Lorsque vous devez mettre en place un système d'analyse pour une entreprise, la question se pose souvent de savoir où stocker les données. Il n'y a pas toujours une option parfaite pour toutes les exigences et cela dépend du budget, de la quantité de données et des besoins de l'entreprise.
PostgreSQL, en tant que base de données open source la plus avancée, est si flexible qu'il peut servir de simple base de données relationnelle, de base de données de séries chronologiques et même de solution d'entreposage de données efficace et peu coûteuse. Vous pouvez également l'intégrer à plusieurs outils d'analyse.
Si vous recherchez un entrepôt de données largement compatible, peu coûteux et performant, la meilleure option de base de données pourrait être PostgreSQL, mais pourquoi ? Dans ce blog, nous verrons ce qu'est un entrepôt de données, pourquoi est-il nécessaire et pourquoi PostgreSQL pourrait être la meilleure option ici.
Qu'est-ce qu'un entrepôt de données
Un entrepôt de données est un système normalisé, cohérent et intégré qui contient des données actuelles ou historiques provenant d'une ou plusieurs sources et qui est utilisé pour le reporting et l'analyse des données. Il est considéré comme un élément central de l'intelligence d'affaires, qui est la stratégie et la technologie utilisées par une entreprise pour mieux comprendre son contexte commercial.
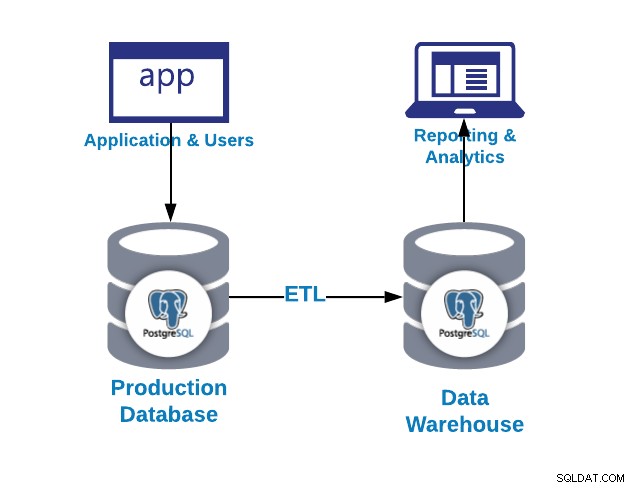
La première question que vous pouvez vous poser est pourquoi ai-je besoin d'un entrepôt de données ?
- Intégration :intégrez/centralisez les données de plusieurs systèmes/bases de données
- Standardiser :standardiser toutes les données dans le même format
- Analytics :analysez les données dans un contexte historique
Certains des avantages d'un entrepôt de données peuvent être...
- Intégrer des données provenant de plusieurs sources dans une seule base de données
- Éviter le blocage ou le chargement de la production en raison de requêtes de longue durée
- Stocker des informations historiques
- Restructurer les données pour répondre aux exigences d'analyse
Comme nous avons pu le voir dans l'image précédente, nous pouvons utiliser PostgreSQL pour les propositions OLAP et OLTP. Voyons la différence.
- OLTP :traitement des transactions en ligne. En général, il comporte un grand nombre de transactions en ligne courtes (INSERT, UPDATE, DELETE) générées par l'activité de l'utilisateur. Ces systèmes mettent l'accent sur le traitement très rapide des requêtes et le maintien de l'intégrité des données dans des environnements multi-accès. Ici, l'efficacité est mesurée par le nombre de transactions par seconde. Les bases de données OLTP contiennent des données détaillées et à jour.
- OLAP :traitement analytique en ligne. En général, il a un faible volume de transactions complexes générées par des rapports volumineux. Le temps de réponse est une mesure d'efficacité. Ces bases de données stockent des données historiques agrégées dans des schémas multidimensionnels. Les bases de données OLAP sont utilisées pour analyser des données multidimensionnelles à partir de plusieurs sources et perspectives.
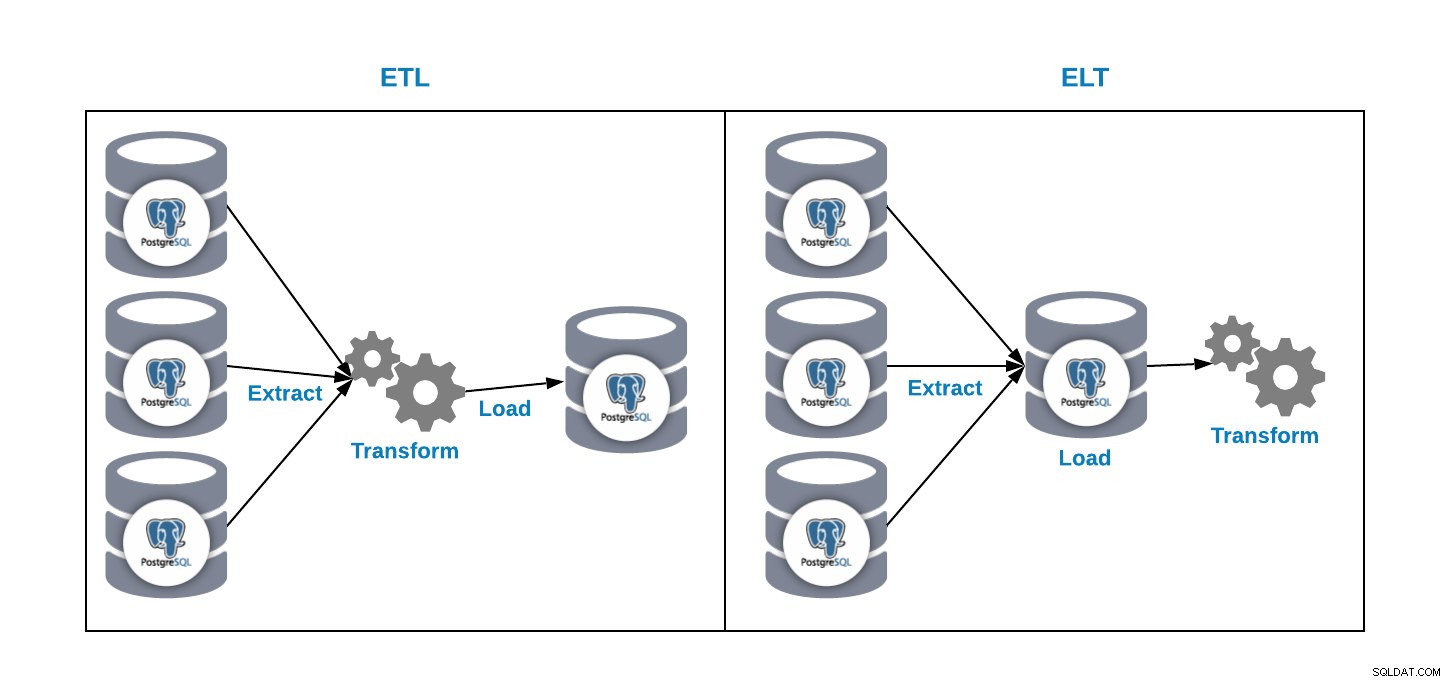
Nous avons deux façons de charger des données dans notre base de données d'analyse :
- ETL :Extrayez, transformez et chargez. C'est la façon de générer notre entrepôt de données. Tout d'abord, extrayez les données de la base de données de production, transformez les données en fonction de nos besoins, puis chargez les données dans notre entrepôt de données.
- ELT :Extrayez, chargez et transformez. Tout d'abord, extrayez les données de la base de données de production, chargez-les dans la base de données, puis transformez les données. Cette méthode s'appelle Data Lake et c'est un nouveau concept pour gérer nos mégadonnées.
Et maintenant, la deuxième question :pourquoi devrais-je utiliser PostgreSQL pour mon entrepôt de données ?
Avantages de PostgreSQL en tant qu'entrepôt de données
Examinons quelques-uns des avantages de l'utilisation de PostgreSQL comme entrepôt de données...
- Coût :si vous utilisez un environnement sur site, le coût du produit lui-même sera de 0 USD, même si vous utilisez un produit dans le cloud, le coût d'un produit basé sur PostgreSQL sera probablement inférieur à le reste des produits.
- Mise à l'échelle :vous pouvez mettre à l'échelle les lectures de manière simple en ajoutant autant de nœuds de réplique que vous le souhaitez.
- Performance :avec une configuration correcte, PostgreSQL a de très bonnes performances sur différents scénarios.
- Compatibilité :vous pouvez intégrer PostgreSQL à des outils ou applications externes pour l'exploration de données, OLAP et la création de rapports.
- Extensibilité :PostgreSQL possède des types de données et des fonctions définis par l'utilisateur.
Certaines fonctionnalités de PostgreSQL peuvent également nous aider à gérer les informations de notre entrepôt de données...
- Tables temporaires :il s'agit d'une table de courte durée qui existe pendant la durée d'une session de base de données. PostgreSQL supprime automatiquement les tables temporaires à la fin d'une session ou d'une transaction.
- Procédures stockées :vous pouvez l'utiliser pour créer des procédures ou fonctionner sur plusieurs langages (PL/pgSQL, PL/Perl, PL/Python, etc.).
- Partitionnement :ceci est très utile pour la maintenance de la base de données, les requêtes utilisant la clé de partition et les performances INSERT.
- Vue matérialisée :les résultats de la requête sont affichés sous forme de tableau.
- Tablespaces :vous pouvez modifier l'emplacement des données sur un autre disque. De cette façon, vous aurez un accès au disque parallélisé.
- Compatible PITR :vous pouvez créer des sauvegardes compatibles avec la récupération à un instant donné. Ainsi, en cas d'échec, vous pouvez restaurer l'état de la base de données sur une période de temps spécifique.
- Énorme communauté :et enfin, PostgreSQL dispose d'une énorme communauté où vous pouvez trouver de l'aide sur de nombreux problèmes différents.
Configuration de PostgreSQL pour l'utilisation de l'entrepôt de données
Il n'y a pas de meilleure configuration à utiliser dans tous les cas et dans toutes les technologies de base de données. Cela dépend de nombreux facteurs tels que le matériel, l'utilisation et la configuration système requise. Vous trouverez ci-dessous quelques conseils pour configurer votre base de données PostgreSQL afin qu'elle fonctionne correctement comme un entrepôt de données.
Basé sur la mémoire
- max_connections :en tant que base de données d'entrepôt de données, vous n'avez pas besoin d'un grand nombre de connexions, car elles seront utilisées pour les travaux de création de rapports et d'analyse. Vous pouvez donc limiter le nombre maximal de connexions à l'aide de ce paramètre.
- shared_buffers :définit la quantité de mémoire utilisée par le serveur de base de données pour les tampons de mémoire partagée. Une valeur raisonnable peut être comprise entre 15 % et 25 % de la mémoire RAM.
- effective_cache_size :cette valeur est utilisée par le planificateur de requêtes pour prendre en compte les plans qui peuvent ou non tenir en mémoire. Ceci est pris en compte dans les estimations de coût d'utilisation d'un indice; une valeur élevée rend plus probable l'utilisation de parcours d'index et une valeur faible rend plus probable l'utilisation de parcours séquentiels. Une valeur raisonnable serait d'environ 75 % de la mémoire RAM.
- mémoire de travail :spécifie la quantité de mémoire qui sera utilisée par les opérations internes de ORDER BY, DISTINCT, JOIN et les tables de hachage avant d'écrire dans les fichiers temporaires sur le disque. Lors de la configuration de cette valeur, nous devons tenir compte du fait que plusieurs sessions exécutent ces opérations en même temps et que chaque opération sera autorisée à utiliser autant de mémoire que spécifié par cette valeur avant de commencer à écrire des données dans des fichiers temporaires. Une valeur raisonnable peut être d'environ 2 % de la mémoire RAM.
- maintenance_work_mem :spécifie la quantité maximale de mémoire utilisée par les opérations de maintenance, telles que VACUUM, CREATE INDEX et ALTER TABLE ADD FOREIGN KEY. Une valeur raisonnable peut être d'environ 15 % de la mémoire RAM.
Basé sur le processeur
- Max_worker_processes :définit le nombre maximal de processus d'arrière-plan que le système peut prendre en charge. Une valeur raisonnable peut être le nombre de processeurs.
- Max_parallel_workers_per_gather :définit le nombre maximal de nœuds de calcul pouvant être démarrés par un seul nœud Gather ou Gather Merge. Une valeur raisonnable peut être 50 % du nombre de CPU.
- Max_parallel_workers :définit le nombre maximal de nœuds de calcul que le système peut prendre en charge pour les requêtes parallèles. Une valeur raisonnable peut être le nombre de processeurs.
Comme les données chargées dans notre entrepôt de données ne doivent pas changer, nous pouvons également désactiver l'Autovacuum pour éviter une charge supplémentaire sur votre base de données PostgreSQL. Les processus de mise sous vide et d'analyse peuvent faire partie du processus de chargement par lots.
Conclusion
Si vous recherchez un entrepôt de données largement compatible, peu coûteux et hautes performances, vous devez absolument considérer PostgreSQL comme une option pour votre base de données d'entrepôt de données. PostgreSQL présente de nombreux avantages et fonctionnalités utiles pour gérer notre entrepôt de données comme le partitionnement ou les procédures stockées, et bien plus encore.