Dans cette 3ème partie de Benchmarking Managed PostgreSQL Cloud Solutions , j'ai profité de l'offre de niveau gratuit GCP de Google. Cela a été une expérience enrichissante et en tant qu'administrateur système passant la plupart de son temps sur la console, je ne pouvais pas manquer l'occasion d'essayer cloud shell, l'une des fonctionnalités de la console qui distingue Google du fournisseur de cloud que je connais mieux , Amazon Web Services.
Pour récapituler rapidement, dans la partie 1, j'ai examiné les outils de référence disponibles et expliqué pourquoi j'ai choisi la procédure AWS Benchmark pour Aurora. J'ai également comparé Amazon Aurora pour PostgreSQL version 10.6. Dans la partie 2, j'ai examiné AWS RDS pour PostgreSQL version 11.1.
Au cours de cette phase, les tests basés sur la procédure AWS Benchmark pour Aurora seront exécutés sur Google Cloud SQL pour PostgreSQL 9.6 puisque la version 11.1 est toujours en version bêta.
Instances cloud
Prérequis
Comme mentionné dans les deux articles précédents, j'ai opté pour laisser les paramètres PostgreSQL à leurs valeurs par défaut du cloud GUC, à moins qu'ils n'empêchent les tests de s'exécuter (voir plus loin ci-dessous). Rappelez-vous des articles précédents que l'hypothèse était que, dès le départ, le fournisseur de cloud devrait configurer l'instance de base de données afin de fournir des performances raisonnables.
Le correctif de synchronisation AWS pgbench pour PostgreSQL 9.6.5 s'est appliqué proprement à la version Google Cloud de PostgreSQL 9.6.10.
À l'aide des informations publiées par Google sur son blog Google Cloud for AWS Professionals, j'ai fait correspondre les spécifications du client et des instances cibles en ce qui concerne les composants de calcul, de stockage et de mise en réseau. Par exemple, l'équivalent Google Cloud d'AWS Enhanced Networking est obtenu en dimensionnant le nœud de calcul en fonction de la formule :
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Lorsqu'il s'agit de configurer l'instance de base de données cible, comme pour AWS, Google Cloud n'autorise aucune réplique, cependant, le stockage est chiffré au repos et il n'y a pas d'option pour le désactiver.
Enfin, afin d'obtenir les meilleures performances réseau, le client et les instances cibles doivent être situés dans la même zone de disponibilité.
Client
Les spécifications de l'instance client correspondant à l'instance AWS la plus proche sont :
- vCPU :32 (16 cœurs x 2 threads/cœur)
- RAM :208 Gio (maximum pour l'instance à 32 processeurs virtuels)
- Stockage :disque persistant Compute Engine
- Réseau :16 Gbit/s (max de [32 vCPU x 2 Gbit/s/vCPU] et 16 Gbit/s)
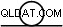
Détails de l'instance après initialisation :
 Instance client :calcul et réseau
Instance client :calcul et réseau Remarque :Les instances sont par défaut limitées à 24 processeurs virtuels. L'assistance technique de Google doit approuver l'augmentation du quota à 32 processeurs virtuels par instance.

Bien que ces demandes soient généralement traitées dans un délai de 2 jours ouvrés, je dois féliciter les services d'assistance Google pour avoir traité ma demande en seulement 2 heures.
Pour les curieux, la formule de vitesse du réseau est basée sur la documentation du moteur de calcul référencée dans ce blog GCP.
Cluster de base de données
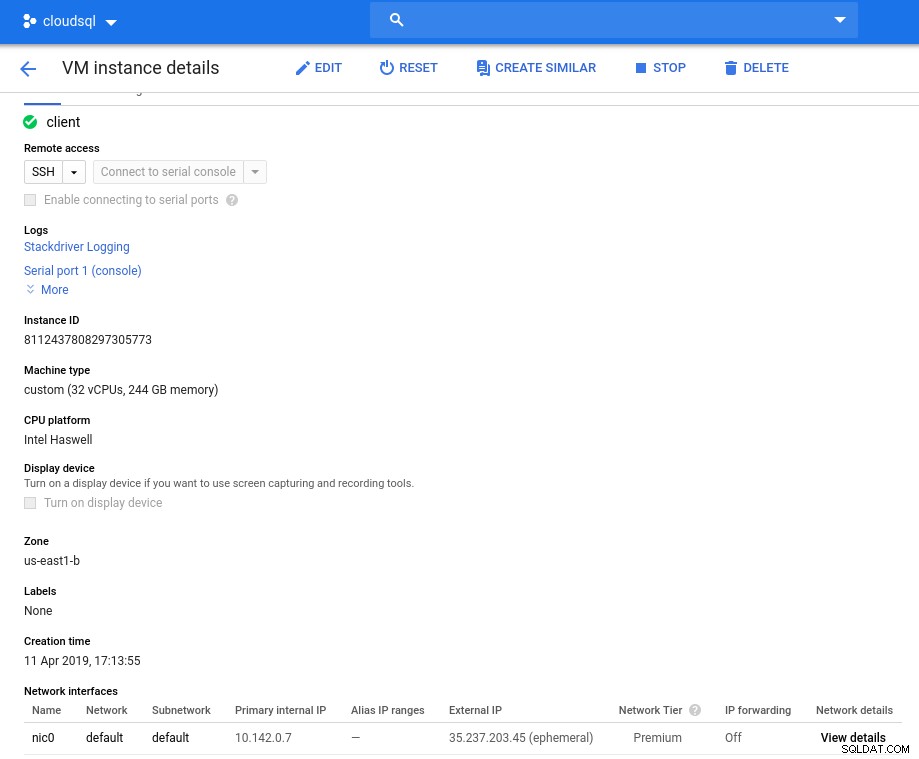
Vous trouverez ci-dessous les spécifications de l'instance de base de données :
- processeur virtuel :8
- RAM :52 Gio (maximum)
- Stockage :144 Mo/s, 9 000 IOPS
- Réseau :2 000 Mo/s
Notez que la mémoire maximale disponible pour une instance à 8 vCPU est de 52 Gio. Plus de mémoire peut être allouée en sélectionnant une instance plus grande (plus de vCPU) :
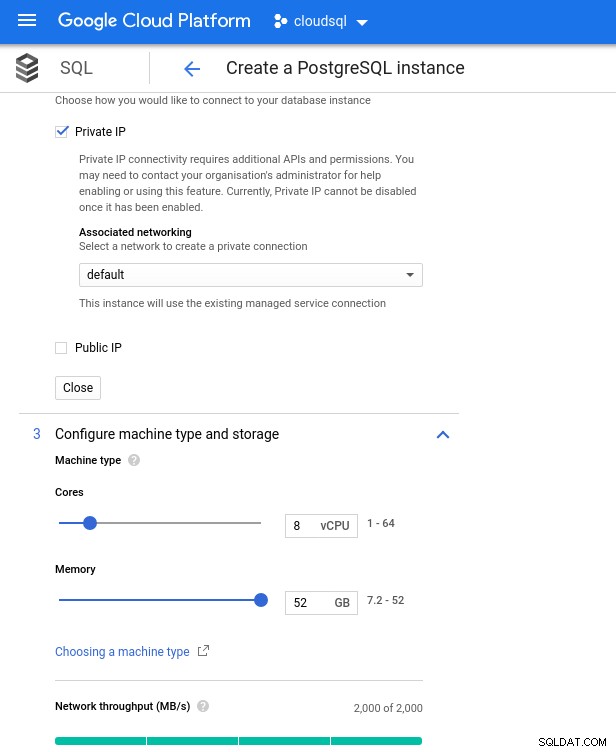 Dimensionnement du processeur et de la mémoire de la base de données
Dimensionnement du processeur et de la mémoire de la base de données Bien que Google SQL puisse étendre automatiquement le stockage sous-jacent, ce qui est d'ailleurs une fonctionnalité vraiment intéressante, j'ai choisi de désactiver l'option afin d'être cohérent avec l'ensemble de fonctionnalités AWS et d'éviter un impact potentiel sur les E/S lors de l'opération de redimensionnement. ("potentiel", car cela ne devrait avoir aucun impact négatif, mais d'après mon expérience, le redimensionnement de tout type de stockage sous-jacent augmente les E/S, même pendant quelques secondes).
Rappelons que l'instance de base de données AWS était sauvegardée par un stockage EBS optimisé qui fournissait un maximum de :
- Bande passante de 1 700 Mbit/s
- Débit de 212,5 Mo/s
- 12 000 IOPS
Avec Google Cloud, nous obtenons une configuration similaire en ajustant le nombre de vCPU (voir ci-dessus) et la capacité de stockage :
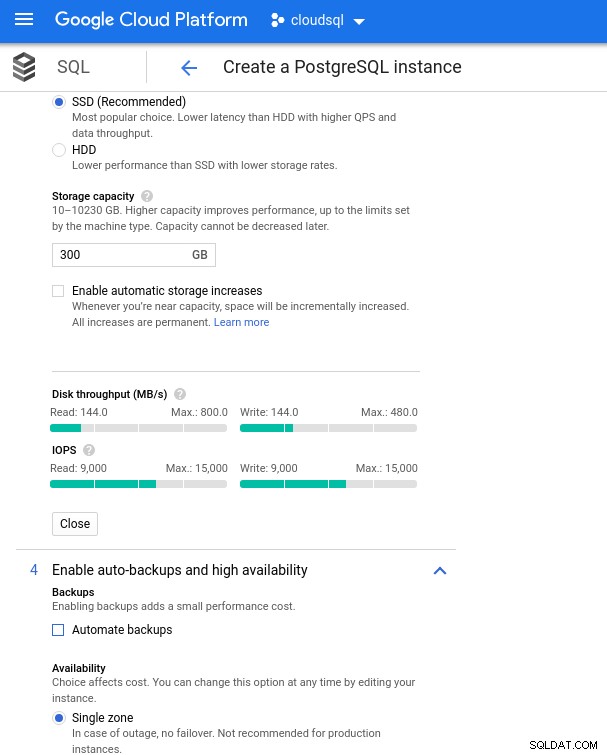 Configuration du stockage de la base de données et paramètres de sauvegarde
Configuration du stockage de la base de données et paramètres de sauvegarde Exécution des benchmarks
Configuration
Ensuite, installez les outils de benchmark, pgbench et sysbench en suivant les instructions du guide Amazon adapté à PostgreSQL version 9.6.10.
Initialisez les variables d'environnement PostgreSQL dans .bashrc et définissez les chemins vers les binaires et bibliothèques PostgreSQL :
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libListe de vérification avant le vol :
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)Et nous sommes prêts pour le décollage :
pgbench
Initialisez la base de données pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…et quelques minutes plus tard :
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Comme nous en avons maintenant l'habitude, la taille de la base de données doit être de 160 Go. Vérifions que :
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Une fois toutes les préparations terminées, démarrez le test de lecture/écriture :
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsOups! Quel est le maximum ?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Ainsi, alors qu'AWS définit un max_connections largement suffisant car je n'ai pas rencontré ce problème, Google Cloud nécessite un petit ajustement...Retournez à la console cloud, mettez à jour le paramètre de base de données, attendez quelques minutes, puis vérifiez :
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)En redémarrant le test, tout semble fonctionner correctement :
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998... mais il y a un autre hic. J'ai eu une surprise en essayant d'ouvrir une nouvelle session psql afin de compter le nombre de connexions :
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsSe pourrait-il que superuser_reserved_connections ne soit pas à sa valeur par défaut ?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)C'est la valeur par défaut, alors qu'est-ce que ça pourrait être d'autre ?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo ! Une autre bosse de max_connections s'en occupe, cependant, il a fallu que je redémarre le test pgbench. Et c'est l'histoire derrière la double exécution apparente dans les graphiques ci-dessous.
Et enfin, les résultats sont là :
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Alimentez la base de données :
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareSortie :
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Et maintenant lancez le test :
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runEt les résultats :
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Métriques de référence
Le plug-in PostgreSQL pour Stackdriver est obsolète depuis le 28 février 2019. Alors que Google recommande Blue Medora, pour les besoins de cet article, j'ai choisi de supprimer la création d'un compte et de m'appuyer sur les métriques Stackdriver disponibles.
- Utilisation du processeur :
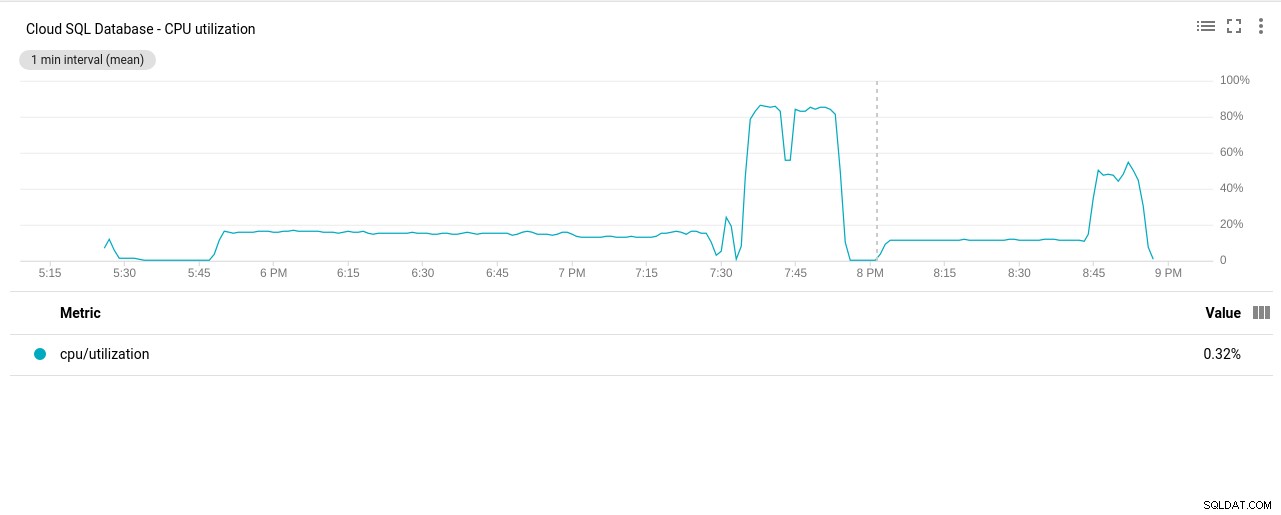 Photo auteur Google Cloud SQL :utilisation du processeur PostgreSQL
Photo auteur Google Cloud SQL :utilisation du processeur PostgreSQL - Opérations de lecture/écriture sur disque :
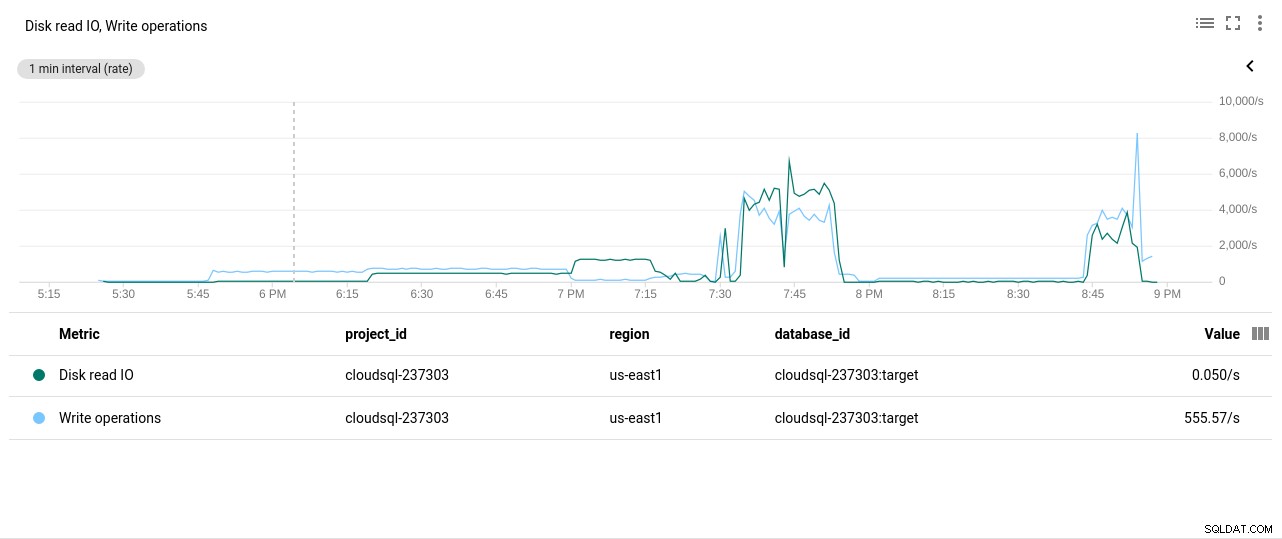 Photo auteur Google Cloud SQL :opérations de lecture/écriture sur disque PostgreSQL
Photo auteur Google Cloud SQL :opérations de lecture/écriture sur disque PostgreSQL - Octets réseau envoyés/reçus :
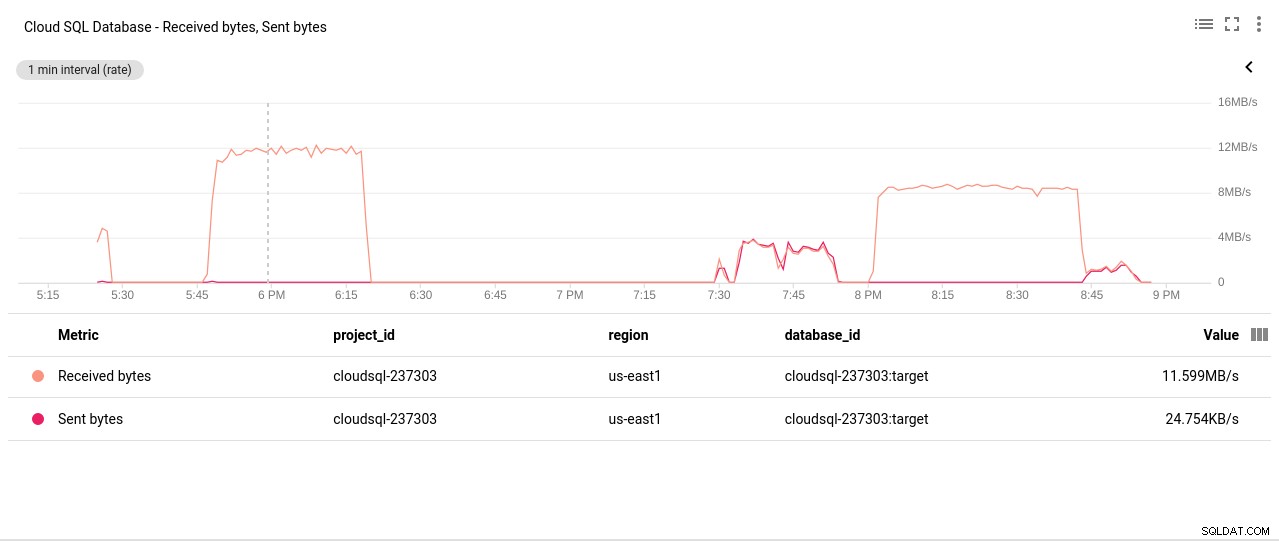 Photo auteur Google Cloud SQL :PostgreSQL Network Sent/Received bytes
Photo auteur Google Cloud SQL :PostgreSQL Network Sent/Received bytes - Nombre de connexions PostgreSQL :
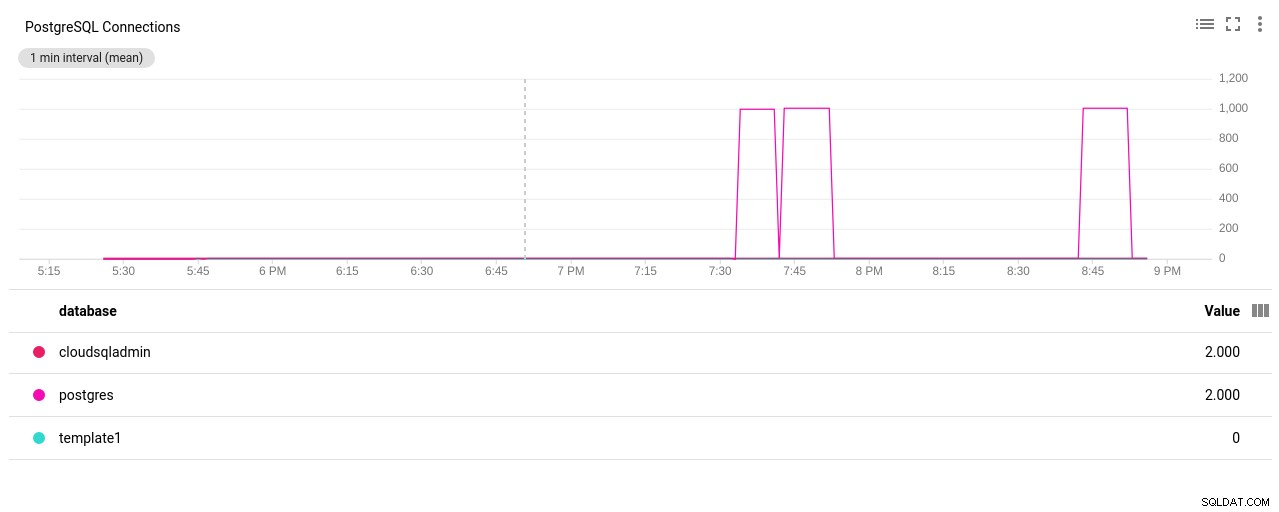 Photo auteur Google Cloud SQL :nombre de connexions PostgreSQL
Photo auteur Google Cloud SQL :nombre de connexions PostgreSQL
Résultats de référence
Initialisation de pgbench
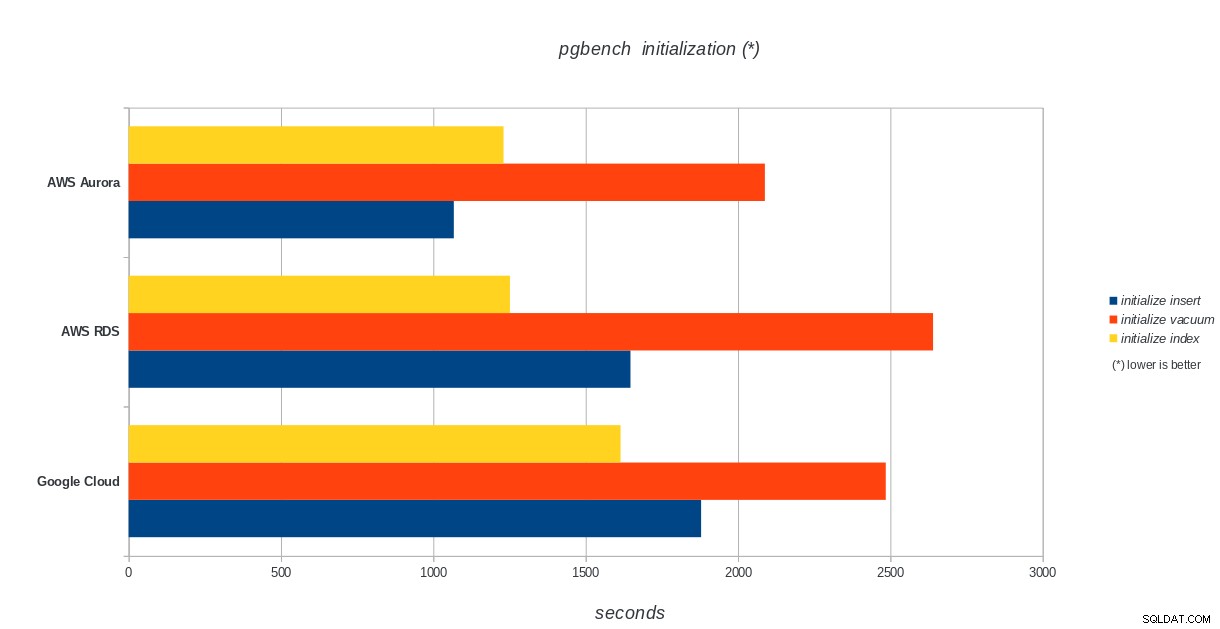 AWS Aurora, AWS RDS, Google Cloud SQL :résultats d'initialisation de PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL :résultats d'initialisation de PostgreSQL pgbench exécution de pgbench
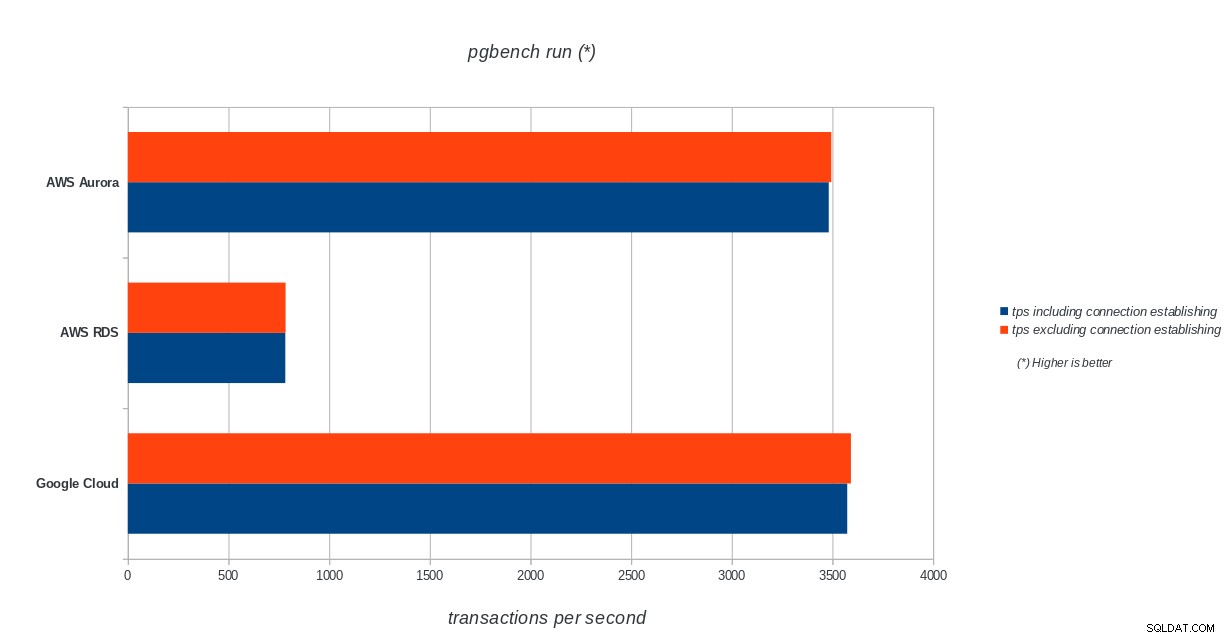 AWS Aurora, AWS RDS, Google Cloud SQL :résultats d'exécution de PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL :résultats d'exécution de PostgreSQL pgbench sysbench
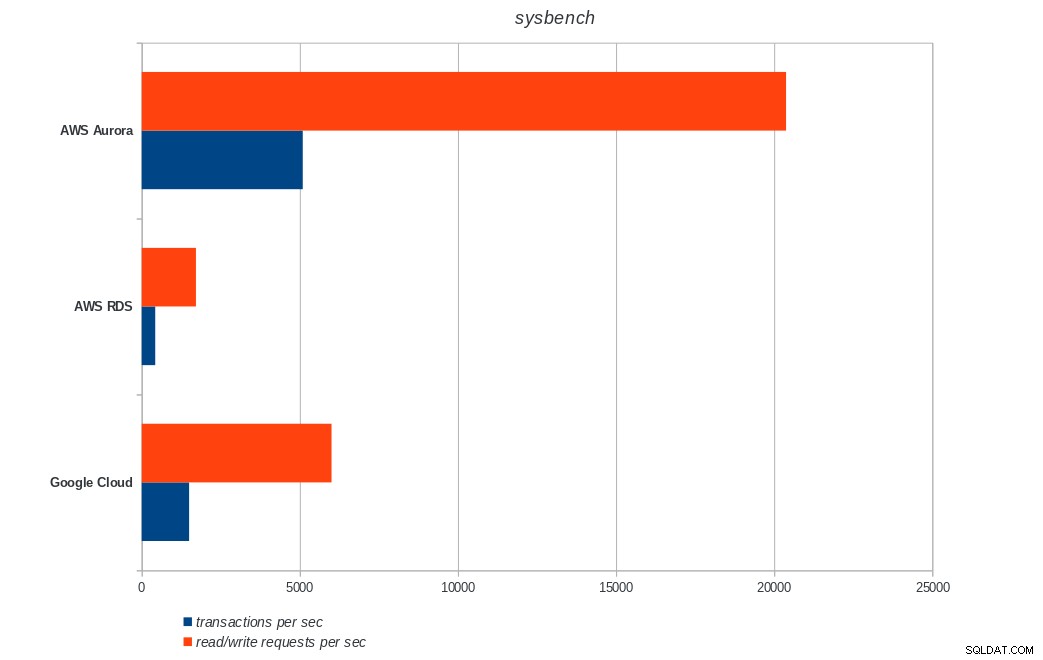 AWS Aurora, AWS RDS, Google Cloud SQL :résultats sysbench PostgreSQL
AWS Aurora, AWS RDS, Google Cloud SQL :résultats sysbench PostgreSQL Conclusion
Amazon Aurora est de loin le premier dans les tests d'écriture lourds (sysbench), tout en étant à égalité avec Google Cloud SQL dans les tests de lecture/écriture pgbench. Le test de charge (initialisation de pgbench) place Google Cloud SQL en premier lieu, suivi d'Amazon RDS. Sur la base d'un examen rapide des modèles de tarification d'AWS Aurora et de Google Cloud SQL, je risquerais de dire que Google Cloud est un meilleur choix pour l'utilisateur moyen, tandis qu'AWS Aurora est mieux adapté aux environnements hautes performances. D'autres analyses suivront après avoir terminé tous les benchmarks.
La prochaine et dernière partie de cette série de benchmarks portera sur Microsoft Azure PostgreSQL.
Merci d'avoir lu et veuillez commenter ci-dessous si vous avez des commentaires.