Il y a tellement de choses à dire sur l'histoire et l'importance. Histoire d'un pays, d'une civilisation, de chacun de nous. J'adore les citations et j'aime celle-ci de Teddy Roosevelt (mec cool) :
Plus vous en savez sur le passé, mieux vous êtes préparé pour l'avenir.Pourquoi suis-je en train de devenir poétique (ou d'essayer de le faire) sur l'histoire dans un blog sur SQL Server ? Parce que l'historique dans SQL Server est également important. Lorsqu'un problème de performances existe dans SQL Server, il est idéal de résoudre le problème en direct, mais dans certains cas, les informations historiques peuvent fournir un pistolet fumant, ou au moins un point de départ. Une excellente source d'informations historiques dans SQL Server est le ERRORLOG. J'ai mentionné dans mon article original, Performance Issues:The First Encounter, que l'ERRORLOG était une réflexion après coup pour moi. Pas plus. Lors des audits clients, nous capturons toujours les ERRORLOG, et bien que nous soyons avertis de toute alerte de haute gravité (qui est écrite dans le journal), il n'est pas rare de trouver d'autres informations intéressantes dans le journal. Nous préparons l'avenir en utilisant les informations historiques dans les journaux ; ces informations peuvent nous aider à résoudre un problème, ou un problème potentiel, avant qu'il ne devienne catastrophique.
Affichage du ERRORLOG
Tout d'abord, nous allons passer en revue certaines options pour afficher l'ERROLOG. Si je suis connecté à une instance, j'y accède généralement via SSMS (Gestion | Journaux SQL Server, cliquez avec le bouton droit sur un journal et sélectionnez Afficher le journal SQL Server). À partir de cette fenêtre, je peux simplement faire défiler le journal ou utiliser les options Filtrer ou Rechercher pour affiner le jeu de résultats. Je peux également afficher plusieurs fichiers en les sélectionnant dans le volet de gauche.
Si je regarde les données capturées dans l'un de nos audits de santé, j'ouvre simplement les fichiers journaux dans un éditeur de texte et je les examine (j'ai la possibilité d'accéder à la visionneuse et de les charger également). Les fichiers journaux existent dans le dossier du journal (emplacement par défaut :C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\Log) si jamais je voulais les consulter sur le serveur. Beaucoup d'entre vous préféreront peut-être afficher et/ou rechercher le journal à l'aide de la procédure non documentée sp_readerrorlog ou de la procédure stockée étendue xp_readerrorlog.
Et enfin, si vous êtes tous dans PowerShell, c'est aussi une option pour lire le journal de cette façon (voir ce post :Utiliser PowerShell pour analyser les journaux d'erreurs SQL Server 2012). La méthode dépend de vous - utilisez ce que vous savez et ce qui fonctionne pour vous - c'est le contenu qui compte vraiment. Et rappelez-vous qu'il y a des moments où vous devrez simplement lire le journal pour comprendre l'ordre des événements, et il y a d'autres moments où vous pourriez chercher pour trouver une erreur ou une information spécifique.
Que contient le ERRORLOG ?
Alors, quelles informations pouvons-nous trouver dans l'ERRORLOG, en plus des erreurs ? J'ai énuméré ci-dessous bon nombre des éléments que j'ai trouvés les plus utiles. Notez que ce n'est pas une liste exhaustive (et je suis sûr que beaucoup d'entre vous auront des suggestions sur ce qui pourrait être ajouté - n'hésitez pas à poster un commentaire et je peux le mettre à jour !), mais encore une fois, c'est ce que je suis cherche premier lorsque je regarde une instance de manière proactive.
- Si le serveur est physique ou virtuel (recherchez l'entrée du fabricant du système)
- Indicateurs de trace activés au démarrage
- Dans l'entrée des paramètres de démarrage du registre, si vous faites défiler tout le chemin vers la droite, vous verrez si des indicateurs de trace sont activés :
 Drapeaux de trace activés au démarrage
Drapeaux de trace activés au démarrage
- Dans l'entrée des paramètres de démarrage du registre, si vous faites défiler tout le chemin vers la droite, vous verrez si des indicateurs de trace sont activés :
- Indicateurs de trace activés ou désactivés après le démarrage de l'instance
- Si les utilisateurs (ou une application) activent ou désactivent un indicateur de trace à l'aide de DBCC TRACEON ou DBCC TRACEOFF, une entrée apparaît dans le journal
- Nombre de cœurs et de sockets détectés par SQL Server
- J'aime toujours vérifier que SQL Server voit tout le matériel disponible - et si ce n'est pas le cas, c'est un signal d'alarme à approfondir. Pour un bon exemple, consultez l'article de Jonathan, Problèmes de performances avec SQL Server 0212 Enterprise Edition sous licence CAL, et l'article de Glenn, Équilibrage de vos licences principales SQL Server disponibles uniformément sur les nœuds NUMA, qui comprend également quelques TSQL pratiques pour interroger le journal.
- Notez que le texte de cette entrée varie selon les versions de SQL Server.
- Quantité de mémoire détectée par SQL Server
- Encore une fois, je veux vérifier que SQL Server voit toute la mémoire disponible.
- Confirmation que les pages verrouillées en mémoire (LPIM) sont activées
- Bien que cette option soit activée via la politique de sécurité Windows, vous pouvez confirmer qu'elle est activée en recherchant le message "Utilisation des pages verrouillées dans le gestionnaire de mémoire" dans le journal.
- Notez que si vous utilisez Trace Flag 834, le message n'indiquera pas les pages verrouillées, il indiquera que de grandes pages sont utilisées pour le pool de mémoire tampon.
- Version du CLR utilisée
- Réussite ou échec de l'enregistrement du nom principal du service (SPN)
- Combien de temps faut-il pour qu'une base de données soit mise en ligne
- Le journal enregistre le démarrage de la base de données et sa mise en ligne. Je vérifie si une base de données met trop de temps à s'afficher.
- État des points de terminaison Service Broker et Database Mirroring :important si vous utilisez l'une ou l'autre de ces fonctionnalités
- Confirmation que l'initialisation instantanée du fichier (IFI) est activée*
- Par défaut, ces informations ne sont pas enregistrées, mais si vous activez Trace Flag 3004 (et 3605 pour forcer la sortie dans le journal), lorsque vous créez ou développez un fichier de données, vous verrez des messages dans le journal pour indiquer si IFI est en cours d'utilisation ou non.
- État des traces SQL
- Lorsque vous démarrez ou arrêtez une trace SQL, elle est enregistrée et je regarde si des traces au-delà de la trace par défaut existent (temporairement ou à long terme). Si vous exécutez un outil de surveillance tiers, tel que Performance Advisor de SQL Sentry, vous pouvez voir une trace active qui est toujours en cours d'exécution, mais ne capturant que des événements spécifiques, ou vous pouvez voir une trace démarrer, s'exécuter pendant une courte durée, puis arrêt. Je ne suis pas préoccupé par une ou deux traces supplémentaires, à moins qu'elles ne capturent beaucoup d'événements, mais je fais vraiment attention lorsque plusieurs traces sont en cours d'exécution.
- La dernière fois que CHECKDB a été terminé
- Ce message est souvent mal compris par les utilisateurs :lorsque l'instance démarre, elle lit la page de démarrage de chaque base de données et note la dernière exécution réussie de CHECKDB. La plupart des gens ne lisent pas le message en entier :
 Date à laquelle DBCC CHECKDB a réussi pour la dernière fois
Date à laquelle DBCC CHECKDB a réussi pour la dernière fois La date d'achèvement de CHECKDB est le 11 novembre 2012, mais la date ERRORLOG est le 7 juillet 2015. Il est important de comprendre que SQL Server ne le fait pas exécutez CHECKDB sur les bases de données au démarrage, il vérifie la valeur dbcclastknowngood sur la page de démarrage (pour voir quand cela est mis à jour, consultez mon article, What Checks Update dbcclastknowngood. De plus, si DBCC CHECKDB n'a jamais été exécuté sur une base de données, alors aucune entrée apparaîtra pour la base de données ici.
- Ce message est souvent mal compris par les utilisateurs :lorsque l'instance démarre, elle lit la page de démarrage de chaque base de données et note la dernière exécution réussie de CHECKDB. La plupart des gens ne lisent pas le message en entier :
- achèvement de CHECKDB
- Lorsque CHECKDB est exécuté sur une base de données, la sortie est enregistrée dans le journal.
- Modifications des paramètres d'instance
- Si vous modifiez un paramètre au niveau de l'instance (par exemple, la mémoire maximale du serveur, le seuil de coût pour le parallélisme) à l'aide de sp_configure ou via l'interface utilisateur (notez qu'il n'enregistre pas qui changé).
- Modifications des paramètres de la base de données
- Quelqu'un a-t-il activé AUTO_SHRINK ? Changer l'option RECOVERY en SIMPLE puis revenir en FULL ? Vous le trouverez ici.
- Modifications de l'état de la base de données
- Si quelqu'un prend une base de données HORS LIGNE (ou la met EN LIGNE), cela est enregistré.
- Informations sur les interblocages*
- Si vous avez besoin de capturer des informations sur les interblocages, vous ne souhaitez pas exécuter de trace, et vous exécutez SQL Server 2005 à 2008R2, utilisez l'indicateur de trace 1222 pour écrire les informations de blocage dans le journal au format XML. Pour ceux d'entre vous qui utilisent SQL Server 2000 et versions antérieures, vous pouvez tracer l'indicateur 1204 (cet indicateur de trace est également disponible dans SQL Server 2005+, mais il génère des informations minimales). Si vous utilisez SQL Server 2012 ou une version ultérieure, cela n'est pas nécessaire, car la session d'événements system_health capture ces informations (et elles sont également présentes en 2008 et 20082, mais vous devez les extraire du ring_buffer par rapport à la cible event_file).
- Messages FlushCache
- Si le cache est vidé par SQL Server parce que le processus de point de contrôle dépasse l'intervalle de récupération de la base de données, vous verrez un ensemble de messages FlushCache dans le journal (voir cet article de Bob Dorr pour plus d'informations). Ne confondez pas ces messages avec ceux qui s'affichent lorsque vous exécutez DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE :
 Message après l'exécution de DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE
Message après l'exécution de DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE
- Si le cache est vidé par SQL Server parce que le processus de point de contrôle dépasse l'intervalle de récupération de la base de données, vous verrez un ensemble de messages FlushCache dans le journal (voir cet article de Bob Dorr pour plus d'informations). Ne confondez pas ces messages avec ceux qui s'affichent lorsque vous exécutez DBCC FREEPROCCACHE ou DBCC FREESYSTEMCACHE :
- Messages de déchargement AppDomain
- Le journal note également quand les AppDomains sont créés, et vous ne verrez l'un ou l'autre que si vous utilisez CLR. Si je vois des messages de déchargement d'AppDomain en raison de la pression de la mémoire, c'est quelque chose à approfondir.
Il y a d'autres informations dans le journal qui sont utiles, telles que le mode d'authentification utilisé, si la connexion administrateur dédiée (DAC) est activée ou non, etc. J'ai discuté plus tôt (Vérifications proactives de l'état de SQL Server, Partie 3 :Paramètres de l'instance et de la base de données).
Qu'est-ce qu'il n'y a pas dans l'ERROLOG auquel vous pourriez vous attendre ?
Ceci est une courte liste, pour l'instant, car je suppose que certains d'entre vous ont peut-être trouvé d'autres choses que vous pensiez être dans le journal, mais qui ne l'étaient pas…
- Ajouter ou supprimer des fichiers ou des groupes de fichiers de base de données
- Démarrage ou arrêt des sessions d'événements étendus
- Cependant, si vous déployez un déclencheur DDL ou une notification d'événement au niveau du serveur, vous pouvez consigner ces informations. Voir le post de Jonathan, Logging Extended Events changes to the ERRORLOG, pour plus de détails.
- L'exécution de DBCC DROPCLEANBUFFERS apparaît dans le ERRORLOG
Gestion du journal
N'oubliez pas que, par défaut, SQL Server ne conserve que les six (6) fichiers journaux les plus récents (en plus du fichier actuel) et que le fichier journal est renouvelé à chaque redémarrage de SQL Server. Par conséquent, vous pouvez parfois avoir des fichiers journaux extrêmement volumineux qui prennent un certain temps à s'ouvrir et sont difficiles à parcourir. D'un autre côté, si vous rencontrez un cas où l'instance est redémarrée plusieurs fois, vous risquez de perdre des informations importantes. Il est recommandé d'augmenter le nombre de fichiers conservés à une valeur plus élevée (par exemple, 30) et de créer une tâche d'agent pour remplacer le fichier une fois par semaine à l'aide de sp_cycle_errorlog.
Outre la gestion des fichiers, vous pouvez affecter les informations écrites dans le journal. L'une des entrées les plus courantes qui crée de l'encombrement dans le ERRORLOG est l'entrée de sauvegarde réussie :
 Sauvegarde terminée avec succès
Sauvegarde terminée avec succès
Si vous avez une instance avec de nombreuses bases de données et que les sauvegardes du journal des transactions sont effectuées avec une quelconque régularité (par exemple, toutes les 15 minutes), vous verrez le journal se remplir rapidement de messages, ce qui rend plus difficile la recherche d'un véritable problème. Heureusement, vous pouvez utiliser l'indicateur de trace 3226 pour désactiver les messages de sauvegarde réussie (les erreurs apparaîtront toujours dans le journal et toutes les entrées existeront toujours dans msdb).
Un autre ensemble de messages qui encombrent le journal sont les messages de connexion réussie. Il s'agit d'une option que vous configurez pour l'instance dans l'onglet Sécurité :
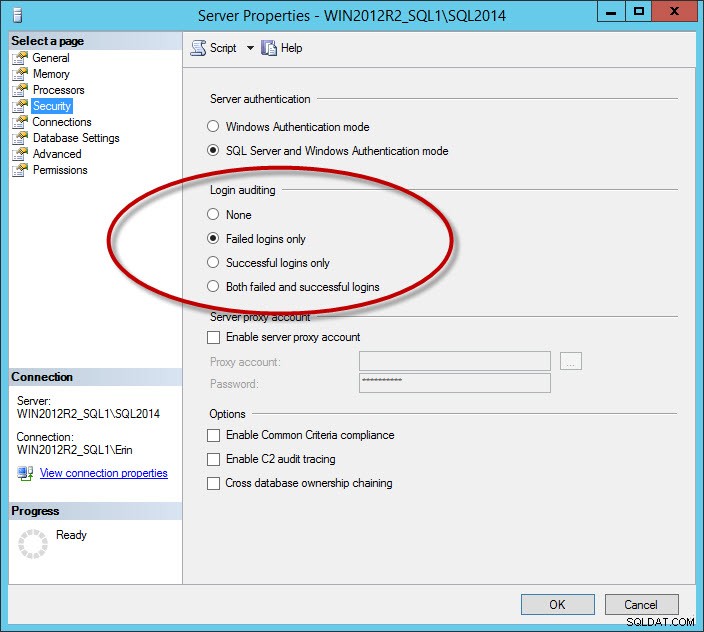 Option de sécurité pour enregistrer les connexions réussies et/ou échouées
Option de sécurité pour enregistrer les connexions réussies et/ou échouées
Si vous enregistrez des connexions réussies ou des connexions échouées et réussies, vous pouvez avoir des fichiers journaux très volumineux, même si vous remplacez les fichiers quotidiennement (cela dépendra du nombre d'utilisateurs qui se connectent). Je recommande de ne capturer que les connexions ayant échoué. Pour les entreprises qui doivent enregistrer les connexions réussies, envisagez d'utiliser la fonctionnalité d'audit, ajoutée dans SQL Server 2008. Remarque :si vous modifiez le paramètre d'audit de connexion, il ne prendra effet qu'au redémarrage de l'instance.
Ne sous-estimez pas le ERRORLOG
Comme vous pouvez le constater, le ERRORLOG contient d'excellentes informations que vous pouvez utiliser non seulement lorsque vous dépannez des performances ou recherchez des erreurs, mais également lorsque vous surveillez de manière proactive une instance. Vous pouvez trouver des informations dans le journal qui ne se trouvent nulle part ailleurs; assurez-vous de le vérifier régulièrement et de ne pas le laisser après coup.
Voir les autres parties de cette série :
- Partie 1 :Espace disque
- Partie 2 :Entretien
- Partie 3 :Paramètres de l'instance et de la base de données