L'un des aspects clés de la haute disponibilité est la capacité à réagir rapidement aux pannes. Il n'est pas rare de gérer manuellement les bases de données et de demander à un logiciel de surveillance de surveiller l'état de la base de données. En cas de panne, le logiciel de surveillance envoie une alerte au personnel d'astreinte. Cela signifie que quelqu'un peut potentiellement avoir besoin de se réveiller, d'accéder à un ordinateur et de se connecter aux systèmes et de consulter les journaux - c'est-à-dire qu'il y a un certain temps avant que la correction puisse commencer. Idéalement, l'ensemble du processus devrait être automatisé.
Dans ce blog, nous verrons comment déployer un système entièrement automatisé qui détecte la défaillance de la base de données principale et lance des procédures de basculement en promouvant une base de données secondaire. Nous utiliserons ClusterControl pour effectuer un basculement automatique de la base de données Moodle PostgreSQL.
Avantage du basculement automatique
- Moins de temps pour récupérer le service de base de données
- Plus grande disponibilité du système
- Moins de dépendance vis-à-vis du DBA ou de l'administrateur qui a configuré la haute disponibilité pour la base de données
Architecture
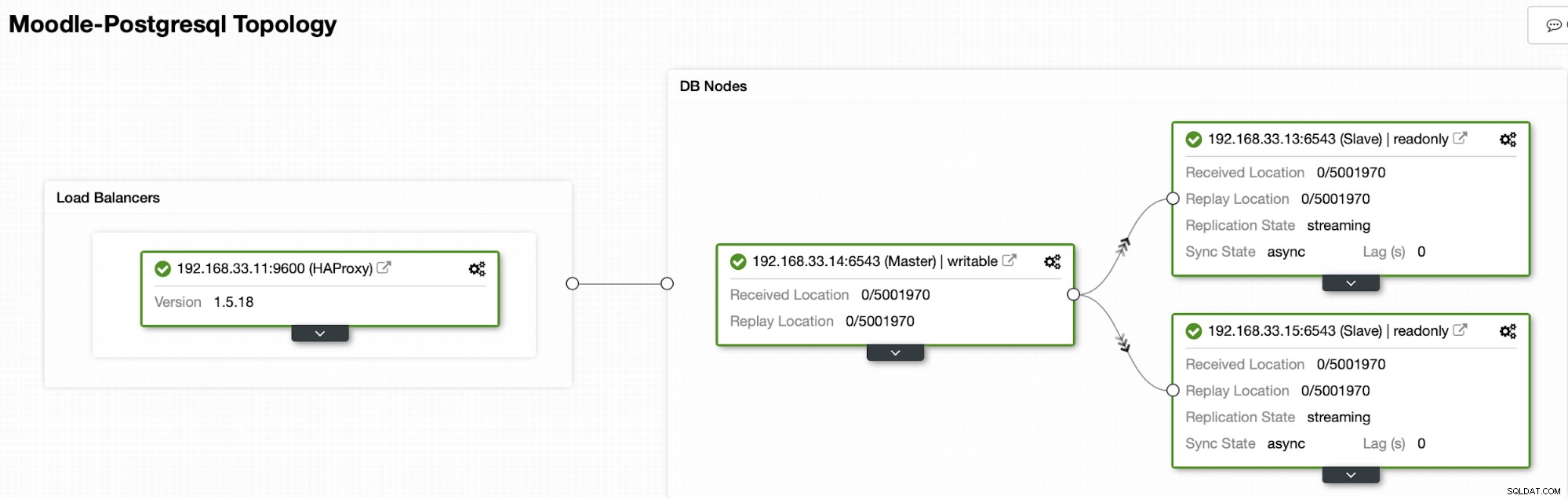
Actuellement, nous avons un serveur principal Postgres et deux serveurs secondaires sous l'équilibreur de charge HAProxy qui envoie le trafic Moodle au nœud PostgreSQL principal. La récupération du cluster et la récupération automatique des nœuds dans ClusterControl sont les paramètres importants pour effectuer le processus de basculement automatique.

Contrôle vers quel serveur basculer
ClusterControl propose une liste blanche et une liste noire d'un ensemble de serveurs que vous souhaitez participer au basculement ou exclure en tant que candidat.
Il y a deux variables que vous pouvez définir dans la configuration cmon,
- replication_failover_whitelist :elle contient une liste d'adresses IP ou de noms d'hôte de serveurs secondaires qui doivent être utilisés comme candidats primaires potentiels. Si cette variable est définie, seuls ces hôtes seront pris en compte.
- replication_failover_blacklist :elle contient une liste d'hôtes qui ne seront jamais considérés comme candidat principal. Vous pouvez l'utiliser pour répertorier les serveurs secondaires utilisés pour les sauvegardes ou les requêtes analytiques. Si le matériel varie entre les serveurs secondaires, vous pouvez placer ici les serveurs qui utilisent un matériel plus lent.
Processus de basculement automatique
Étape 1
Nous avons commencé le chargement des données sur le serveur principal (192.168.33.14) à l'aide de l'outil sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Étape 2
Nous allons arrêter le serveur primaire Postgres (192.168.33.14). Dans ClusterControl, le paramètre (enable_cluster_autorecovery) est activé afin de promouvoir le prochain primaire approprié.
# service postgresql-12 stopÉtape 3
ClusterControl détecte les défaillances dans le primaire et promeut un secondaire avec les données les plus récentes en tant que nouveau primaire. Cela fonctionne également sur le reste des serveurs secondaires pour les répliquer à partir du nouveau serveur principal.

Dans notre cas, le (192.168.33.13) est un nouveau serveur principal et les serveurs secondaires répliquent maintenant à partir de ce nouveau serveur primaire. Désormais, HAProxy achemine le trafic de la base de données des serveurs Moodle vers le dernier serveur principal.
De (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Depuis (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Topologie actuelle
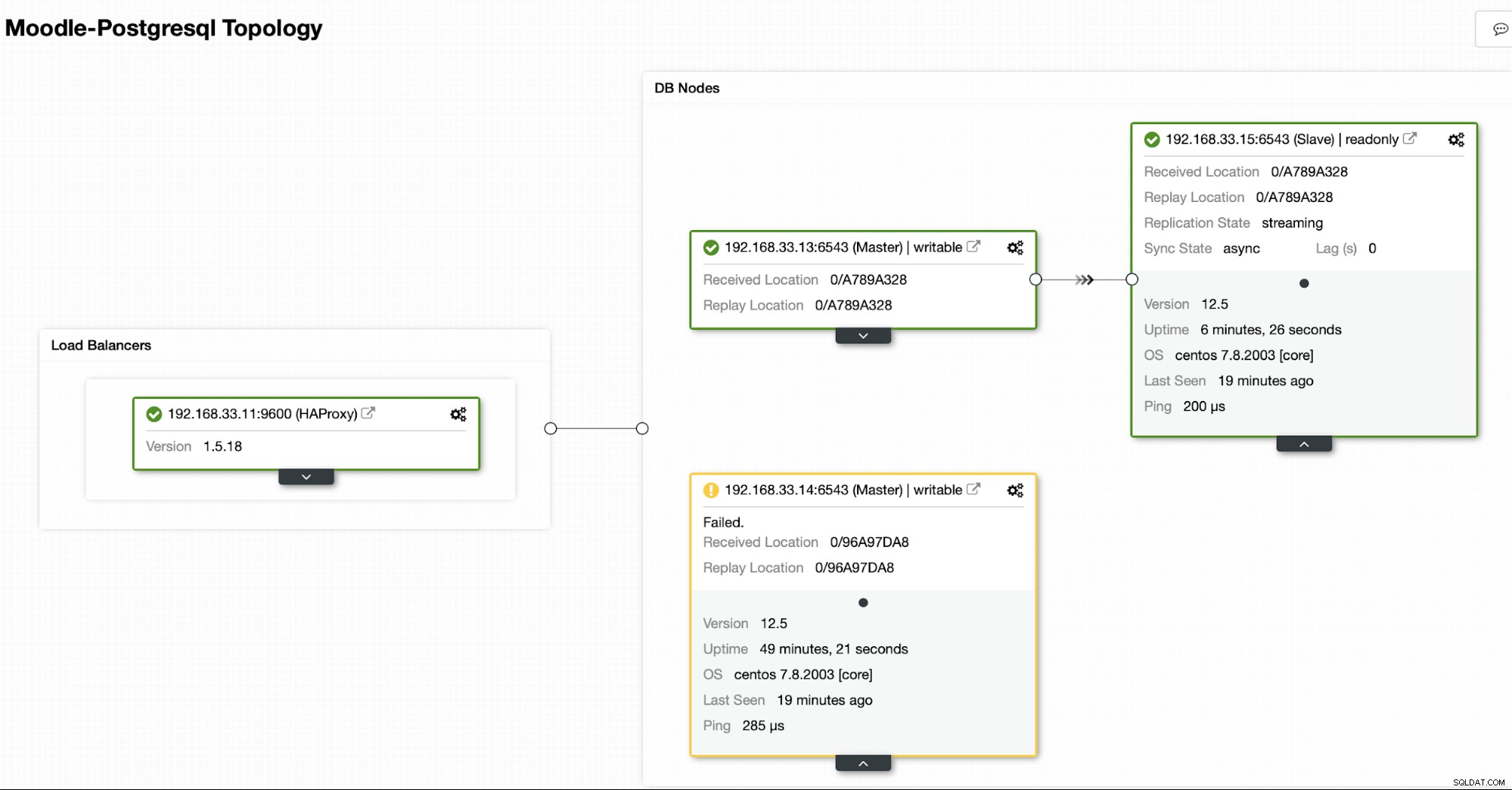
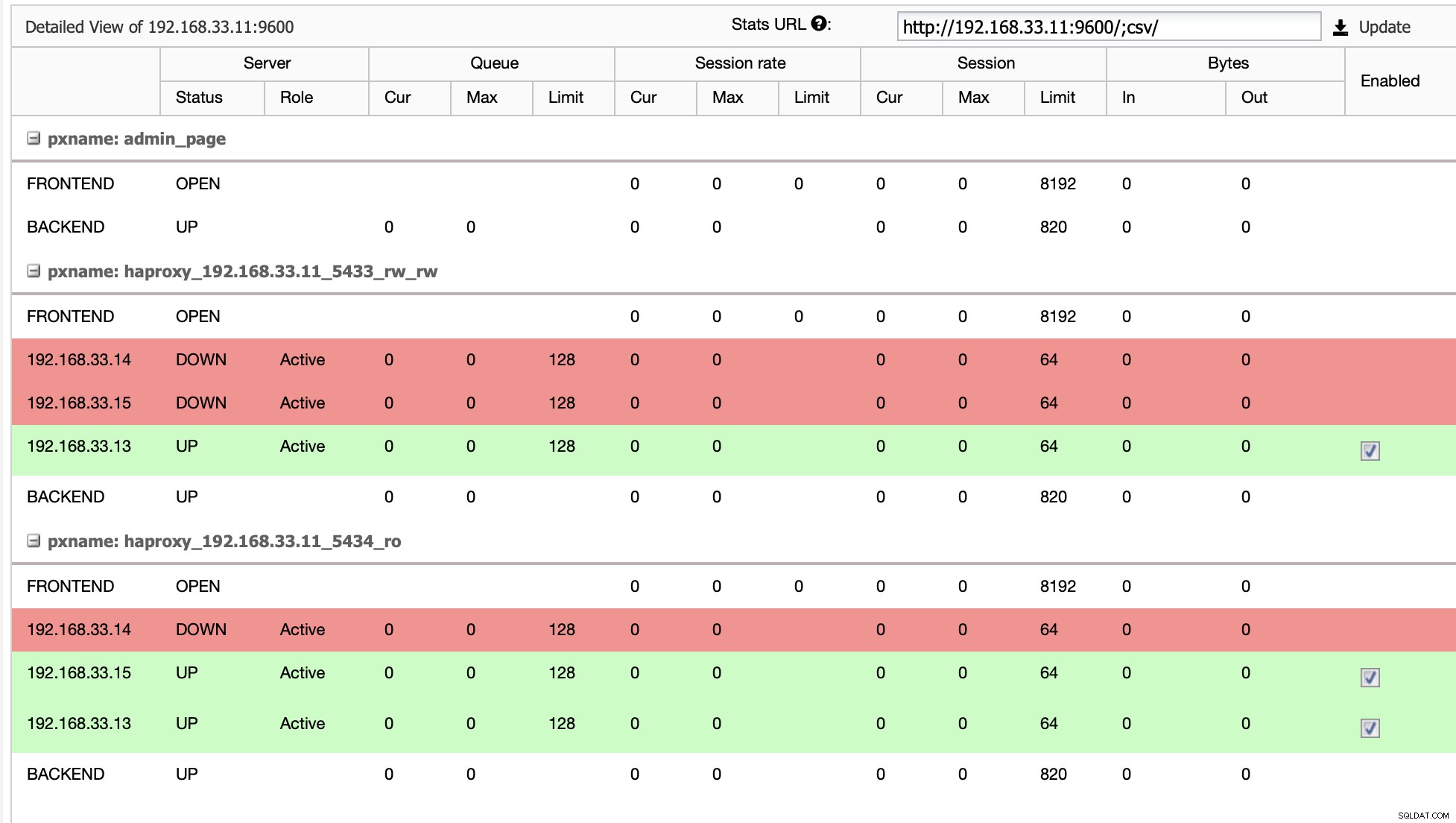
Lorsque HAProxy détecte que l'un de nos nœuds, principal ou réplica, est n'est pas accessible, il le marque automatiquement comme étant hors ligne. HAProxy ne lui enverra aucun trafic depuis l'application Moodle. Cette vérification est effectuée par des scripts de vérification de l'état configurés par ClusterControl au moment du déploiement.
Une fois que ClusterControl promeut un serveur réplica en serveur principal, notre HAProxy marque l'ancien serveur principal comme étant hors ligne et met le nœud promu en ligne.
Une fois que l'ancien serveur principal est de nouveau en ligne, il ne se synchronisera pas automatiquement avec le nouveau serveur principal. Nous devons le laisser revenir dans la topologie, et cela peut être fait via l'interface ClusterControl. Cela évitera la possibilité de perte de données ou d'incohérence, au cas où nous voudrions enquêter sur la raison pour laquelle ce serveur a échoué en premier lieu.
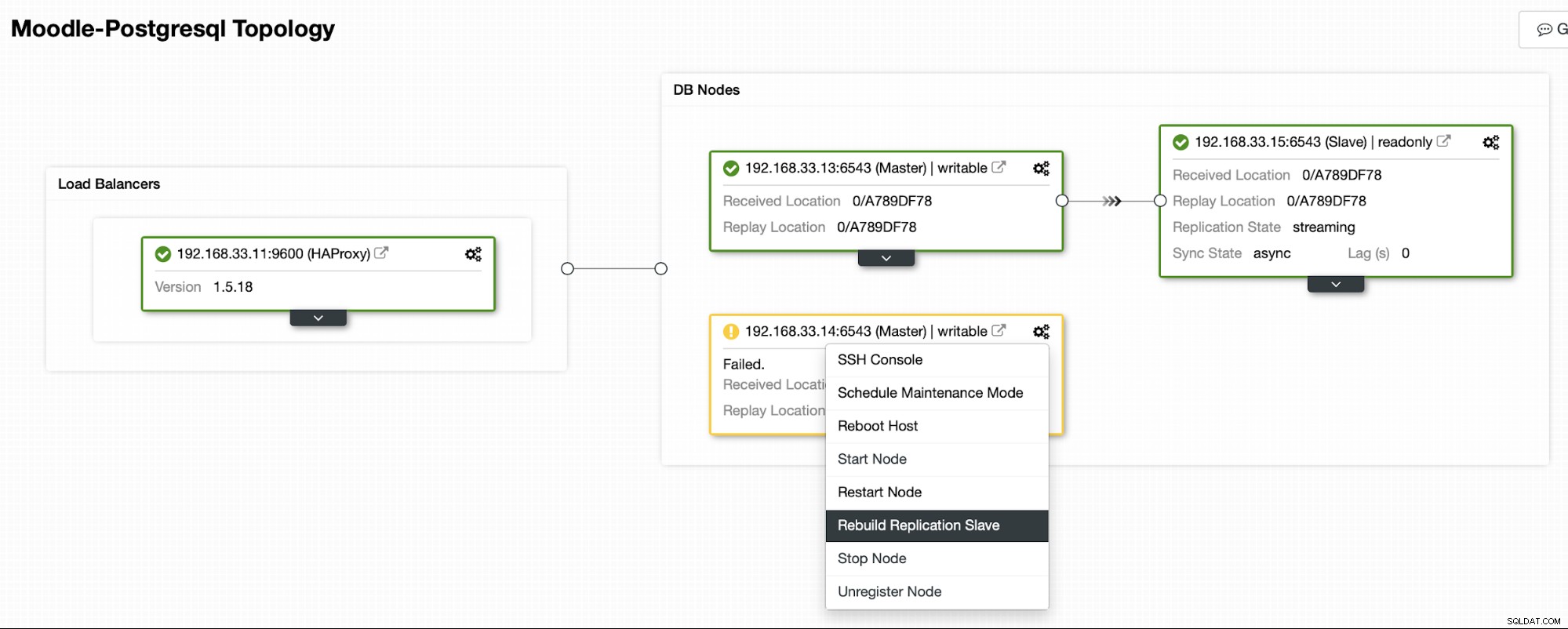
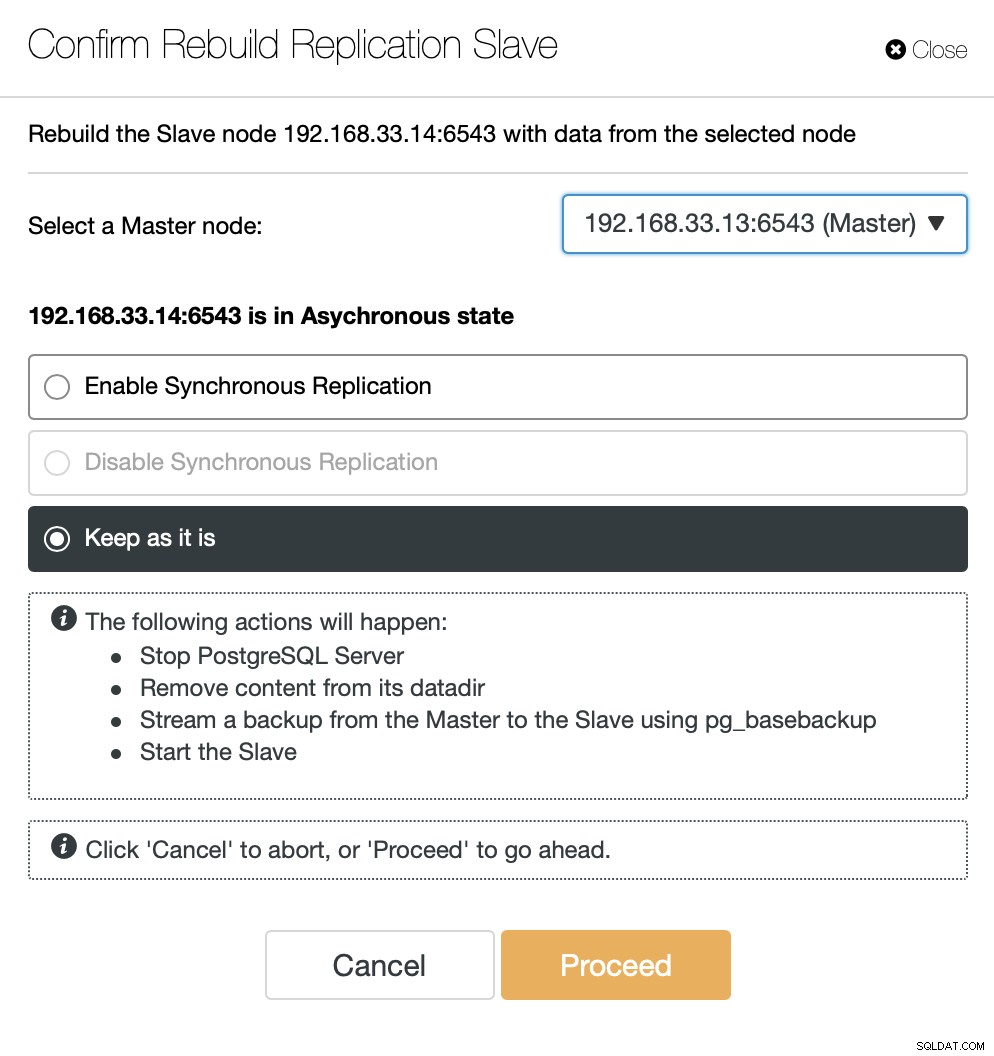
ClusterControl diffusera la sauvegarde à partir du nouveau serveur principal et configurera la réplication.
Conclusion
Le basculement automatique est une partie importante de toute base de données de production Moodle. Il peut réduire les temps d'arrêt lorsqu'un serveur tombe en panne, mais également lors de l'exécution de tâches de maintenance courantes ou de migrations. Il est important de bien faire les choses, car il est important que le logiciel de basculement prenne les bonnes décisions.