Dans mon dernier message ("Mec, à qui appartient cette table #temp ?"), J'ai suggéré que dans SQL Server 2012 et versions ultérieures, vous pourriez utiliser des événements étendus pour surveiller la création de tables #temp. Cela vous permettrait de corréler des objets spécifiques occupant beaucoup d'espace dans tempdb avec la session qui les a créés (par exemple, pour déterminer si la session peut être arrêtée pour essayer de libérer de l'espace). Ce dont je n'ai pas parlé, c'est la surcharge de ce suivi - nous nous attendons à ce que les événements étendus soient plus légers que la trace, mais aucun suivi n'est totalement gratuit.
Comme la plupart des gens laissent la trace par défaut activée, nous la laisserons en place. Nous allons tester les deux tas en utilisant SELECT INTO (que la trace par défaut ne collectera pas) et les index clusterisés (ce qu'elle fera), et nous chronométrons le lot seul comme ligne de base, puis réexécutons le lot avec la session d'événements étendus en cours d'exécution. Nous testerons également à la fois SQL Server 2012 et SQL Server 2014. Le lot lui-même est assez simple :
SET NOCOUNT ON; SELECT SYSDATETIME(); GO -- run this portion for only the heap batch: SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #foo; -- run this portion for only the CIX batch: CREATE TABLE #bar(id INT PRIMARY KEY); INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #bar; GO 100000 SELECT SYSDATETIME();
Les deux instances ont tempdb configuré avec quatre fichiers de données et avec TF 1117 et TF 1118 activés, dans une machine virtuelle avec quatre processeurs, 16 Go de mémoire et uniquement SSD. J'ai intentionnellement créé de petites tables #temp pour amplifier tout impact observé sur le lot lui-même (qui serait noyé si la création des tables #temp prenait beaucoup de temps ou provoquait des événements de croissance automatique excessifs).
J'ai exécuté ces lots dans chaque scénario, et voici les résultats, mesurés en durée de lot en secondes :
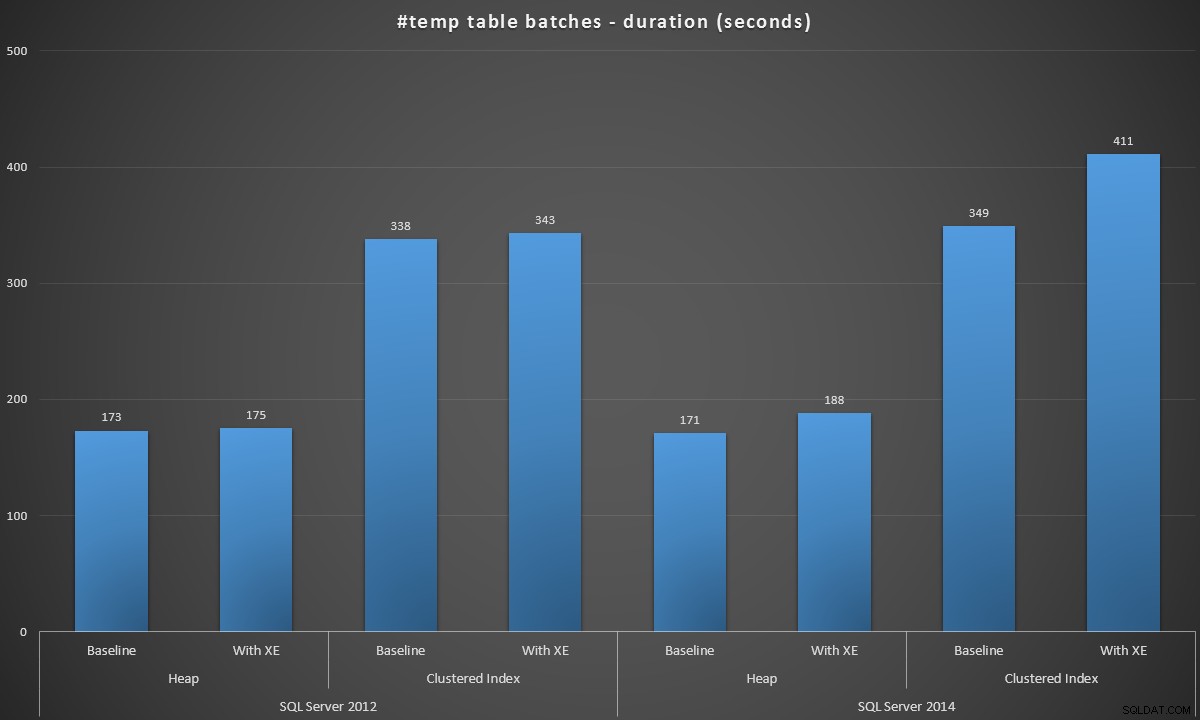
Durée du lot, en secondes, de création de 100 000 tables #temp
En exprimant les données un peu différemment, si nous divisons 100 000 par la durée, nous pouvons afficher le nombre de tables #temp que nous pouvons créer par seconde dans chaque scénario (lire :débit). Voici ces résultats :
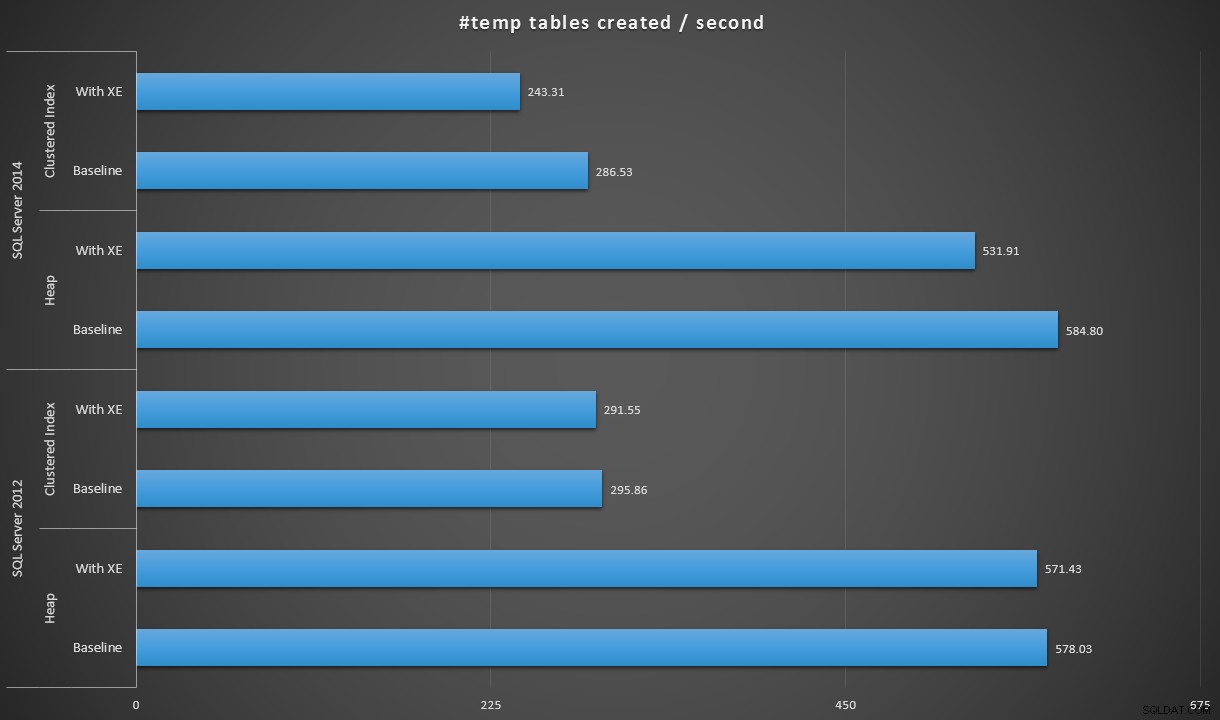
# tables temporaires créées par seconde dans chaque scénario
Les résultats ont été un peu surprenants pour moi - je m'attendais à ce qu'avec les améliorations de SQL Server 2014 dans la logique d'écriture avide, la population de tas s'exécute au moins beaucoup plus rapidement. Le tas en 2014 était de deux maigres secondes plus rapide qu'en 2012 dans la configuration de base, mais les événements étendus ont considérablement augmenté le temps (environ une augmentation de 10 % par rapport à la ligne de base) ; tandis que le temps d'index groupé était comparable à 2012 au niveau de référence, mais a augmenté de près de 18 % avec les événements étendus activés. En 2012, les deltas des tas et des index clusterisés étaient beaucoup plus modestes – 1,1 % et 1,5 % respectivement. (Et pour être clair, aucun événement de croissance automatique ne s'est produit pendant aucun des tests.)
Alors, j'ai pensé, et si je créais une session d'événements étendus plus légère et plus méchante ? Je pourrais sûrement supprimer certaines de ces colonnes d'action - peut-être n'ai-je besoin que du nom de connexion et du spid, et je peux ignorer le nom de l'application, le nom d'hôte et le sql_text potentiellement coûteux. Je pourrais peut-être abandonner le filtre supplémentaire contre la validation (collecte deux fois plus d'événements, mais moins de CPU dépensé pour le filtrage) et autoriser la perte de plusieurs événements pour réduire l'impact potentiel sur la charge de travail. Cette session simplifiée ressemble à ceci :
CREATE EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER
ADD EVENT sqlserver.object_created
(
ACTION
(
sqlserver.server_principal_name,
sqlserver.session_id
)
WHERE
(
sqlserver.like_i_sql_unicode_string([object_name], N'#%')
)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = 'c:\temp\TempTableCreation2014_LeanerMeaner.xel',
MAX_FILE_SIZE = 32768,
MAX_ROLLOVER_FILES = 10
)
WITH
(
EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
);
GO
ALTER EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER STATE = START; Hélas, non, mêmes résultats. Un peu plus de trois minutes pour le tas et un peu moins de sept minutes pour l'index clusterisé. Afin de creuser plus profondément où le temps supplémentaire était passé, j'ai regardé l'instance 2014 avec SQL Sentry, et j'ai exécuté uniquement le lot d'index en cluster sans aucune session d'événements étendus configurée. Ensuite, j'ai réexécuté le lot, cette fois avec la session XE plus légère configurée. Les temps de batch étaient de 5:47 (347 secondes) et 6:55 (415 secondes) – donc tout à fait dans la lignée du batch précédent (j'étais content de voir que notre monitoring ne contribuait plus à la durée :-)) . J'ai validé qu'aucun événement n'a été supprimé et encore une fois qu'aucun événement de croissance automatique ne s'est produit.
J'ai consulté le tableau de bord SQL Sentry en mode historique, ce qui m'a permis de visualiser rapidement les mesures de performances des deux lots côte à côte :
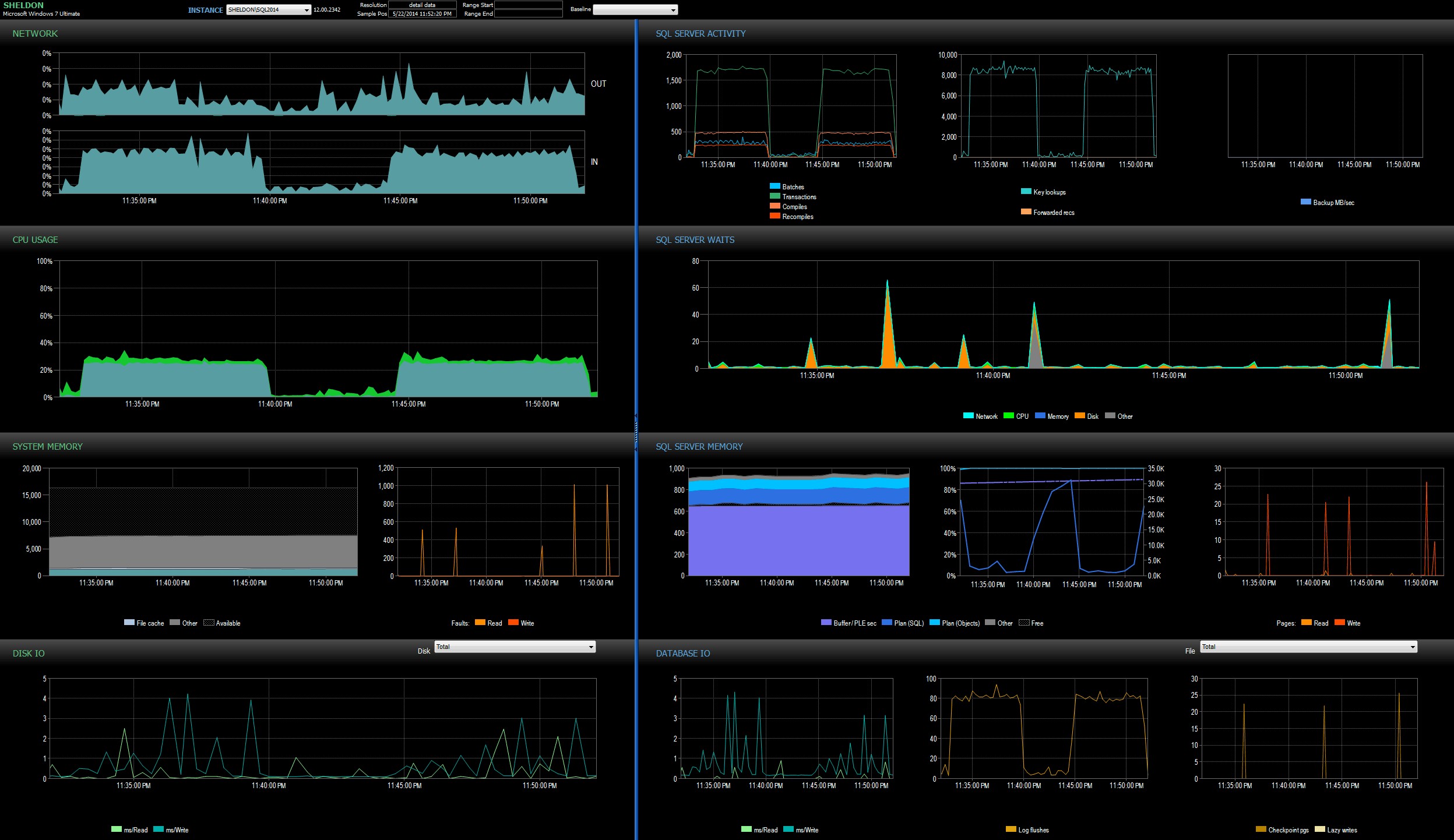
Tableau de bord SQL Sentry, en mode historique, affichant les deux lots
Les deux lots étaient pratiquement identiques en termes de réseau, de processeur, de transactions, de compilations, de recherches de clés, etc. second lot. Ma théorie de travail bien après minuit est qu'une bonne partie du retard observé était peut-être due au changement de contexte causé par le processus des événements étendus. Étant donné que nous n'avons aucune visibilité sur ce que XE fait exactement sous les couvertures, et nous ne savons pas non plus quels mécanismes sous-jacents ont changé dans XE entre 2012 et 2014, c'est l'histoire avec laquelle je vais m'en tenir pour l'instant, jusqu'à ce que je sois plus à l'aise avec xperf et/ou WinDbg.
Conclusion
Dans tous les cas, il est clair que le suivi de la création de tables #temp n'est pas gratuit et que le coût peut varier en fonction du type de tables #temp que vous créez, de la quantité d'informations que vous collectez dans vos sessions XE et même de la version de SQL Server que vous utilisez. Vous pouvez donc exécuter des tests similaires à ce que j'ai fait ici et décider de la valeur de la collecte de ces informations dans votre environnement.