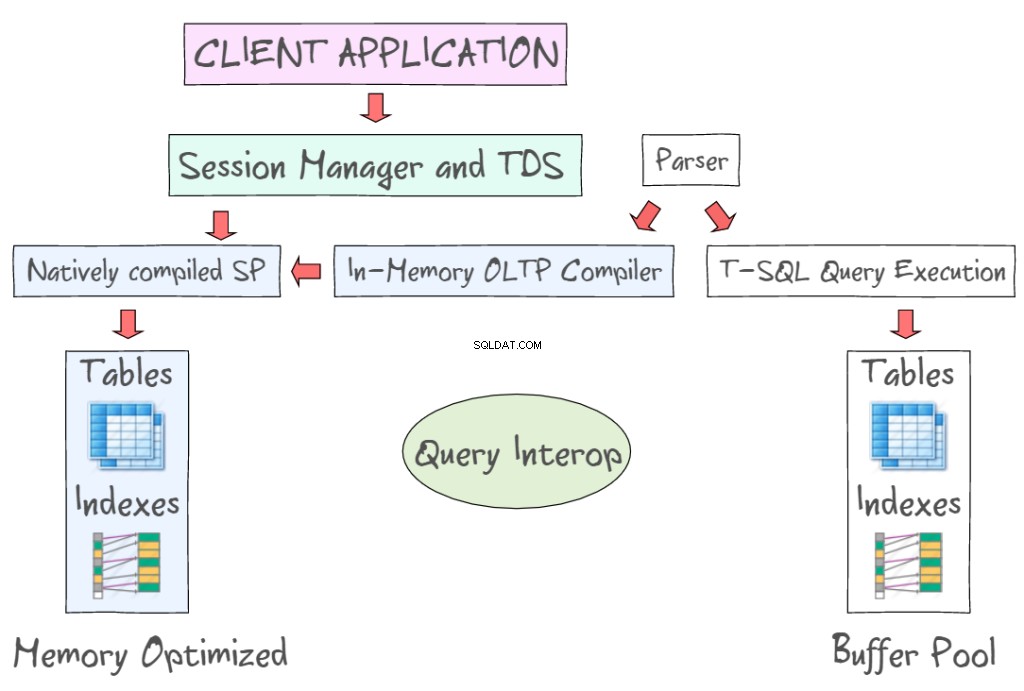
Query Interop permet d'interpréter T-SQL pour référencer des tables optimisées en mémoire. Si une transaction fait référence à la fois à des tables à mémoire optimisée et à des tables sur disque, elle peut être appelée transaction inter-conteneurs s. L'application cliente utilise Tabular Data Stream, un protocole de couche application utilisé pour transférer des données entre un serveur de base de données et un client. Il a été initialement conçu et développé par Sybase Inc. pour leur moteur de base de données relationnelle Sybase SQL Server en 1984, puis par Microsoft dans Microsoft SQL Server.
Tableaux à mémoire optimisée
Lors de l'accès aux tables sur disque, les données requises peuvent déjà être en mémoire, mais elles ne le sont peut-être pas. Si les données ne sont pas en mémoire, SQL Server doit les lire à partir du disque. La différence la plus fondamentale lors de l'utilisation de tables optimisées en mémoire est que la table entière et ses index sont stockés en mémoire tout le temps . Les opérations de données simultanées ne nécessitent aucun verrouillage ou verrouillage.
Lorsqu'un utilisateur modifie des données en mémoire, SQL Server effectue des E/S de disque pour toute table qui doit être durable, autrement dit, où nous avons besoin d'une table pour conserver les données en mémoire au moment d'une panne ou d'un redémarrage du serveur.
Structure de stockage basée sur les lignes
Une autre différence significative est la structure de stockage sous-jacente. Les tables sur disque sont optimisées pour adressables par bloc stockage sur disque, tandis que les tables optimisées en mémoire sont optimisées pour adressable par octet stockage en mémoire.
SQL Server conserve les lignes de données dans des pages de données de 8 Ko, avec une allocation d'espace à partir des étendues pour les tables sur disque. La page de données est l'unité fondamentale du stockage sur disque et en mémoire. Lors de la lecture et de l'écriture de données à partir du disque, SQL Server lit et écrit uniquement les pages de données pertinentes. Une page de données ne contiendra que les données d'une table ou d'un index. Les processus d'application modifient les lignes sur différentes pages de données selon les besoins. Plus tard, lors de l'opération CHECKPOINT, SQL Server corrige d'abord les enregistrements du journal sur le disque, puis écrit toutes les pages modifiées sur le disque. Cette opération provoque souvent de nombreuses E/S physiques aléatoires.
Pour les tables optimisées en mémoire, il n'y a pas de pages de données, ni d'extents. Il n'y a que des lignes de données écrites dans la mémoire de manière séquentielle, dans l'ordre dans lequel les transactions se sont produites. Chaque ligne contient un pointeur d'index vers la ligne suivante. Toutes les E/S sont des analyses en mémoire de ces structures. Il n'y a aucune notion d'écriture de lignes de données à un emplacement particulier appartenant à un objet spécifié. Cependant, vous n'avez pas à penser que les tables à mémoire optimisée sont stockées en tant qu'ensemble non organisé de lignes de données (similaire aux tas sur disque). Chaque instruction CREATE TABLE pour une table optimisée en mémoire crée au moins un index que SQL Server utilise pour lier toutes les lignes de données de cette table.
Chaque ligne de données se compose de l'en-tête de ligne et de la charge utile qui correspond aux données de colonne réelles. L'en-tête stocke des informations sur l'instruction qui a créé la ligne, les pointeurs pour chaque index sur la table cible et les valeurs d'horodatage. L'horodatage indique l'heure à laquelle une transaction a inséré et supprimé une ligne. Les enregistrements SQL Server sont mis à jour en insérant une nouvelle version de ligne et en marquant l'ancienne version comme supprimée. Plusieurs versions d'une même ligne peuvent exister à un moment donné. Cela permet un accès simultané à la même ligne lors de la modification des données. SQL Server affiche la version de ligne pertinente pour chaque transaction en fonction de l'heure à laquelle la transaction a démarré par rapport aux horodatages de la version de ligne. C'est le cœur du nouveau contrôle de la concurrence multi-versions mécanisme pour les tables en mémoire.
Soit dit en passant, Oracle dispose d'un excellent système de contrôle multi-versions. Fondamentalement, cela fonctionne comme suit :
- L'utilisateur A démarre une transaction et met à jour 1 000 lignes avec une certaine valeur au moment T1.
- L'utilisateur B lit les mêmes 1 000 lignes à l'instant T2.
- L'utilisateur A met à jour la ligne 565 avec la valeur Y (la valeur d'origine était X).
- L'utilisateur B atteint la ligne 565 et constate qu'une transaction est en cours depuis l'heure T1.
- La base de données renvoie l'enregistrement non modifié à partir des journaux. La valeur renvoyée est la valeur qui a été validée au moment inférieur ou égal à T2.
- Si l'enregistrement n'a pas pu être extrait des journaux redo, cela signifie que la base de données n'est pas configurée correctement. Plus d'espace doit être alloué aux journaux.
- Les résultats renvoyés sont toujours les mêmes par rapport à l'heure de début de la transaction. Ainsi, au sein de la transaction, la cohérence de lecture est atteinte.
Tables compilées nativement
La dernière différence majeure est que les tables optimisées en mémoire sont compilées nativement . Lorsqu'un utilisateur crée une table ou un index à mémoire optimisée, SQL Server stocke la structure de chaque table (ainsi que tous les index) dans les métadonnées. Plus tard, SQL Server utilise ces métadonnées pour compiler dans DDL un ensemble de routines de langage natif pour accéder à la table. Ces DDL sont associés à la base de données mais n'en font pas partie.
En d'autres termes, SQL Server conserve en mémoire non seulement des tables et des index, mais également des DDL pour accéder et modifier ces structures. Une fois qu'une table a été modifiée, SQL Server doit recréer tous les DDL pour les opérations de table. C'est pourquoi vous ne pouvez pas modifier une table une fois créée. Ces opérations sont invisibles pour les utilisateurs.
Procédures stockées compilées nativement
Les meilleures performances sont obtenues en utilisant des procédures stockées compilées en mode natif pour accéder aux tables compilées en mode natif. Ces procédures contiennent des instructions du processeur et peuvent être exécutées directement par la CPU sans autre compilation. Cependant, il existe certaines restrictions sur les constructions T-SQL pour les procédures stockées compilées en mode natif (par rapport au code traditionnellement interprété). Un autre point important est que les procédures stockées compilées en mode natif ne peuvent accéder qu'aux tables optimisées en mémoire.
Pas de verrous
L'OLTP en mémoire est un système sans verrouillage. Cela est possible car SQL Server ne modifie jamais aucune ligne existante. L'opération UPDATE crée la nouvelle version et marque la version précédente comme supprimée. Ensuite, elle insère une nouvelle version de ligne avec de nouvelles données à l'intérieur.
Index
Comme vous l'avez peut-être deviné, les index sont très différents des traditionnels. Les tables optimisées en mémoire n'ont pas de pages. SQL Server utilise des index pour lier toutes les lignes appartenant à une table dans une structure unique. Nous ne pouvons pas utiliser l'instruction CREATE INDEX pour créer un index pour la table optimisée en mémoire. Une fois que vous avez créé la PRIMARY KEY sur une colonne, SQL Server crée automatiquement un index unique sur cette colonne. En fait, c'est le seul index unique autorisé. Vous pouvez créer un maximum de huit index sur une table optimisée en mémoire.
Par analogie avec les tables, SQL Server conserve en mémoire les index optimisés en mémoire. Cependant, SQL Server n'enregistre jamais les opérations sur les index. SQL Server gère automatiquement les index lors des modifications de table.
Les tables à mémoire optimisée prennent en charge deux types d'index :index de hachage et indice de plage . Les deux sont des structures non clusterisées.
L'index de hachage est un nouveau type d'index, conçu spécifiquement pour les tables à mémoire optimisée. Il est extrêmement utile pour effectuer des recherches sur des valeurs spécifiques. L'index lui-même est stocké sous forme de table de hachage. Il s'agit d'un tableau de compartiments de hachage, où chaque compartiment est un pointeur vers une seule ligne.
L'indice de plage (non clusterisé) est utile pour récupérer des plages de valeurs.
Récupération
Le mécanisme de restauration de base d'une base de données avec des tables à mémoire optimisée est le même que le mécanisme de récupération des bases de données avec des tables sur disque. Cependant, la récupération des tables optimisées en mémoire inclut l'étape de chargement des tables optimisées en mémoire dans la mémoire avant que la base de données ne soit disponible pour l'accès utilisateur.
Lorsque SQL Server redémarre, chaque base de données passe par les phases suivantes du processus de récupération :analyse , refaire , et annuler .
Lors de la phase d'analyse, le moteur OLTP en mémoire identifie l'inventaire des points de contrôle à charger et précharge ses entrées de journal de table système. Il traitera également certains enregistrements du journal d'allocation de fichiers.
Lors de la phase de rétablissement, les données des paires de données et de fichiers delta sont chargées en mémoire. Ensuite, les données sont mises à jour à partir du journal des transactions actif en fonction du dernier point de contrôle durable et les tables en mémoire sont remplies et les index reconstruits. Au cours de cette phase, la récupération de table sur disque et optimisée en mémoire s'exécute simultanément.
La phase d'annulation n'est pas nécessaire pour les tables optimisées en mémoire, car l'OLTP en mémoire n'enregistre aucune transaction non validée pour les tables optimisées en mémoire.
Lorsque toutes les opérations sont terminées, la base de données est accessible.
Résumé
Dans cet article, nous avons examiné rapidement le moteur OLTP en mémoire de SQL Server. Nous avons appris que les structures optimisées en mémoire sont stockées en mémoire. Les processus d'application peuvent trouver les données requises en accédant à ces structures en mémoire sans avoir besoin d'E/S disque. Dans les articles suivants, nous verrons comment créer et accéder aux bases de données et tables OLTP en mémoire.
Autres lectures
OLTP en mémoire :nouveautés de SQL Server 2016
Utilisation des index dans les tables optimisées en mémoire SQL Server