Présentation
Un tableau est une structure logique. Lorsque vous créez une table, vous ne vous souciez généralement pas des lecteurs sur lesquels elle se trouve au niveau de la couche de stockage. Cependant, si vous êtes un administrateur de base de données, cette connaissance peut devenir essentielle si vous devez déplacer certaines parties de la base de données vers un stockage ou un volume alternatif. Ensuite, vous souhaiterez peut-être que des tables définies se trouvent sur un volume ou un ensemble de disques particulier.
Les groupes de fichiers dans SQL Server offrent cette couche d'abstraction nous permettant de contrôler l'emplacement physique de nos structures logiques - tables, index, etc.
Groupes de fichiers
Un groupe de fichiers est une structure logique permettant de regrouper des fichiers de données dans SQL Server. Si nous créons un groupe de fichiers et l'associons à un ensemble de fichiers de données, tout objet logique créé sur ce groupe de fichiers sera physiquement situé sur cet ensemble de fichiers physiques.
L'objectif principal d'un tel regroupement de fichiers physiques est l'allocation et le placement des données. Par exemple, nous voulons que nos données de transaction soient stockées sur un ensemble de disques rapides. Simultanément, nous avons besoin des données historiques stockées sur un autre ensemble de disques moins chers. Dans un tel scénario, nous créerions le Tran table sur le groupe de fichiers TXN et le TranHist table sur un groupe de fichiers HIST différent. Plus loin dans cet article, nous verrons comment cela se traduit par le fait d'avoir les données sur différents disques.
Créer des groupes de fichiers
La syntaxe pour créer des groupes de fichiers est montrée dans Liste 1 . Remarque :Le contexte de la base de données est le maître base de données. En émettant les instructions, nous modifions la base de données DB2 en y ajoutant de nouveaux groupes de fichiers. Essentiellement, ces groupes de fichiers ne sont que des constructions logiques à ce stade. Ils ne contiennent aucune donnée.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Ajout de fichiers aux groupes de fichiers
L'étape suivante consiste à ajouter un fichier à chacun des groupes de fichiers. Nous pouvons ajouter plus d'un fichier, mais nous le gardons simple à des fins de démonstration. Notez que chaque fichier se trouve entièrement sur un lecteur différent et que la syntaxe nous permet de spécifier le groupe de fichiers souhaité.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Création de tables pour les groupes de fichiers
Ici, nous nous assurons que les tables se trouvent sur les disques souhaités. La syntaxe de création de tables nous permet de spécifier le groupe de fichiers que nous voulons.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Prenant du recul, nous notons que nous avons maintenant réalisé ce qui suit :
- Création de deux groupes de fichiers.
- Déterminé les fichiers de données (et les disques) associés à chaque groupe de fichiers.
- Déterminé les tables associées à chaque groupe de fichiers.
Essentiellement, le groupe de fichiers est la couche d'abstraction .
Vérification des groupes de fichiers sur lesquels reposent nos tables
Pour vérifier à quel groupe de fichiers appartient chaque table, nous allons exécuter le code du Listing 4. Nous utilisons deux vues principales du catalogue système :sys.indexes et sys.data_spaces . Les sys.data_spaces La vue du catalogue contient des informations sur les groupes de fichiers et les partitions, ainsi que les principales structures logiques dans lesquelles les tables et les index sont stockés.
Remarque :nous n'avons pas utilisé sys.tables . Le serveur SQL associe les index d'une table à des espaces de données plutôt qu'à des tables, comme nous pourrions le penser intuitivement.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
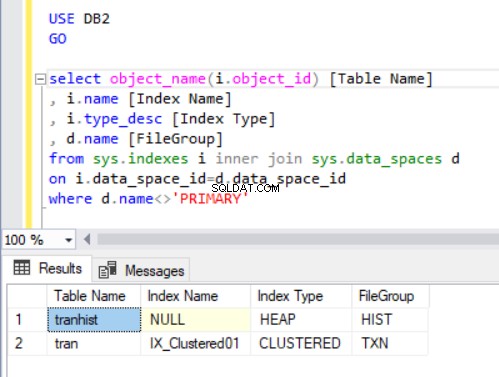
La sortie de la requête du Listing 4 affiche deux tables que nous venons de créer. Notez que le tranhiste la table n'a pas d'index. Pourtant, il apparaît dans le jeu de résultats, identifié comme un tas .
Un tas est une table qui n'a pas d'index clusterisé déterminant les données de commande stockées physiquement dans une table. Il ne peut y avoir qu'un seul index clusterisé dans une table.
Remplir la table Tran
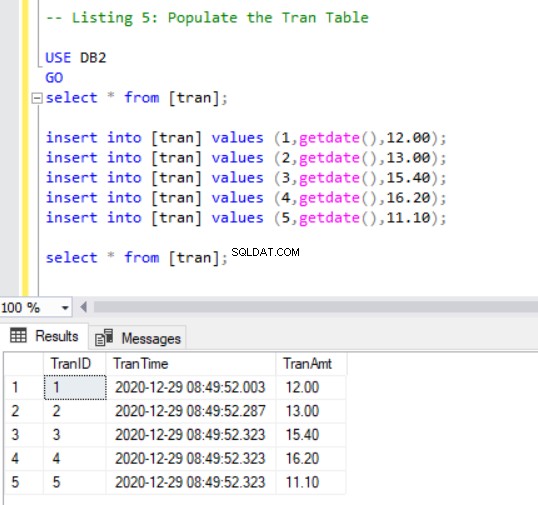
Maintenant, nous devons ajouter quelques enregistrements au tran table en utilisant le code suivant :
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Déplacer une table vers un autre groupe de fichiers
Pour déplacer le tran table vers un autre groupe de fichiers, il nous suffit de reconstruire l'index clusterisé et spécifiez le nouveau groupe de fichiers lors de cette reconstruction. Le Listing 5 montre cette approche.
Nous effectuons deux étapes :d'abord, supprimez l'index, puis recréez-le. Entre-temps, nous vérifions que les données et l'emplacement des deux tables que nous avons créées précédemment restent intacts.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
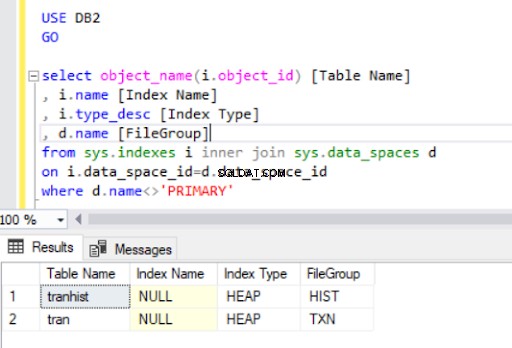
En supprimant l'index clusterisé du tran table, nous l'avons convertie en tas :
Lorsque nous recréons l'index clusterisé, il est également indiqué dans la sortie de la liste 4.
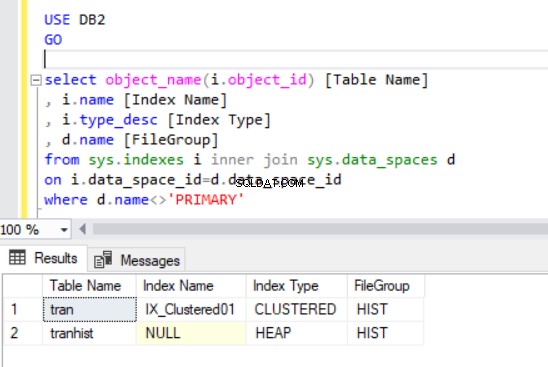
Maintenant, nous avons le tran table sur le groupe de fichiers HIST.
Conclusion
Cet article a démontré la relation entre les tables, les index, les fichiers et les groupes de fichiers en termes de stockage de données SQL Server. Nous avons également expliqué comment déplacer une table d'un groupe de fichiers à un autre en recréant l'index clusterisé.
Cette compétence vous sera utile lorsque vous devrez migrer des données vers un nouveau stockage (disques plus rapides ou disques plus lents pour l'archivage). Dans des scénarios plus avancés, vous pouvez utiliser des groupes de fichiers pour gérer le cycle de vie des données en implémentant des partitions de table.
Références
- Fichiers et groupes de fichiers de base de données
- Commutation des partitions de table :procédure pas à pas



