Il s'agit du deuxième volet d'une série en deux parties sur repmgr de 2ndQuadrant, un outil open source à haute disponibilité pour PostgreSQL.
Dans la première partie, nous avons configuré un cluster PostgreSQL 12 à trois nœuds avec un nœud « témoin ». Le cluster se composait d'un nœud principal et de deux nœuds de secours. Le cluster et le nœud témoin ont été hébergés dans un Amazon Web Service Virtual Private Cloud (VPC). Les serveurs EC2 hébergeant les instances Postgres ont été placés dans des sous-réseaux dans différentes zones de disponibilité (AZ), comme indiqué ci-dessous :
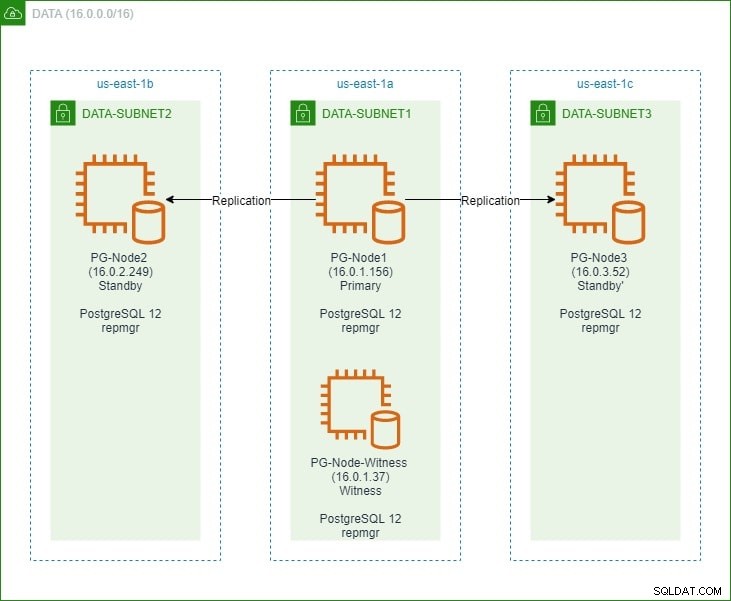
Nous ferons de nombreuses références aux noms de nœuds et à leurs adresses IP, voici donc à nouveau le tableau avec les détails des nœuds :
| Nom du nœud | Adresse IP | Rôle | Applications en cours d'exécution |
| PG-Node1 | 16.0.1.156 | Primaire | PostgreSQL 12 et repmgr |
| PG-Node2 | 16.0.2.249 | Veille 1 | PostgreSQL 12 et repmgr |
| PG-Node3 | 16.0.3.52 | Veille 2 | PostgreSQL 12 et repmgr |
| PG-Noeud-Témoin | 16.0.1.37 | Témoin | PostgreSQL 12 et repmgr |
Nous avons installé repmgr dans les nœuds principal et de secours, puis enregistré le nœud principal auprès de repmgr. Nous avons ensuite cloné les deux nœuds de secours à partir du nœud principal et les avons démarrés. Les deux nœuds de secours ont également été enregistrés auprès de repmgr. La commande "repmgr cluster show" nous a montré que tout fonctionnait comme prévu :

Problème actuel
La configuration de la réplication en continu avec repmgr est très simple. Ce que nous devons faire ensuite, c'est nous assurer que le cluster fonctionnera même lorsque le primaire devient indisponible. C'est ce que nous allons couvrir dans cet article.
Dans la réplication PostgreSQL, un primaire peut devenir indisponible pour plusieurs raisons. Par exemple :
- Le système d'exploitation du nœud principal peut tomber en panne ou ne plus répondre
- Le nœud principal peut perdre sa connectivité réseau
- Le service PostgreSQL dans le nœud principal peut planter, s'arrêter ou devenir indisponible de manière inattendue
- Le service PostgreSQL dans le nœud principal peut être arrêté intentionnellement ou accidentellement
Chaque fois qu'un primaire devient indisponible, un standby pas se promeut automatiquement au rôle principal. Un serveur de secours continue de répondre aux requêtes en lecture seule, bien que les données soient à jour jusqu'au dernier LSN reçu du serveur principal. Toute tentative d'opération d'écriture échouera.
Il existe deux façons d'atténuer ce problème :
- La veille est manuellement promu à un rôle principal. C'est généralement le cas pour un basculement ou un "basculement" planifié
- La veille est automatiquement promu à un rôle primordial. C'est le cas des outils non natifs qui surveillent en permanence la réplication et prennent des mesures de récupération lorsque le serveur principal n'est pas disponible. repmgr est l'un de ces outils.
Nous considérerons ici le deuxième scénario. Cette situation présente cependant des défis supplémentaires :
- S'il existe plusieurs standbys, comment l'outil (ou les standbys) décide-t-il lequel doit être promu comme principal ? Comment fonctionnent le quorum et le processus de promotion ?
- Pour plusieurs serveurs de secours, si l'un d'entre eux est défini comme principal, comment les autres nœuds commencent-ils à "le suivre" en tant que nouveau nœud principal ?
- Que se passe-t-il si le primaire fonctionne, mais pour une raison quelconque temporairement détaché du réseau ? Si l'un des remplaçants est promu au rang de principal, puis que le principal d'origine revient en ligne, comment éviter une situation de "split brain" ?
Réponse de remgr :nœud témoin et le démon repmgr
Pour répondre à ces questions, repmgr utilise quelque chose appelé un nœud témoin . Lorsque le nœud principal n'est pas disponible, c'est le travail du nœud témoin d'aider les serveurs de réserve à atteindre un quorum si l'un d'eux doit être promu à un rôle principal. Les serveurs de secours atteignent ce quorum en déterminant si le nœud principal est réellement hors ligne ou seulement temporairement indisponible. Le nœud témoin doit être situé dans le même centre de données/segment de réseau/sous-réseau que le nœud principal, mais ne doit JAMAIS fonctionner sur le même hôte physique que le nœud principal.
N'oubliez pas que dans la première partie de cette série, nous avons déployé un nœud témoin dans la même zone de disponibilité et le même sous-réseau que le nœud principal. Nous l'avons nommé PG-Node-Witness et y avons installé une instance PostgreSQL 12. Dans cet article, nous y installerons également repmgr, mais nous en reparlerons plus tard.
Le deuxième composant de la solution est le démon repmgr (repmgrd) s'exécutant sur tous les nœuds du cluster et le nœud témoin. Encore une fois, nous n'avons pas démarré ce démon dans la première partie de cette série, mais nous le ferons ici. Le démon fait partie du package repmgr - lorsqu'il est activé, il s'exécute comme un service régulier et surveille en permanence la santé du cluster. Il initie un basculement lorsqu'un quorum est atteint sur le principal étant hors ligne. Non seulement peut-il promouvoir automatiquement un standby, mais il peut également réinitialiser d'autres standbys dans un cluster à plusieurs nœuds pour suivre le nouveau primaire .
Le processus de quorum
Lorsqu'un standby se rend compte qu'il ne peut pas voir le primaire, il consulte les autres standbys. Tous les standby en cours d'exécution dans le cluster atteignent un quorum pour choisir un nouveau primaire à l'aide d'une série de vérifications :
- Chaque standby interroge les autres standby sur la dernière fois qu'il a "vu" le primaire. Si le dernier LSN répliqué d'un standby ou l'heure de la dernière communication avec le primaire est plus récent que le dernier LSN répliqué du nœud actuel ou l'heure de la dernière communication, le nœud ne fait rien et attend que la communication avec le primaire soit restaurée
- Si aucun des standbys ne peut voir le primaire, ils vérifient si le nœud témoin est disponible. Si le nœud témoin ne peut pas non plus être atteint, les standby supposent qu'il y a une panne de réseau du côté primaire et ne procèdent pas au choix d'un nouveau primaire
- Si le témoin peut être joint, les standby supposent que le primaire est en panne et procèdent au choix d'un primaire
- Le nœud qui a été configuré comme nœud principal « préféré » sera alors promu. Chaque standby verra sa réplication réinitialisée pour suivre le nouveau primaire.
Configuration du cluster pour le basculement automatique
Nous allons maintenant configurer le cluster et le nœud témoin pour le basculement automatique.
Étape 1 :Installer et configurer repmgr dans Witness
Nous avons déjà vu comment installer le package repmgr dans notre dernier article. Nous le faisons également dans le nœud témoin :
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Et ensuite :
# yum install repmgr12 -y
Ensuite, nous ajoutons les lignes suivantes dans le fichier postgresql.conf du nœud témoin :
listen_addresses ='*'shared_preload_libraries ='repmgr'
Nous ajoutons également les lignes suivantes dans le fichier pg_hba.conf du nœud témoin. Notez comment nous utilisons la plage CIDR du cluster au lieu de spécifier des adresses IP individuelles.
Réplication locale Repmgr Trustthost Replication RepMGR 127.0.0.1/32 TRUSTHOST Replication RepMGR 16.0.0.0/16 TrustLocal RepMGR Repmgr Trusthost Repmgr REPMGRemarque
[Les étapes décrites ici sont uniquement à des fins de démonstration. Notre exemple ici utilise des adresses IP accessibles de l'extérieur pour les nœuds. L'utilisation de listen_address ='*' avec le mécanisme de sécurité "trust" de pg_hba pose donc un risque de sécurité et ne doit PAS être utilisé dans des scénarios de production. Dans un système de production, les nœuds seront tous à l'intérieur d'un ou plusieurs sous-réseaux privés, accessibles via des adresses IP privées à partir de jumphosts.]
Une fois les modifications postgresql.conf et pg_hba.conf effectuées, nous créons l'utilisateur repmgr et la base de données repmgr dans le témoin, et modifions le chemin de recherche par défaut de l'utilisateur repmgr :
[example@sqldat.comitness ~]$ createuser --superuser repmgr[example@sqldat.com ~]$ createdb --owner=repmgr repmgr[example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public ;"Enfin, nous ajoutons les lignes suivantes au fichier repmgr.conf, situé sous /etc/repmgr/12/
node_id =4nom_noeud ='PG-Node-Witness'conninfo ='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'répertoire_données ='/var/lib/pgsql/12/data'Une fois les paramètres de configuration définis, nous redémarrons le service PostgreSQL dans le nœud témoin :
# systemctl restart postgresql-12.servicePour tester la connectivité au nœud témoin repmgr, nous pouvons exécuter cette commande à partir du nœud principal :
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'Ensuite, nous enregistrons le nœud témoin auprès de repmgr en exécutant la commande « repmgr Witness Register » en tant qu'utilisateur postgres. Notez comment nous utilisons l'adresse du principal nœud, et NON le nœud témoin dans la commande ci-dessous :
[exemple@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf registre des témoins -h 16.0.1.156En effet, la commande "repmgr Witness Register" ajoute les métadonnées du nœud témoin à la base de données repmgr du nœud principal et, si nécessaire, initialise le nœud témoin en installant l'extension repmgr et en copiant les métadonnées repmgr sur le nœud témoin.
La sortie ressemblera à ceci :
INFO :connexion au nœud témoin "PG-Node-Witness" (ID : 4)INFO :connexion au nœud principalNOTICE :tentative d'installation de l'extension "repmgr"NOTICE :extension "repmgr" installée avec succèsINFO :enregistrement du témoin complet AVIS :nœud témoin "PG-Node-Witness" (ID : 4) réussi enregistréEnfin, nous vérifions l'état de la configuration globale à partir de n'importe quel nœud :
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compactLa sortie ressemble à ceci :
Étape 2 :Modifier le fichier sudoers
Avec le cluster et le témoin en cours d'exécution, nous ajoutons les lignes suivantes dans le fichier sudoers Dans chaque nœud du cluster et le nœud témoin :
Par défaut :postgres !requirettypostgres ALL =NOPASSWD :/usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service , /usr/bin/systemctl recharger postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.serviceÉtape 3 :Configuration des paramètres repmgrd
Nous avons déjà ajouté quatre paramètres dans le fichier repmgr.conf de chaque nœud. Les paramètres ajoutés sont les paramètres de base nécessaires au fonctionnement de repmgr. Pour activer le démon repmgr et le basculement automatique, un certain nombre d'autres paramètres doivent être activés/ajoutés. Dans les sous-sections suivantes, nous décrirons chaque paramètre et la valeur à laquelle il sera défini dans chaque nœud.
basculement
Le paramètre failover est l'un des paramètres obligatoires pour le démon repmgr. Ce paramètre indique au démon s'il doit lancer un basculement automatique lorsqu'une situation de basculement est détectée. Il peut avoir l'une ou l'autre des deux valeurs suivantes :« manuel » ou « automatique ». Nous allons définir cela sur automatique dans chaque nœud :
basculement ='automatique'promote_command
Il s'agit d'un autre paramètre obligatoire pour le démon repmgr. Ce paramètre indique au démon repmgr quelle commande il doit exécuter pour promouvoir un standby. La valeur de ce paramètre sera généralement la commande « repmgr standby promote » ou le chemin d'accès à un script shell qui appelle la commande. Pour notre cas d'utilisation, nous définissons ceci sur ce qui suit dans chaque nœud :
promote_command ='/usr/pgsql-12/bin/repmgr standby promouvoir -f /etc/repmgr/12/repmgr.conf --log-to-file'follow_command
Il s'agit du troisième paramètre obligatoire pour le démon repmgr. Ce paramètre indique à un nœud de secours de suivre le nouveau nœud principal. Le démon repmgr remplace l'espace réservé %n par l'ID de nœud du nouveau principal au moment de l'exécution :
follow_command ='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'priorité
Le paramètre de priorité ajoute du poids à l'éligibilité d'un nœud à devenir un nœud principal. La définition de ce paramètre sur une valeur plus élevée donne à un nœud une plus grande éligibilité pour devenir le nœud principal. De plus, définir cette valeur sur zéro pour un nœud garantira que le nœud n'est jamais promu en tant que nœud principal.
Dans notre cas d'utilisation, nous avons deux veilles :PG-Node2 et PG-Node3. Nous voulons promouvoir PG-Node2 en tant que nouveau principal lorsque PG-Node1 est hors ligne, et PG-Node3 pour suivre PG-Node2 en tant que nouveau principal. Nous définissons le paramètre sur les valeurs suivantes dans les deux nœuds de secours :

| Nom du nœud | Réglage des paramètres |
| PG-Node2 | priorité =60 |
| PG-Node3 | priorité =40 |
monitor_interval_secs
Ce paramètre indique au démon repmgr à quelle fréquence (en nombre de secondes) il doit vérifier la disponibilité du nœud en amont. Dans notre cas, il n'y a qu'un seul nœud en amont :le nœud primaire. La valeur par défaut est de 2 secondes, mais nous la définirons explicitement de toute façon dans chaque nœud :
monitor_interval_secs =2
connection_check_type
Le paramètre connection_check_type indique le protocole que le démon repmgr utilisera pour atteindre le nœud en amont. Ce paramètre peut prendre trois valeurs :
- ping :repmgr utilise la méthode PQPing()
- connexion :repmgr essaie de créer une nouvelle connexion au nœud amont
- requête :repmgr essaie d'exécuter une requête SQL sur le nœud amont en utilisant la connexion existante
Encore une fois, nous allons définir ce paramètre sur la valeur par défaut de ping dans chaque nœud :
connection_check_type ='ping'
reconnect_attempts et reconnect_interval
Lorsque le primaire devient indisponible, le démon repmgr dans les nœuds de secours tente de se reconnecter au primaire pendant reconnect_attempts fois. La valeur par défaut de ce paramètre est 6. Entre chaque tentative de reconnexion, il attendra reconnect_interval secondes, qui a une valeur par défaut de 10. À des fins de démonstration, nous utiliserons un intervalle court et moins de tentatives de reconnexion. Nous définissons ce paramètre dans chaque nœud :
reconnect_attempts =4reconnect_interval =8
primary_visibility_consensus
Lorsque le serveur principal devient indisponible dans un cluster à plusieurs nœuds, les serveurs de secours peuvent se consulter pour créer un quorum concernant un basculement. Cela se fait en demandant à chaque standby l'heure à laquelle il a vu le primaire pour la dernière fois. Si la dernière communication d'un nœud était très récente et postérieure au moment où le nœud local a vu le nœud principal, le nœud local suppose que le nœud principal est toujours disponible et ne prend pas de décision de basculement.
Pour activer ce modèle de consensus, le paramètre primary_visibility_consensus doit être défini sur "true" dans chaque nœud - y compris le témoin :
primary_visibility_consensus =vrai
standby_disconnect_on_failover
Lorsque le paramètre standby_disconnect_on_failover est défini sur "true" dans un nœud de secours, le démon repmgr s'assurera que son récepteur WAL est déconnecté du primaire et ne reçoit aucun segment WAL. Il attendra également que les récepteurs WAL des autres nœuds de secours s'arrêtent avant de prendre une décision de basculement. Ce paramètre doit être défini sur la même valeur dans chaque nœud. Nous le définissons sur "true".
standby_disconnect_on_failover =vrai
La définition de ce paramètre sur true signifie que chaque nœud de secours a cessé de recevoir des données du nœud principal au moment du basculement. Le processus aura un délai de 5 secondes plus le temps nécessaire au récepteur WAL pour s'arrêter avant qu'une décision de basculement ne soit prise. Par défaut, le démon repmgr attendra 30 secondes pour confirmer que tous les nœuds frères ont cessé de recevoir des segments WAL avant que le basculement ne se produise.
repmgrd_service_start_command et repmgrd_service_stop_command
Ces deux paramètres spécifient comment démarrer et arrêter le démon repmgr à l'aide des commandes "repmgr daemon start" et "repmgr daemon stop".
Fondamentalement, ces deux commandes sont des enveloppes autour des commandes du système d'exploitation pour démarrer/arrêter le service. Les deux valeurs de paramètre mappent ces commandes à leurs versions spécifiques au système d'exploitation. Nous définissons ces paramètres sur les valeurs suivantes dans chaque nœud :
repmgrd_service_start_command ='sudo /usr/bin/systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo /usr/bin/systemctl stop repmgr12.service'
Commandes de démarrage/arrêt/redémarrage du service PostgreSQL
Dans le cadre de son fonctionnement, le démon repmgr devra souvent arrêter, démarrer ou redémarrer le service PostgreSQL. Pour garantir que cela se passe sans problème, il est préférable de spécifier les commandes du système d'exploitation correspondantes en tant que valeurs de paramètre dans le fichier repmgr.conf. Nous allons définir quatre paramètres dans chaque nœud à cet effet :
service_start_command ='sudo /usr/bin/systemctl start postgresql-12.service'service_stop_command ='sudo /usr/bin/systemctl stop postgresql-12.service'service_restart_command ='sudo /usr/bin/systemctl restart postgresql-12.service'service_reload_command ='sudo /usr/bin/systemctl recharger postgresql-12.service'
monitoring_history
La définition du paramètre monitoring_history sur "yes" garantira que repmgr enregistre ses données de surveillance de cluster. Nous définissons ceci sur "oui" dans chaque nœud :
monitoring_history =oui
log_status_interval
Nous définissons le paramètre dans chaque nœud pour spécifier la fréquence à laquelle le démon repmgr enregistrera un message d'état. Dans ce cas, nous définissons ceci sur toutes les 60 secondes :
log_status_interval =60
Étape 4 :Démarrage du démon repmgr
Une fois les paramètres définis dans le cluster et le nœud témoin, nous exécutons une exécution à blanc de la commande pour démarrer le démon repmgr. Nous testons d'abord cela dans le nœud principal, puis dans les deux nœuds de secours, suivis du nœud témoin. La commande doit être exécutée en tant qu'utilisateur postgres :
[exemple@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf démarrage du démon --dry-run
Le résultat devrait ressembler à ceci :
INFO :prérequis pour démarrer repmgrd satisfaits DÉTAIL :la commande suivante sera exécutée : sudo /usr/bin/systemctl start repmgr12.service
Ensuite, nous démarrons le démon dans les quatre nœuds :
[exemple@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf démarrage du démon
La sortie de chaque nœud doit indiquer que le démon a démarré :
AVIS :exécution :"sudo /usr/bin/systemctl start repmgr12.service"AVIS :repmgrd a été démarré avec succès
Nous pouvons également vérifier l'événement de démarrage du service à partir des nœuds principaux ou de secours :
[exemple@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf événement de cluster --event=repmgrd_start
La sortie doit montrer que le démon surveille les connexions :
ID de nœud | Nom | Événement | D'accord | Horodatage | Détails--------+-----------------+---------------+----+- --------------------+-------------------------------------- -------------------------------------4 | PG-Noeud-Témoin | repmgrd_start | t | 2020-02-05 11:37:31 | connexion de surveillance des témoins au nœud principal "PG-Node1" (ID : 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | surveillance de la connexion au nœud en amont "PG-Node1" (ID : 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | surveillance de la connexion au nœud en amont "PG-Node1" (ID : 1) 1 | PG-Nœud1 | repmgrd_start | t | 2020-02-05 11:37:14 | cluster de surveillance primaire "PG-Node1" (ID :1)
Enfin, nous pouvons vérifier la sortie du démon du syslog dans l'une des veilles :
# chat /var/log/messages | grep repmgr | moins
Voici la sortie de PG-Node3 :
5 février 11:37:24 PG-Node3 repmgrd[2014] :[2020-02-05 11:37:24] [AVIS] à l'aide du fichier de configuration fourni "/etc/repmgr/12/repmgr.conf"février 5 11:37:24 PG-Node3 repmgrd[2014] :[2020-02-05 11:37:24] [AVIS] repmgrd (repmgrd 5.0.0) démarrage 5 février 11:37:24 PG-Node3 repmgrd[2014] :[2020-02-05 11:37:24] [INFO] connexion à la base de données "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2"février 5 11:37:24 PG-Node3 systemd[1] :repmgr12.service :impossible d'ouvrir le fichier PID /run/repmgr/repmgrd-12.pid (encore ?) après le démarrage :aucun fichier ou répertoire de ce type5 février 11:37 :24 PG-Node3 repmgrd[2014] :INFO : set_repmgrd_pid() :le fichier pid fourni est /run/repmgr/repmgrd-12.pid 5 février 11:37:24 PG-Node3 repmgrd[2014] : [2020-02-05 11:37:24] [AVIS] démarrage de la surveillance du nœud "PG-Node3" (ID : 3) 5 février 11:37:24 PG-Node3 repmgrd[2014] :[2020-02-05 11:37:24] [INFO] "connection_check_type" défini sur "ping" 5 février 11:37:24 PG-Node3 repmgrd[2014] : [2020-02-05 11:37:24] [INFO] surveillance de la connexion au nœud en amont "PG-Node1" (ID : 1) 5 février 11:38:25 PG-Node3 repmgrd[2014] :[2020-02-05 11:38:25] [INFO] nœud "PG-Node3" (ID : 3) surveillant le nœud en amont "PG- Node1" (ID : 1) à l'état normal 5 février 11:38:25 PG-Node3 repmgrd[2014] : [2020-02-05 11:38:25] [DETAIL] la dernière mise à jour des statistiques de surveillance remonte à 2 secondes 5 février 11:39:26 PG-Node3 repmgrd[2014] : [2020-02-05 11:39:26] [INFO] nœud "PG-Node3" (ID : 3) surveillant le nœud en amont "PG- Node1" (ID : 1) à l'état normal … …
La vérification du journal système dans le nœud principal affiche un type de sortie différent :
5 février 11:37:14 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:14] [AVIS] à l'aide du fichier de configuration fourni "/etc/repmgr/12/repmgr.conf"février 5 11:37:14 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:14] [AVIS] repmgrd (repmgrd 5.0.0) démarrage 5 février 11:37:14 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:14] [INFO] connexion à la base de données "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2"février 5 11:37:14 PG-Node1 repmgrd[2017] : [2020-02-05 11:37:14] [AVIS] démarrage de la surveillance du nœud "PG-Node1" (ID : 1) 5 février 11:37:14 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:14] [INFO] "connection_check_type" défini sur "ping" 5 février 11:37:14 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:14] [AVIS] cluster de surveillance principal "PG-Node1" (ID :1) 5 février 11:37:14 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:14] [INFO] le nœud enfant "PG-Node-Witness" (ID :4) n'est pas encore attaché5 février 11 :37:14 PG-Node1 repmgrd[2017] : [2020-02-05 11:37:14] [INFO] le nœud enfant "PG-Node3" (ID : 3) est attaché 5 février 11:37:14 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:14] [INFO] le nœud enfant "PG-Node2" (ID :2) est attaché 5 février 11:37:32 PG-Node1 repmgrd[2017] :[2020-02-05 11:37:32] [AVIS] le nouveau témoin "PG-Node-Witness" (ID : 4) s'est connecté 5 février 11:38:14 PG-Node1 repmgrd[2017] : [2020-02-05 11:38:14] [INFO] surveillance du nœud principal "PG-Node1" (ID : 1) à l'état normal 5 février 11:39:15 PG-Node1 repmgrd[2017] : [2020-02-05 11:39:15] [INFO] surveillance du nœud principal "PG-Node1" (ID : 1) à l'état normal … …
Étape 5 : simuler un échec principal
Nous allons maintenant simuler un nœud principal défaillant en arrêtant le nœud principal (PG-Node1). Depuis l'invite du shell du nœud, nous exécutons la commande suivante :
# systemctl stop postgresql-12.service
Le processus de basculement
Une fois le processus arrêté, nous attendons environ une minute ou deux, puis vérifions le fichier syslog de PG-Node2. Les messages suivants s'affichent. Pour plus de clarté et de simplicité, nous avons des groupes de messages codés par couleur et ajouté des espaces blancs entre les lignes :
… 5 février 11:53:36 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:36] [AVERTISSEMENT] impossible d'envoyer un ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 février 11:53:36 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:36] [ DÉTAIL] PQping() a renvoyé "PQPING_NO_RESPONSE" 5 février 11:53:36 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:36] [INFO] veille 8 secondes jusqu'à la prochaine tentative de reconnexion 5 février 11:53:44 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:44] [INFO] vérification de l'état du nœud 1, 2 tentatives sur 4 5 février 11:53:44 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:44] [AVERTISSEMENT] impossible d'envoyer un ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 février 11:53:44 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:44] [ DÉTAIL] PQping() a renvoyé "PQPING_NO_RESPONSE" 5 février 11:53:44 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:44] [INFO] veille 8 secondes jusqu'à la prochaine tentative de reconnexion 5 février 11:53:52 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:52] [INFO] vérification de l'état du nœud 1, 3 tentatives sur 4 5 février 11:53:52 PG-Node2 repmgrd[2165] : [2020-02-05 11:53:52] [AVERTISSEMENT] impossible d'envoyer un ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 février 11:53:52 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:52] [ DÉTAIL] PQping() a renvoyé "PQPING_NO_RESPONSE" 5 février 11:53:52 PG-Node2 repmgrd[2165] :[2020-02-05 11:53:52] [INFO] veille 8 secondes jusqu'à la prochaine tentative de reconnexion 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] vérification de l'état du nœud 1, 4 tentatives sur 4 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVERTISSEMENT] impossible d'envoyer un ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [ DÉTAIL] PQping() a renvoyé "PQPING_NO_RESPONSE" 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVERTISSEMENT] impossible de se reconnecter au nœud 1 après 4 tentatives 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVIS] définition de "wal_retrieve_retry_interval" sur 86405000 millisecondes 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVERTISSEMENT] le récepteur wal ne fonctionne pas 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVIS] Récepteur WAL déconnecté sur tous les nœuds frères 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] Récepteur WAL déconnecté sur les 2 nœuds frères 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] dernier LSN de réception du nœud local :0/2214A000 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] vérification de l'état du nœud frère "PG-Node3" (ID :3) 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] le nœud "PG-Node3" (ID :3) signale que son amont est le nœud 1 , vu pour la dernière fois il y a 26 seconde(s) 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] le nœud 3 a vu pour la dernière fois le nœud principal il y a 26 secondes 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] le dernier LSN reçu pour le nœud frère "PG-Node3" (ID : 3) est :0/2214A000 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] le nœud "PG-Node3" (ID :3) a le même LSN que le candidat actuel "PG-Node2" (ID :2) 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] le nœud "PG-Node3" (ID : 3) a une priorité inférieure (40) que le candidat actuel "PG-Node2" (ID :2) (60) 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] vérification de l'état du nœud frère "PG-Node-Witness" (ID :4) 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] nœud "PG-Node-Witness" (ID :4) signale que son amont est nœud 1, vu pour la dernière fois il y a 26 secondes 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [INFO] le nœud 4 a vu pour la dernière fois le nœud principal il y a 26 secondes 5 février 11:54:00 PG-Node2 repmgrd[2165] : [2020-02-05 11:54:00] [INFO] nœuds visibles :3 ; nœuds totaux :3 ; aucun nœud n'a vu le nœud principal au cours des 4 dernières secondes …… 5 février 11:54:00 PG-Node2 repmgrd[2165] : [2020-02-05 11:54:00] [AVIS] le candidat à la promotion est "PG-Node2" (ID : 2) 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVIS] réglage de "wal_retrieve_retry_interval" sur 5 000 ms 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVIS] ce nœud est le gagnant, va maintenant se promouvoir et informer les autres nœuds …… 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVIS] promotion de la veille à l'état principal 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [DETAIL] promotion du serveur "PG-Node2" (ID :2) à l'aide de pg_promote() 5 février 11:54:00 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:00] [AVIS] attendre jusqu'à 60 secondes (paramètre "promote_check_timeout") pour que la promotion se termine 5 février 11:54:01 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:01] [AVIS] PROMOTION EN VEILLE réussie 5 février 11:54:01 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:01] [DETAIL] le serveur "PG-Node2" (ID : 2) a été promu avec succès au statut principal 5 février 11:54:01 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:01] [INFO] 2 abonnés à notifier 5 février 11:54:01 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:01] [AVIS] notifiant le nœud "PG-Node3" (ID : 3) pour suivre le nœud 2 5 février 11:54:01 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:01] [AVIS] notifiant le nœud "PG-Node-Witness" (ID : 4) pour suivre le nœud 2 5 février 11:54:01 PG-Node2 repmgrd[2165] : [2020-02-05 11:54:01] [INFO] passage au mode de surveillance principal 5 février 11:54:01 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:01] [AVIS] cluster de surveillance principal "PG-Node2" (ID :2) 5 février 11:54:07 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:07] [AVIS] le nouveau témoin "PG-Node-Witness" (ID : 4) s'est connecté 5 février 11:54:07 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:07] [AVIS] le nouveau "PG-Node3" de secours (ID : 3) s'est connecté 5 février 11:54:07 PG-Node2 repmgrd[2165] :[2020-02-05 11:54:07] [AVIS] le nouveau "PG-Node3" de secours (ID :3) s'est connecté 5 février 11:55:02 PG-Node2 repmgrd[2165] :[2020-02-05 11:55:02] [INFO] surveillance du nœud principal "PG-Node2" (ID : 2) à l'état normal Feb 5 11:56:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID:2) in normal state … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
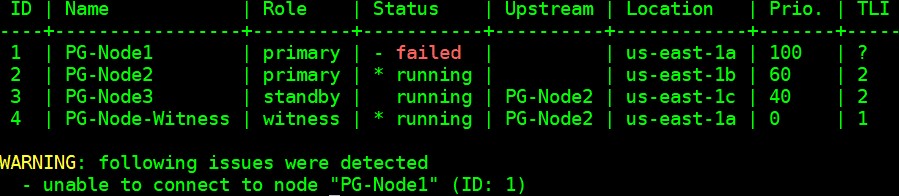
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | D'accord | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID:2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID:3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID:4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID:2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID:2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID:2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID:4) has connected
Conclusion
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1