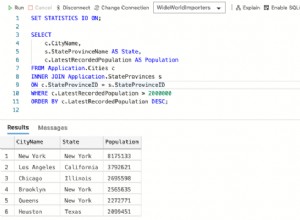
Solution de base
Générer une liste complète des mois et LEFT JOIN le reste :
SELECT *
FROM (
SELECT to_char(m, 'YYYY-MON') AS yyyymmm
FROM generate_series(<start_date>, <end_date>, interval '1 month') m
) m
LEFT JOIN ( <your query here> ) q USING (yyyymmm);
Réponses associées avec plus d'explications :
- Rejoignez une requête de comptage sur un generate_series dans postgres et récupérez également les valeurs nulles en tant que "0"
- Meilleur moyen de compter les enregistrements par intervalles de temps arbitraires dans Rails+Postgres
Solution avancée pour votre cas
Votre requête est plus compliquée que je ne l'avais d'abord compris. Vous avez besoin de la somme courante sur tous lignes de l'élément sélectionné, vous souhaitez alors supprimer les lignes antérieures à une date minimale et remplir les mois manquants avec la somme précalculée du mois précédent.
J'y parviens maintenant avec LEFT JOIN LATERAL .
SELECT COALESCE(m.yearmonth, c.yearmonth)::date, sold_qty, on_hand
FROM (
SELECT yearmonth
, COALESCE(sold_qty, 0) AS sold_qty
, sum(on_hand_mon) OVER (ORDER BY yearmonth) AS on_hand
, lead(yearmonth) OVER (ORDER BY yearmonth)
- interval '1 month' AS nextmonth
FROM (
SELECT date_trunc('month', c.change_date) AS yearmonth
, sum(c.sold_qty / s.qty)::numeric(18,2) AS sold_qty
, sum(c.on_hand) AS on_hand_mon
FROM item_change c
LEFT JOIN item i USING (item_id)
LEFT JOIN item_size s ON s.item_id = i.item_id AND s.name = i.sell_size
LEFT JOIN item_plu p ON p.item_id = i.item_id AND p.seq_num = 0
WHERE c.change_date < date_trunc('month', now()) - interval '1 day'
AND c.item_id = (SELECT item_id FROM item_plu WHERE number = '51515')
GROUP BY 1
) sub
) c
LEFT JOIN LATERAL generate_series(c.yearmonth
, c.nextmonth
, interval '1 month') m(yearmonth) ON TRUE
WHERE c.yearmonth > date_trunc('year', now()) - interval '540 days'
ORDER BY COALESCE(m.yearmonth, c.yearmonth);
SQL Fiddle avec un cas de test minimum.
Points majeurs :
-
J'ai complètement supprimé votre VIEW de la requête. Beaucoup de frais pour aucun gain.
-
Puisque vous sélectionnez un single
item_id, vous n'avez pas besoin deGROUP BY item_idouPARTITION BY item_id. -
Utilisez des alias de table courts et assurez-vous que toutes les références ne sont pas ambiguës, en particulier lorsque vous publiez sur un forum public.
-
Les parenthèses dans vos jointures n'étaient que du bruit. Les jointures sont de toute façon exécutées de gauche à droite par défaut.
-
Limites de dates simplifiées (puisque je fonctionne avec des horodatages) :
date_trunc('year', current_date) - interval '540 days' date_trunc('month', current_date) - interval '1 day'équivalent, mais plus simple et plus rapide que :
current_date - date_part('day',current_date)::integer - 540 current_date - date_part('day',current_date)::integer -
Je remplis maintenant les mois manquants après tous les calculs avec
generate_series()appels par ligne. -
Il doit être
LEFT JOIN LATERAL ... ON TRUE, pas la forme abrégée d'unJOIN LATERALpour attraper la caisse d'angle de la dernière rangée. Explication détaillée :
Remarques importantes :
character(22) est un terrible type de données pour une clé primaire (ou tout colonne). Détails :
Idéalement, ce serait un int ou bigint colonne, ou éventuellement un UUID
.
En outre, stocker les montants d'argent en tant que money
type ou integer (représentant Cents) obtient de bien meilleurs résultats dans l'ensemble.
À long terme , les performances sont vouées à se détériorer, car vous devez inclure toutes les lignes dès le début dans votre calcul. Vous devez couper les anciennes lignes et matérialiser le solde de on_hold sur une base annuelle ou quelque chose du genre.