La lecture à partir de la mémoire sera toujours plus performante que l'accès au disque, donc pour toutes les technologies de base de données, vous voudrez utiliser autant de mémoire que possible. Si vous n'êtes pas sûr de la configuration ou si vous rencontrez une erreur, cela peut générer une utilisation élevée de la mémoire ou même un problème de mémoire insuffisante.
Dans ce blog, nous verrons comment vérifier votre utilisation de la mémoire PostgreSQL et quel paramètre vous devez prendre en compte pour l'ajuster. Pour cela, commençons par voir un aperçu de l'architecture de PostgreSQL.
Architecture PostgreSQL
L'architecture de PostgreSQL est basée sur trois parties fondamentales :les processus, la mémoire et le disque.
La mémoire peut être classée en deux catégories :
- Mémoire locale :Il est chargé par chaque processus backend pour son propre usage pour le traitement des requêtes. Il est divisé en sous-domaines :
- Mémoire de travail :la mémoire de travail est utilisée pour trier les tuples par les opérations ORDER BY et DISTINCT, et pour joindre des tables.
- Mem travaux de maintenance :certains types d'opérations de maintenance utilisent cette zone. Par exemple, VACUUM, si vous ne spécifiez pas autovacuum_work_mem.
- Tampons temporaires :il est utilisé pour stocker les tables temporaires.
- Mémoire partagée :Il est alloué par le serveur PostgreSQL lors de son démarrage, et il est utilisé par tous les processus. Il est divisé en sous-domaines :
- Pool de mémoire tampon partagé :où PostgreSQL charge les pages avec des tables et des index à partir du disque, pour travailler directement à partir de la mémoire, réduisant ainsi l'accès au disque.
- Buffer WAL :les données WAL constituent le journal des transactions dans PostgreSQL et contiennent les modifications apportées à la base de données. Le tampon WAL est la zone où les données WAL sont stockées temporairement avant de les écrire sur le disque dans les fichiers WAL. Ceci est fait à chaque instant prédéfini appelé point de contrôle. Ceci est très important pour éviter la perte d'informations en cas de panne du serveur.
- Journal des validations :il enregistre l'état de toutes les transactions pour le contrôle de la simultanéité.
Comment savoir ce qui se passe
Si vous avez une utilisation élevée de la mémoire, vous devez d'abord confirmer quel processus génère la consommation.
Utilisation de la commande Linux "Top"
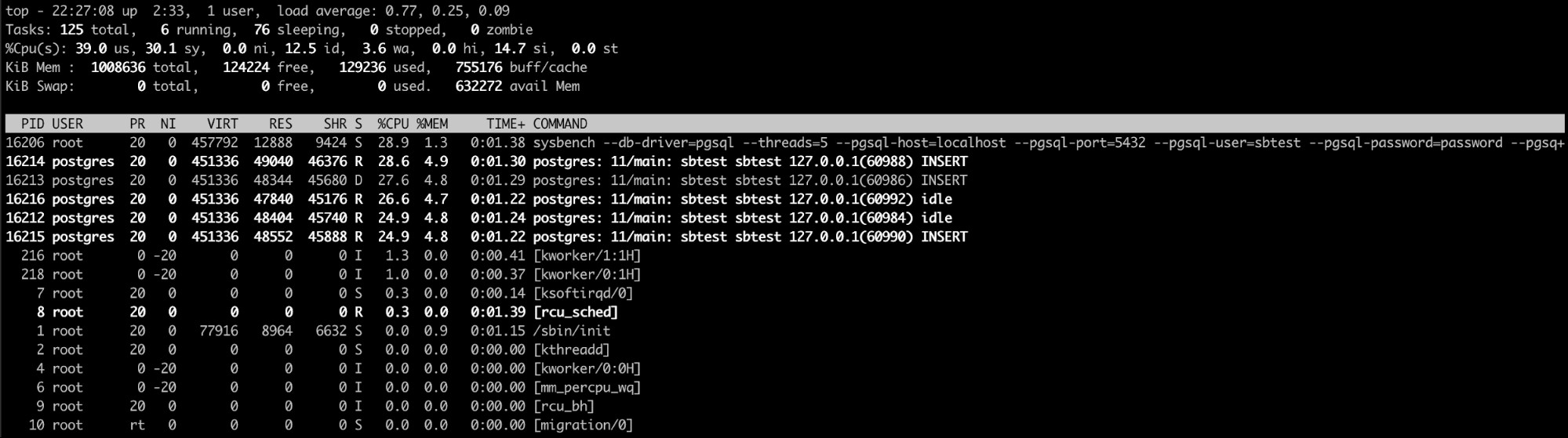
La commande top linux est probablement la meilleure option ici (ou même une commande similaire un comme htop). Avec cette commande, vous pouvez voir le ou les processus qui consomment trop de mémoire.
Lorsque vous confirmez que PostgreSQL est responsable de ce problème, l'étape suivante consiste à vérifier pourquoi.
Utiliser le journal PostgreSQL
Vérifier à la fois les journaux PostgreSQL et système est certainement un bon moyen d'avoir plus d'informations sur ce qui se passe dans votre base de données/système. Vous pourriez voir des messages comme :
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childSi vous n'avez pas assez de mémoire libre.
Ou même plusieurs erreurs de message de base de données comme :
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedLorsque vous rencontrez un comportement inattendu du côté de la base de données. Ainsi, les journaux sont utiles pour détecter ce genre de problèmes et bien plus encore. Vous pouvez automatiser cette surveillance en analysant les fichiers journaux à la recherche de travaux tels que "FATAL", "ERROR" ou "Kill", afin de recevoir une alerte lorsque cela se produit.
Utiliser Pg_top
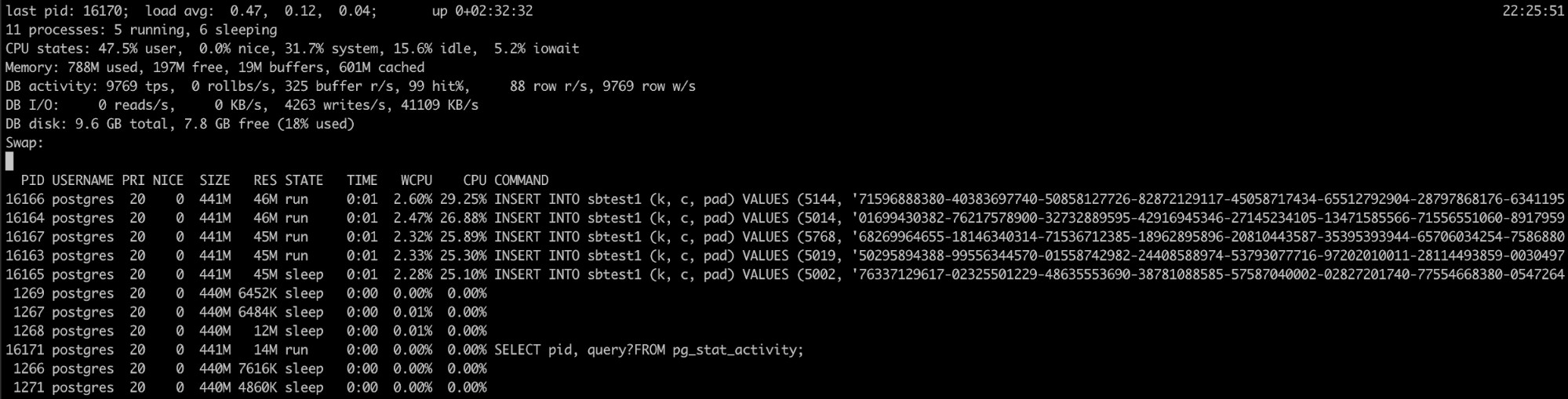
Si vous savez que le processus PostgreSQL utilise beaucoup de mémoire, mais les journaux n'ont pas aidé, vous avez un autre outil qui peut être utile ici, pg_top.
Cet outil est similaire au meilleur outil Linux, mais il est spécifiquement pour PostgreSQL. Ainsi, en l'utilisant, vous aurez des informations plus détaillées sur ce qui exécute votre base de données, et vous pouvez même tuer des requêtes ou exécuter une tâche d'explication si vous détectez quelque chose de mal. Vous pouvez trouver plus d'informations sur cet outil ici.
Mais que se passe-t-il si vous ne pouvez détecter aucune erreur et que la base de données utilise toujours beaucoup de RAM. Vous devrez donc probablement vérifier la configuration de la base de données.
Quels paramètres de configuration prendre en compte
Si tout semble correct mais que vous rencontrez toujours le problème d'utilisation élevée, vous devez vérifier la configuration pour confirmer si elle est correcte. Ainsi, les paramètres suivants doivent être pris en compte dans ce cas.
tampons_partagés
Il s'agit de la quantité de mémoire utilisée par le serveur de base de données pour les tampons de mémoire partagée. Si cette valeur est trop faible, la base de données utilisera plus de disque, ce qui entraînera plus de lenteur, mais si elle est trop élevée, cela pourrait générer une utilisation élevée de la mémoire. Selon la documentation, si vous avez un serveur de base de données dédié avec 1 Go ou plus de RAM, une valeur de départ raisonnable pour shared_buffers est de 25 % de la mémoire de votre système.
work_mem
Il spécifie la quantité de mémoire qui sera utilisée par ORDER BY, DISTINCT et JOIN avant d'écrire dans les fichiers temporaires sur le disque. Comme avec les shared_buffers, si nous configurons ce paramètre trop bas, nous pouvons avoir plus d'opérations sur le disque, mais trop haut est dangereux pour l'utilisation de la mémoire. La valeur par défaut est de 4 Mo.
max_connexions
Work_mem va également de pair avec la valeur max_connections, car chaque connexion exécutera ces opérations en même temps, et chaque opération sera autorisée à utiliser autant de mémoire que spécifié par cette valeur avant elle commence à écrire des données dans des fichiers temporaires. Ce paramètre détermine le nombre maximum de connexions simultanées à notre base de données, si nous configurons un nombre élevé de connexions, et ne prenons pas cela en compte, vous pouvez commencer à avoir des problèmes de ressources. La valeur par défaut est 100.
temp_buffers
Les tampons temporaires sont utilisés pour stocker les tables temporaires utilisées dans chaque session. Ce paramètre définit la quantité maximale de mémoire pour cette tâche. La valeur par défaut est de 8 Mo.
maintenance_work_mem
Il s'agit de la mémoire maximale qu'une opération telle que le VACUUM, l'ajout d'index ou de clés étrangères peut consommer. La bonne chose est qu'une seule opération de ce type peut être exécutée dans une session, et ce n'est pas la chose la plus courante d'en exécuter plusieurs en même temps dans le système. La valeur par défaut est 64 Mo.
autovacuum_work_mem
Le vacuum utilise le maintenance_work_mem par défaut, mais nous pouvons le séparer en utilisant ce paramètre. Nous pouvons spécifier ici la quantité maximale de mémoire à utiliser par chaque autovacuum worker.
wal_buffers
La quantité de mémoire partagée utilisée pour les données WAL qui n'ont pas encore été écrites sur le disque. Le paramètre par défaut est de 3 % de shared_buffers, mais pas moins de 64 ko ni plus que la taille d'un segment WAL, généralement 16 Mo.
Conclusion
Il existe différentes raisons d'avoir une utilisation élevée de la mémoire, et la détection du problème racine peut être une tâche fastidieuse. Dans ce blog, nous avons mentionné différentes façons de vérifier votre utilisation de la mémoire PostgreSQL et quel paramètre devez-vous prendre en compte pour l'ajuster, afin d'éviter une utilisation excessive de la mémoire.