Au cours des derniers mois, chez 2ndQuadrant, nous avons travaillé sur la fusion de PostgreSQL 9.6 dans Postgres-XL, ce qui s'est avéré assez difficile pour diverses raisons, et a pris plus de temps que prévu initialement en raison de plusieurs changements invasifs en amont. Si vous êtes intéressé, regardez le dépôt officiel ici (regardez la branche "master" pour l'instant).
Il reste encore pas mal de travail à faire - fusionner quelques bits restants de l'amont, corriger les bogues connus et les échecs de régression, tester, etc. Si vous envisagez de contribuer à Postgres-XL, c'est une opportunité idéale (envoyez-moi un e-mail et je vous aiderai avec les premières étapes).
Mais dans l'ensemble, Postgres-XL 9.6 est clairement une avancée majeure dans un certain nombre de domaines importants.
Nouvelles fonctionnalités de Postgres-XL 9.6
Alors, quelles nouvelles fonctionnalités PostgreSQL bénéficie-t-il de la fusion de PostgreSQL 9.6 ? Je pourrais simplement vous indiquer les notes de version en amont - la plupart des améliorations s'appliquent directement à XL 9.6, à l'exception de celles liées aux fonctionnalités non prises en charge sur XL.
La principale amélioration visible par l'utilisateur dans PostgreSQL 9.6 était clairement la requête parallèle, et cela s'applique également à PostgreSQL-XL 9.6.
Parallélisme intra-nœud
Avant PostgreSQL 9.6, PostgreSQL était l'un des moyens d'obtenir des requêtes parallèles (en plaçant plusieurs nœuds PostgreSQL sur la même machine). Depuis PostgreSQL 9.6, ce n'est plus nécessaire, mais cela signifie également que PostgreSQL bénéficie d'une capacité de parallélisme intra-nœud.
À titre de comparaison, c'est ce que PostgreSQL 9.5 vous permettait de faire :distribuer une requête à plusieurs nœuds de données, mais chaque nœud de données était toujours soumis à la limite "un backend par requête", tout comme PostgreSQL.
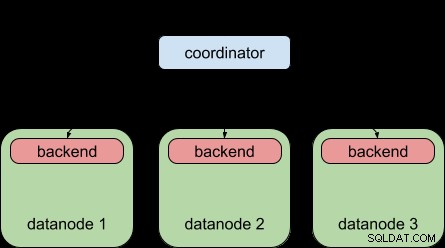
Grâce à la fonctionnalité de requête parallèle de PostgreSQL 9.6, PostgreSQL 9.6 peut désormais faire ceci :
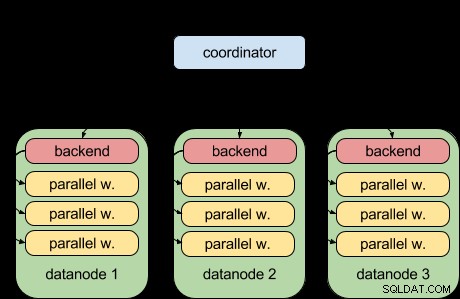
Autrement dit, chaque nœud de données peut désormais exécuter sa partie de la requête en parallèle, en utilisant l'infrastructure de requête parallèle en amont. C'est formidable et rend Postgres-XL beaucoup plus puissant en ce qui concerne les charges de travail analytiques.
Maintenir un fork
J'ai mentionné que cette fusion s'est avérée plus difficile que prévu initialement, pour un certain nombre de raisons.
Premièrement, la maintenance des forks en général est difficile, en particulier lorsque le projet en amont évolue aussi rapidement que PostgreSQL. Vous devez développer des fonctionnalités spécifiques à votre fork, c'est pourquoi les forks existent en premier lieu. Mais vous voulez aussi suivre l'amont, sinon vous êtes désespérément en retard. C'est pourquoi certains des forks existants sont toujours bloqués sur PostgreSQL 8.x, manquant tous les goodies commis depuis lors.
Deuxièmement, la fusion s'est faite en un gros bloc, comme toutes les précédentes (9.5, 9.2, …). Autrement dit, tous les commits en amont ont été fusionnés dans une seule commande git merge. Cela est pratiquement garanti pour provoquer de nombreux conflits de fusion, dans la mesure où le code ne se compile même pas, sans parler de l'exécution de tests de régression ou de quelque chose du genre.
Ainsi, le premier lot de correctifs consiste à le mettre dans un état compilable, le lot suivant consiste à le faire fonctionner sans erreurs de segmentation immédiates, puis enfin la correction "régulière" commence (exécuter des tests de régression, résoudre les problèmes, rincer et répéter) .
Ces complexités sont inhérentes à la maintenance du fork (et une raison pour laquelle vous devriez probablement reconsidérer le démarrage d'un autre fork, et à la place contribuer directement soit à Postgres et/ou Postgres-XL).
Mais il existe des moyens de réduire considérablement l'impact - par exemple, nous prévoyons de faire la prochaine fusion (avec PostgreSQL 10) en plus petits morceaux. Cela devrait minimiser l'ampleur des conflits de fusion et nous permettre de résoudre les échecs beaucoup plus rapidement.
Plus proche de PostgreSQL
Chose intéressante, l'adoption du parallélisme depuis l'amont nous a également permis de nous débarrasser d'une grande partie du code de la base de code XL - un excellent exemple en est le code agrégé parallèle, qui a facilement remplacé le code spécifique à XL.
Un autre exemple de changement en amont qui a affecté de manière significative le code XL est la "pathification" du planificateur supérieur, poussée à la fin du cycle de développement 9.6. Cela s'est avéré être un changement très invasif (en fait, un certain nombre de bogues ouverts y sont probablement liés), mais cela nous a finalement permis de simplifier le code de planification (essentiellement de construire des chemins appropriés au lieu de peaufiner le plan résultant).
Quand je dis que la fusion nous a permis de simplifier le code XL et de le rapprocher de PostgreSQL, qu'est-ce que je veux dire par là ? Le moyen le plus simple de quantifier le changement est de faire « git diff –stat » par rapport à la branche en amont correspondante et de comparer les chiffres. Pour les branches 9.5 et 9.6, les résultats ressemblent à ceci :
| version | fichiers modifiés | ajouts | suppressions |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3 %) | -33351 (-14.2%) | -709 (-3,8 %) |
Clairement, la fusion 9.6 réduit significativement le delta par rapport à l'amont (de ~14% au total). D'où vient cette différence ?
Premièrement, une partie de cette réduction est due à une véritable simplification du code. Un excellent exemple de ceci est l'agrégat parallèle, qui est à peu près un remplacement 1:1 de l'implémentation originale de Postgres-XL. Nous venons donc de supprimer cela et d'utiliser l'implémentation en amont à la place. Nous espérons trouver d'autres lieux de ce type à l'avenir et utiliser la mise en œuvre en amont au lieu de maintenir la nôtre.
Deuxièmement, une grande partie de la réduction provient de la suppression du code mort. Non seulement nous avons réduit certains morceaux de code morts/inaccessibles, mais nous avons également découvert un certain nombre de fichiers sources qui n'ont même pas été compilés, et ainsi de suite.
Quelle est la prochaine ?
À ce stade, nous avons fusionné les modifications jusqu'à b5bce6c1, qui est l'endroit où PostgreSQL 9.6 s'est séparé de master. Donc, pour rattraper PostgreSQL 9.6.2, nous devons fusionner les modifications restantes dans la branche 9.6. Considérant qu'il ne devrait y avoir que des corrections de bogues, cela devrait être un travail (espérons-le) assez simple par rapport à la fusion complète.
Bien sûr, il y aura des bugs. En fait, il y a encore quelques tests de régression qui échouent à ce stade. Cela doit être corrigé avant de faire une version officielle de XL 9.6. Et nous devons faire plus de tests, donc si vous êtes intéressé à aider Postgres-XL, ce serait extrêmement bénéfique.
L'un des désagréments dont nous entendons sans cesse parler, ce sont les colis, ou leur absence. Vous avez peut-être remarqué que les derniers packages disponibles sont assez anciens et qu'il n'y a que .rpm, rien d'autre. Nous prévoyons de résoudre ce problème et de commencer à proposer des packages à jour dans plusieurs versions (par exemple, .rpm et .deb).
Nous prévoyons également d'apporter quelques modifications à l'organisation du processus de développement, afin de faciliter la contribution et la participation au processus de développement. C'est vraiment un sujet distinct sans rapport avec la branche 9.6, donc je publierai plus de détails à ce sujet dans quelques jours.