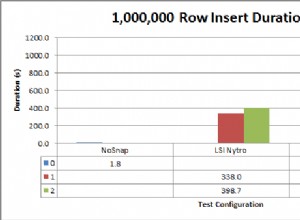
Il y a toujours 2 éléments à prendre en compte lors de l'optimisation des requêtes :
- Quels index peuvent être utilisés (vous devrez peut-être créer des index)
- Comment la requête est écrite (vous devrez peut-être modifier la requête pour permettre à l'optimiseur de requête de trouver les index appropriés et de ne pas relire les données de manière redondante)
Quelques remarques :
-
Vous effectuez des manipulations de dates avant de joindre vos dates. En règle générale, cela empêchera un optimiseur de requête d'utiliser un index même s'il existe. Vous devriez essayer d'écrire vos expressions de manière à ce que les colonnes indexées existent sans modification d'un côté de l'expression.
-
Vos sous-requêtes filtrent sur la même plage de dates que
generate_series. Il s'agit d'une duplication, et cela limite la capacité de l'optimiseur à choisir l'optimisation la plus efficace. Je soupçonne que cela a peut-être été écrit pour améliorer les performances car l'optimiseur n'a pas pu utiliser un index sur la colonne de date (body_time) ? -
REMARQUE :Nous aimerions en fait beaucoup utiliser un index sur
Body.body_time -
ORDER BYdans les sous-requêtes est au mieux redondante. Au pire, cela pourrait forcer l'optimiseur de requête à trier le jeu de résultats avant de le rejoindre ; et ce n'est pas nécessairement bon pour le plan de requête. Appliquez plutôt l'ordre juste à la fin pour l'affichage final. -
Utilisation de
LEFT JOINdans vos sous-requêtes est inapproprié. En supposant que vous utilisez les conventions ANSI pourNULLcomportement (et vous devriez l'être), tout extérieur se joint àenveloperenverraitenvelope_command=NULL, et ceux-ci seraient par conséquent exclus par la conditionenvelope_command=?. -
Sous-requêtes
oetisont presque identiques sauf pour laenvelope_commandévaluer. Cela oblige l'optimiseur à analyser deux fois les mêmes tables sous-jacentes. Vous pouvez utiliser un tableau croisé dynamique technique pour joindre les données une fois et diviser les valeurs en 2 colonnes.
Essayez ce qui suit qui utilise la technique du pivot :
SELECT p.period,
/*The pivot technique in action...*/
SUM(
CASE WHEN envelope_command = 1 THEN body_size
ELSE 0
END) AS Outbound,
SUM(
CASE WHEN envelope_command = 2 THEN body_size
ELSE 0
END) AS Inbound
FROM (
SELECT date '2009-10-01' + s.day AS period
FROM generate_series(0, date '2009-10-31' - date '2009-10-01') AS s(day)
) AS p
/*The left JOIN is justified to ensure ALL generated dates are returned
Also: it joins to a subquery, else the JOIN to envelope _could_ exclude some generated dates*/
LEFT OUTER JOIN (
SELECT b.body_size,
b.body_time,
e.envelope_command
FROM body AS b
INNER JOIN envelope e
ON e.message_id = b.message_id
WHERE envelope_command IN (1, 2)
) d
/*The expressions below allow the optimser to use an index on body_time if
the statistics indicate it would be beneficial*/
ON d.body_time >= p.period
AND d.body_time < p.period + INTERVAL '1 DAY'
GROUP BY p.Period
ORDER BY p.Period
MODIFIER :Ajout d'un filtre suggéré par Tom H.