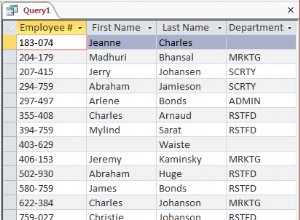
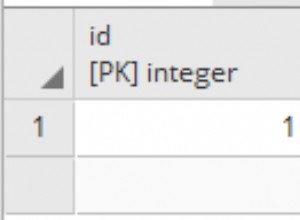
Si le CSV n'est pas excessivement volumineux et disponible sur votre machine locale, alors csvkit est la solution la plus simple. Il contient également un certain nombre d'autres utilitaires pour travailler avec les CSV, c'est donc un outil utile à savoir en général.
À sa plus simple saisie dans le shell :
$ csvsql myfile.csv
imprimera le CREATE TABLE requis Commande SQL, qui peut être enregistrée dans un fichier à l'aide de la redirection de sortie.
Si vous fournissez également une chaîne de connexion csvsql créera le tableau et téléchargera le fichier en une seule fois :
$ csvsql --db "$MY_DB_URI" --insert myfile.csv
Il existe également des options pour spécifier la version de SQL et CSV avec laquelle vous travaillez. Ils sont documentés dans l'aide intégrée :
$ csvsql -h
usage: csvsql [-h] [-d DELIMITER] [-t] [-q QUOTECHAR] [-u {0,1,2,3}] [-b]
[-p ESCAPECHAR] [-z MAXFIELDSIZE] [-e ENCODING] [-S] [-H] [-v]
[--zero] [-y SNIFFLIMIT]
[-i {access,sybase,sqlite,informix,firebird,mysql,oracle,maxdb,postgresql,mssql}]
[--db CONNECTION_STRING] [--query QUERY] [--insert]
[--tables TABLE_NAMES] [--no-constraints] [--no-create]
[--blanks] [--no-inference] [--db-schema DB_SCHEMA]
[FILE [FILE ...]]
Generate SQL statements for one or more CSV files, create execute those
statements directly on a database, and execute one or more SQL queries.
positional arguments:
FILE The CSV file(s) to operate on. If omitted, will accept
input on STDIN.
optional arguments:
-h, --help show this help message and exit
-d DELIMITER, --delimiter DELIMITER
Delimiting character of the input CSV file.
-t, --tabs Specifies that the input CSV file is delimited with
tabs. Overrides "-d".
-q QUOTECHAR, --quotechar QUOTECHAR
Character used to quote strings in the input CSV file.
-u {0,1,2,3}, --quoting {0,1,2,3}
Quoting style used in the input CSV file. 0 = Quote
Minimal, 1 = Quote All, 2 = Quote Non-numeric, 3 =
Quote None.
-b, --doublequote Whether or not double quotes are doubled in the input
CSV file.
-p ESCAPECHAR, --escapechar ESCAPECHAR
Character used to escape the delimiter if --quoting 3
("Quote None") is specified and to escape the
QUOTECHAR if --doublequote is not specified.
-z MAXFIELDSIZE, --maxfieldsize MAXFIELDSIZE
Maximum length of a single field in the input CSV
file.
-e ENCODING, --encoding ENCODING
Specify the encoding the input CSV file.
-S, --skipinitialspace
Ignore whitespace immediately following the delimiter.
-H, --no-header-row Specifies that the input CSV file has no header row.
Will create default headers.
-v, --verbose Print detailed tracebacks when errors occur.
--zero When interpreting or displaying column numbers, use
zero-based numbering instead of the default 1-based
numbering.
-y SNIFFLIMIT, --snifflimit SNIFFLIMIT
Limit CSV dialect sniffing to the specified number of
bytes. Specify "0" to disable sniffing entirely.
-i {access,sybase,sqlite,informix,firebird,mysql,oracle,maxdb,postgresql,mssql}, --dialect {access,sybase,sqlite,informix,firebird,mysql,oracle,maxdb,postgresql,mssql}
Dialect of SQL to generate. Only valid when --db is
not specified.
--db CONNECTION_STRING
If present, a sqlalchemy connection string to use to
directly execute generated SQL on a database.
--query QUERY Execute one or more SQL queries delimited by ";" and
output the result of the last query as CSV.
--insert In addition to creating the table, also insert the
data into the table. Only valid when --db is
specified.
--tables TABLE_NAMES Specify one or more names for the tables to be
created. If omitted, the filename (minus extension) or
"stdin" will be used.
--no-constraints Generate a schema without length limits or null
checks. Useful when sampling big tables.
--no-create Skip creating a table. Only valid when --insert is
specified.
--blanks Do not coerce empty strings to NULL values.
--no-inference Disable type inference when parsing the input.
--db-schema DB_SCHEMA
Optional name of database schema to create table(s)
in.
Plusieurs autres outils font également de l'inférence de schéma, notamment :
- Apache Spark
- Pandas (Python)
- Blaze (Python)
- read.csv + votre package db préféré en R
Chacun d'entre eux a la fonctionnalité de lire un CSV (et d'autres formats) dans une structure de données tabulaire généralement appelée DataFrame ou similaire, en déduisant les types de colonnes dans le processus. Ils ont ensuite d'autres commandes pour écrire un schéma SQL équivalent ou télécharger le DataFrame directement dans une base de données spécifiée. Le choix de l'outil dépendra du volume de données, de la manière dont elles sont stockées, des idiosyncrasies de votre CSV, de la base de données cible et de la langue dans laquelle vous préférez travailler.