Dans le précédent article de blog, j'ai brièvement expliqué comment nous avons obtenu les chiffres de performance publiés dans l'annonce pglogical. Dans cet article de blog, j'aimerais discuter des limites de performances des solutions de réplication logique en général, et également de la manière dont elles s'appliquent à pglogical.
réplication physique
Tout d'abord, voyons comment fonctionne la réplication physique (intégrée à PostgreSQL depuis la version 9.0). Une figure quelque peu simplifiée de la avec deux seulement deux nœuds ressemble à ceci :
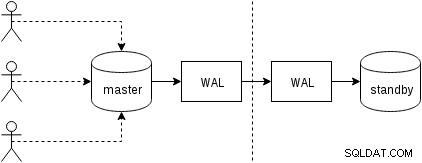
Les clients exécutent des requêtes sur le nœud maître, les modifications sont écrites dans un journal de transactions (WAL) et copiées sur le réseau vers WAL sur le nœud de secours. Le processus de récupération sur le standby sur le standby lit alors les changements de WAL et les applique aux fichiers de données comme lors de la restauration. Si le standby est en mode "hot_standby", les clients peuvent émettre des requêtes en lecture seule sur le nœud pendant que cela se produit.
Ceci est très efficace car il y a très peu de traitement supplémentaire - les modifications sont transférées et écrites dans le standby sous la forme d'un blob binaire opaque. Bien sûr, la récupération n'est pas gratuite (à la fois en termes de CPU et d'E/S), mais il est difficile de faire plus efficace que cela.
Les goulots d'étranglement potentiels évidents avec la réplication physique sont la bande passante du réseau (transfert du WAL du maître au standby) et aussi les E/S sur le standby, qui peuvent être saturées par le processus de récupération qui émet souvent beaucoup de requêtes d'E/S aléatoires ( dans certains cas plus que le maître, mais n'entrons pas dans ce sujet).
réplication logique
La réplication logique est un peu plus compliquée, car elle ne traite pas d'un flux WAL binaire opaque, mais d'un flux de modifications "logiques" (imaginez les instructions INSERT, UPDATE ou DELETE, bien que ce ne soit pas parfaitement correct car nous avons affaire à une représentation structurée de les données). Avoir les changements logiques permet de faire des choses intéressantes comme la résolution de conflits, la réplication uniquement des tables sélectionnées, vers un schéma différent ou entre différentes versions (ou même différentes bases de données).
Il existe différentes façons d'obtenir les modifications - l'approche traditionnelle consiste à utiliser des déclencheurs enregistrant les modifications dans une table, et à laisser un processus personnalisé lire en continu ces modifications et les appliquer en attente en exécutant des requêtes SQL. Et tout cela est piloté par un processus démon externe (ou éventuellement plusieurs processus, s'exécutant sur les deux nœuds), comme illustré sur la figure suivante

C'est ce que font slony ou londiste, et même si cela a plutôt bien fonctionné, cela signifie beaucoup de temps système - par exemple, cela nécessite de capturer les modifications de données et d'écrire les données plusieurs fois (dans la table d'origine et dans une table "log", et également à WAL pour ces deux tables). Nous discuterons d'autres sources de frais généraux plus tard. Alors que pglogical doit atteindre les mêmes objectifs, il les atteint différemment, grâce à plusieurs fonctionnalités ajoutées aux versions récentes de PostgreSQL (donc non disponibles lorsque les autres outils ont été implémentés) :

Autrement dit, au lieu de maintenir un journal séparé des modifications, pglogical s'appuie sur WAL - cela est possible grâce à un décodage logique disponible dans PostgreSQL 9.4, qui permet d'extraire les modifications logiques du journal WAL. Grâce à cela, pglogical n'a pas besoin de déclencheurs coûteux et peut généralement éviter d'écrire les données deux fois sur le maître (sauf pour les transactions volumineuses qui peuvent se répandre sur le disque).
Après avoir décodé chaque transaction, elle est transférée vers la base de données de secours et le processus d'application applique ses modifications à la base de données de secours. pglogical n'applique pas les modifications en exécutant des requêtes SQL régulières, mais à un niveau inférieur, en contournant la surcharge associée à l'analyse et à la planification des requêtes SQL. Cela donne à pglogical un avantage significatif sur les solutions existantes qui passent toutes par la couche SQL (payant ainsi l'analyse et la planification).
goulets d'étranglement potentiels
De toute évidence, la réplication logique est susceptible des mêmes goulots d'étranglement que la réplication physique, c'est-à-dire qu'il est possible de saturer le réseau lors du transfert des modifications et les E/S en veille lors de leur application en veille. Il y a également une bonne quantité de frais généraux en raison d'étapes supplémentaires non présentes dans une réplication physique.
Nous devons en quelque sorte collecter les modifications logiques, tandis que la réplication physique transmet simplement le WAL sous forme de flux d'octets. Comme déjà mentionné, les solutions existantes reposent généralement sur des déclencheurs écrivant les modifications dans une table « journal ». pglogical s'appuie à la place sur le journal d'écriture anticipée (WAL) et le décodage logique pour obtenir la même chose, ce qui est moins cher que les déclencheurs et n'a pas non plus besoin d'écrire les données deux fois dans la plupart des cas (avec le bonus supplémentaire que nous appliquons automatiquement les changements dans l'ordre de validation).
Cela ne veut pas dire qu'il n'y a aucune possibilité d'amélioration supplémentaire - par exemple, le décodage ne se produit actuellement qu'une fois la transaction validée, donc avec des transactions importantes, cela peut augmenter le délai de réplication. La réplication physique transmet simplement les modifications WAL à l'autre nœud et n'a donc pas cette limitation. Les transactions volumineuses peuvent également se répandre sur le disque, provoquant des écritures en double, car l'amont doit les stocker jusqu'à ce qu'elles soient validées et qu'elles puissent être envoyées à l'aval.
Des travaux futurs sont prévus pour permettre à pglogical de commencer à diffuser des transactions volumineuses pendant qu'elles sont encore en cours sur l'amont, réduisant ainsi la latence entre la validation en amont et la validation en aval et réduisant l'amplification des écritures en amont.
Une fois les modifications transférées vers la veille, le processus d'application doit les appliquer d'une manière ou d'une autre. Comme mentionné dans la section précédente, les solutions existantes l'ont fait en construisant et en exécutant des commandes SQL, tandis que pglogical contourne entièrement la couche SQL et la surcharge associée.
Néanmoins, cela ne rend pas l'application entièrement gratuite car elle doit encore effectuer des tâches telles que des recherches de clé primaire, mettre à jour des index, exécuter des déclencheurs et effectuer diverses autres vérifications. Mais c'est nettement moins cher que l'approche basée sur SQL. Dans un sens, cela fonctionne un peu comme COPY et est particulièrement rapide sur des tables simples sans déclencheurs, clés étrangères, etc.
Dans toutes les solutions de réplication logique, chacune de ces étapes (décodage et application) se déroule en un seul processus, le temps CPU est donc assez limité. C'est probablement le goulot d'étranglement le plus pressant de toutes les solutions existantes, car vous pouvez avoir une machine assez costaud avec des dizaines voire des centaines de clients exécutant des requêtes en parallèle, mais tout cela doit passer par un seul processus décodant ces changements (sur le maître) et un processus appliquant ces modifications (en veille).
La limitation du « processus unique » peut être quelque peu assouplie en utilisant des bases de données distinctes, car chaque base de données est gérée par un processus distinct. En ce qui concerne une base de données unique, des travaux futurs sont prévus pour paralléliser les applications via un pool de travailleurs en arrière-plan afin d'atténuer ce goulot d'étranglement.