Les données sont probablement l'un des actifs les plus précieux d'une entreprise. Pour cette raison, nous devrions toujours avoir un plan de reprise après sinistre (DRP) pour éviter la perte de données en cas d'accident ou de panne matérielle.
Une sauvegarde est la forme la plus simple de DR, mais elle peut ne pas toujours être suffisante pour garantir un objectif de point de récupération (RPO) acceptable. Il est recommandé d'avoir au moins trois sauvegardes stockées dans des emplacements physiques différents.
La meilleure pratique dicte que les fichiers de sauvegarde doivent en avoir un stocké localement sur le serveur de base de données (pour une récupération plus rapide), un autre sur un serveur de sauvegarde centralisé et le dernier sur le cloud.
Pour ce blog, nous examinerons les options fournies par Amazon AWS pour le stockage des sauvegardes PostgreSQL dans le cloud et nous montrerons quelques exemples sur la façon de le faire.
À propos d'Amazon AWS
Amazon AWS est l'un des fournisseurs de cloud les plus avancés au monde en termes de fonctionnalités et de services, avec des millions de clients. Si nous voulons exécuter nos bases de données PostgreSQL sur Amazon AWS, nous avons quelques options...
-
Amazon RDS :il nous permet de créer, gérer et faire évoluer une base de données PostgreSQL (ou différentes technologies de base de données) dans le cloud de manière simple et rapide.
-
Amazon Aurora :c'est une base de données compatible PostgreSQL conçue pour le cloud. Selon le site Web d'AWS, il est trois fois plus rapide que les bases de données PostgreSQL standard.
-
Amazon EC2 :c'est un service Web qui fournit une capacité de calcul redimensionnable dans le cloud. Il vous offre un contrôle complet de vos ressources informatiques et vous permet de paramétrer et de configurer tout ce qui concerne vos instances, de votre système d'exploitation à vos applications.
Mais, en fait, nous n'avons pas besoin que nos bases de données fonctionnent sur Amazon pour stocker nos sauvegardes ici.
Stockage des sauvegardes sur Amazon AWS
Il existe différentes options pour stocker notre sauvegarde PostgreSQL sur AWS. Si nous exécutons notre base de données PostgreSQL sur AWS, nous avons plus d'options et (comme nous sommes sur le même réseau), cela pourrait également être plus rapide. Voyons comment AWS peut nous aider à stocker nos sauvegardes.
AWS CLI
Tout d'abord, préparons notre environnement pour tester les différentes options AWS. Pour nos exemples, nous utiliserons un serveur PostgreSQL 11 sur site, exécuté sur CentOS 7. Ici, nous devons installer l'AWS CLI en suivant les instructions de ce site.
Lorsque nous avons installé notre AWS CLI, nous pouvons le tester à partir de la ligne de commande :
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Maintenant, l'étape suivante consiste à configurer notre nouveau client exécutant la commande aws avec l'option configure.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Pour obtenir ces informations, vous pouvez accéder à la section IAM AWS et vérifier l'utilisateur actuel, ou si vous préférez, vous pouvez en créer un nouveau pour cette tâche.
Après cela, nous sommes prêts à utiliser l'AWS CLI pour accéder à nos services Amazon AWS.
Amazon S3
C'est probablement l'option la plus couramment utilisée pour stocker les sauvegardes dans le cloud. Amazon S3 peut stocker et récupérer n'importe quelle quantité de données depuis n'importe où sur Internet. Il s'agit d'un service de stockage simple qui offre une infrastructure de stockage de données extrêmement durable, hautement disponible et infiniment évolutive à faible coût.
Amazon S3 fournit une interface de service Web simple que vous pouvez utiliser pour stocker et récupérer n'importe quelle quantité de données, à tout moment, depuis n'importe où sur le Web, et (avec l'AWS CLI ou le SDK AWS) vous peut l'intégrer à différents systèmes et langages de programmation.
Comment l'utiliser
Amazon S3 utilise des compartiments. Ce sont des conteneurs uniques pour tout ce que vous stockez dans Amazon S3. Ainsi, la première étape consiste à accéder à la console de gestion Amazon S3 et à créer un nouveau compartiment.
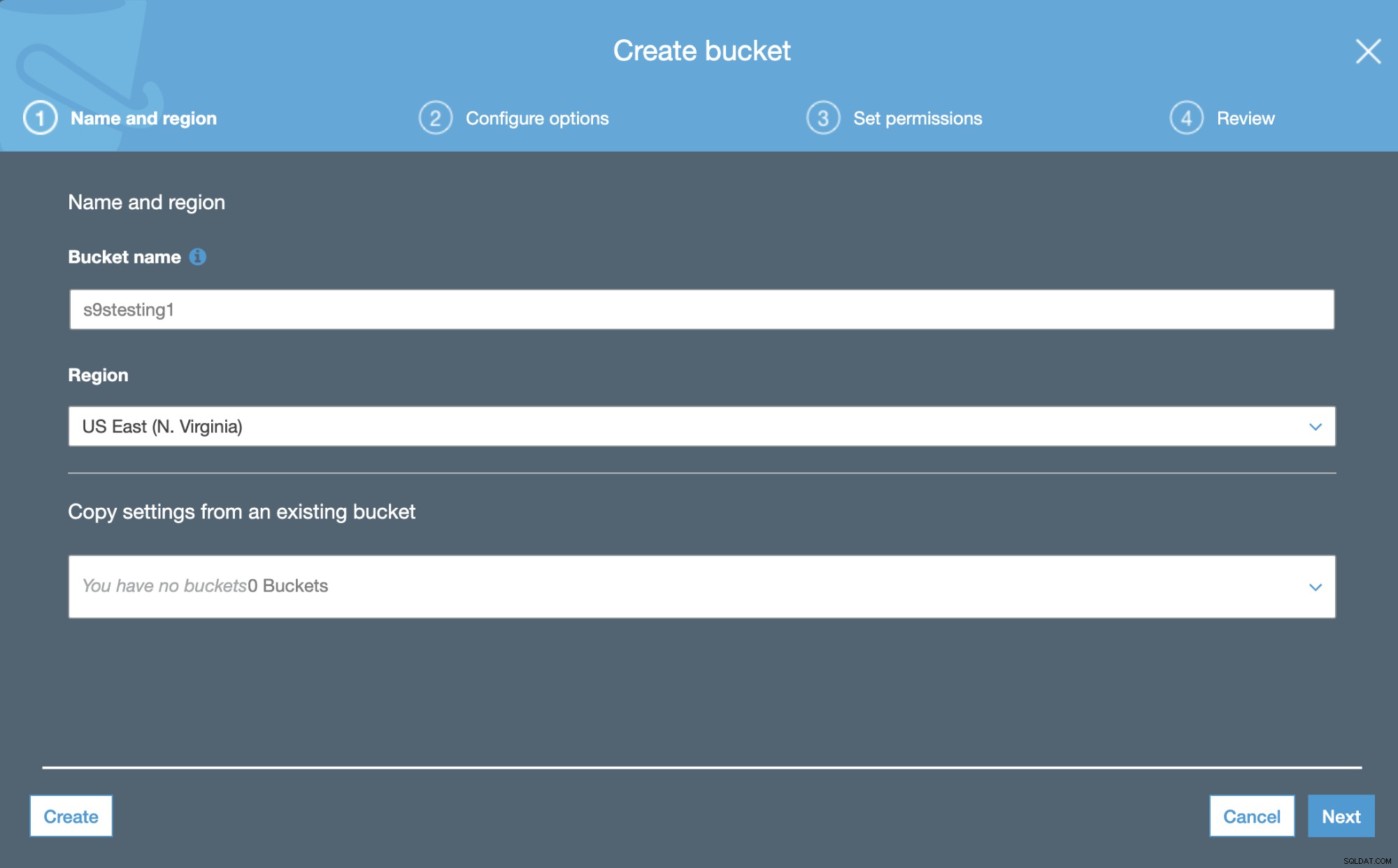
Dans la première étape, nous avons juste besoin d'ajouter le nom du compartiment et le Région AWS.
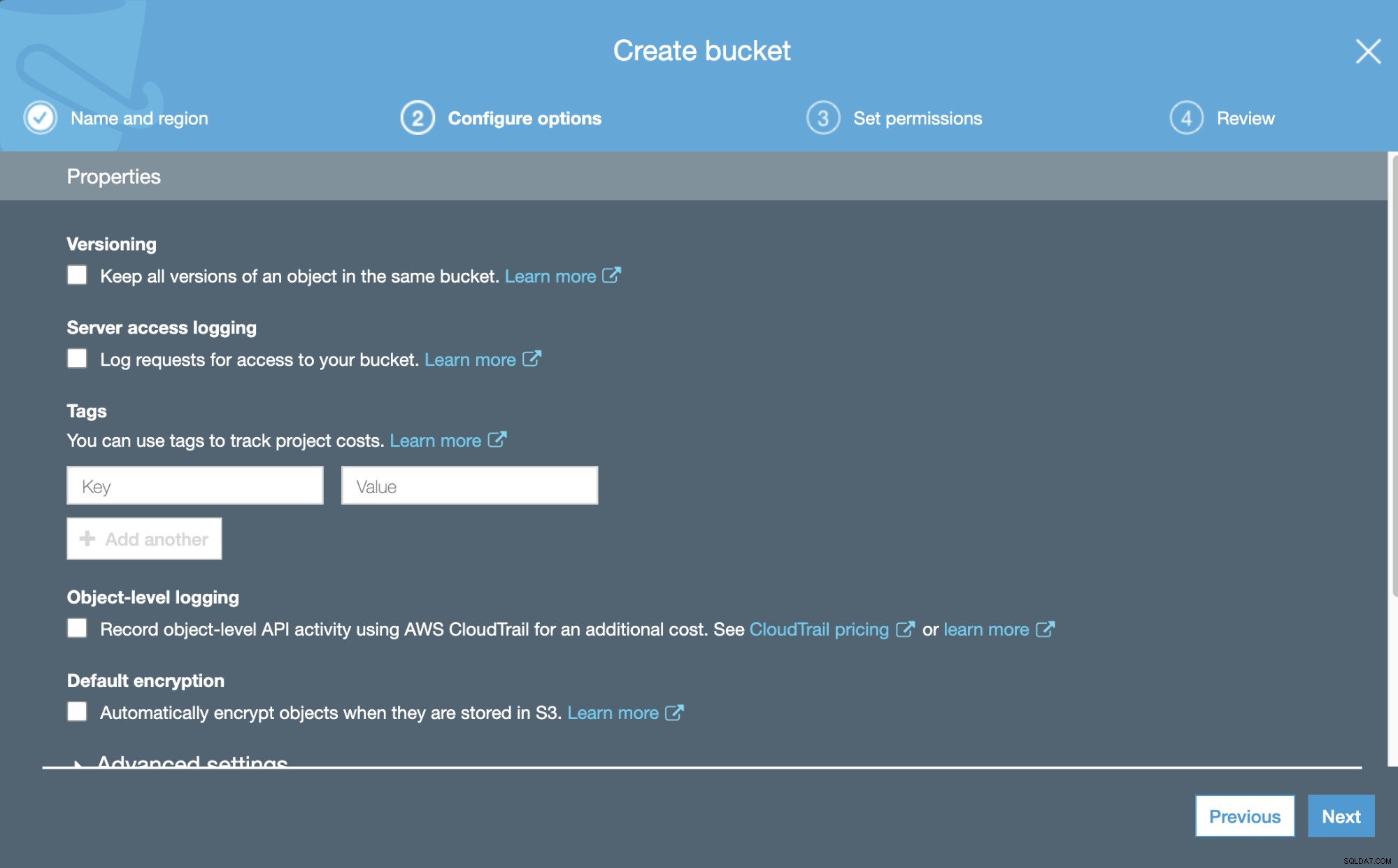
Maintenant, nous pouvons configurer certains détails sur notre nouveau Bucket, comme la gestion des versions et journalisation.

Et ensuite, nous pouvons spécifier les autorisations pour ce nouveau compartiment.
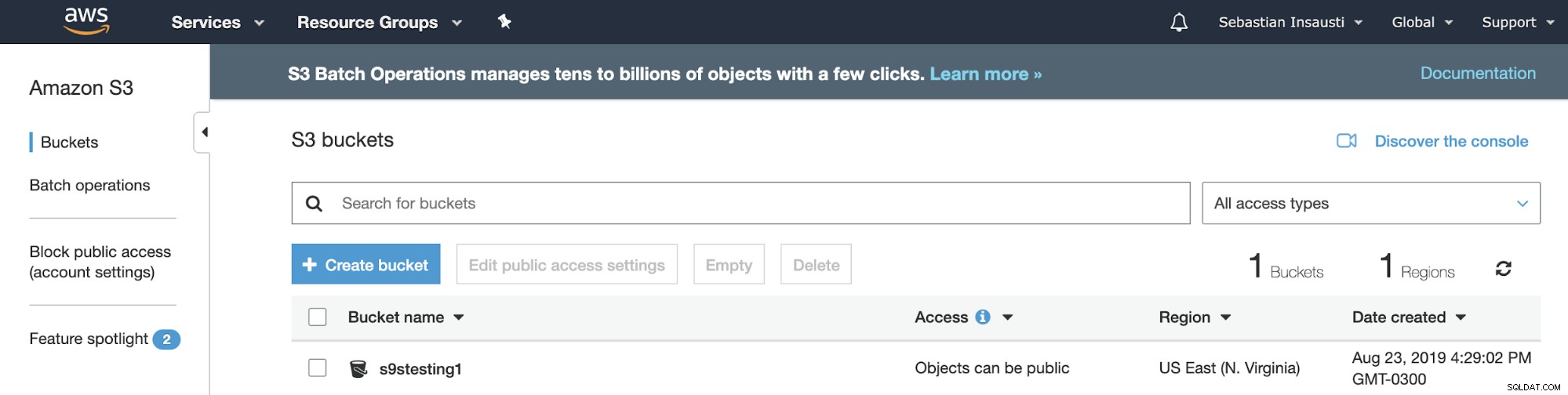
Maintenant que nous avons créé notre seau, voyons comment nous pouvons l'utiliser pour stocker nos sauvegardes PostgreSQL.
Tout d'abord, testons notre client en le connectant à S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Ça marche ! Avec la commande précédente, nous listons les Buckets actuellement créés.
Donc, maintenant, nous pouvons simplement télécharger la sauvegarde sur le service S3. Pour cela, nous pouvons utiliser la commande aws sync ou aws cp.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Nous pouvons vérifier le contenu du compartiment à partir du site Web d'AWS.
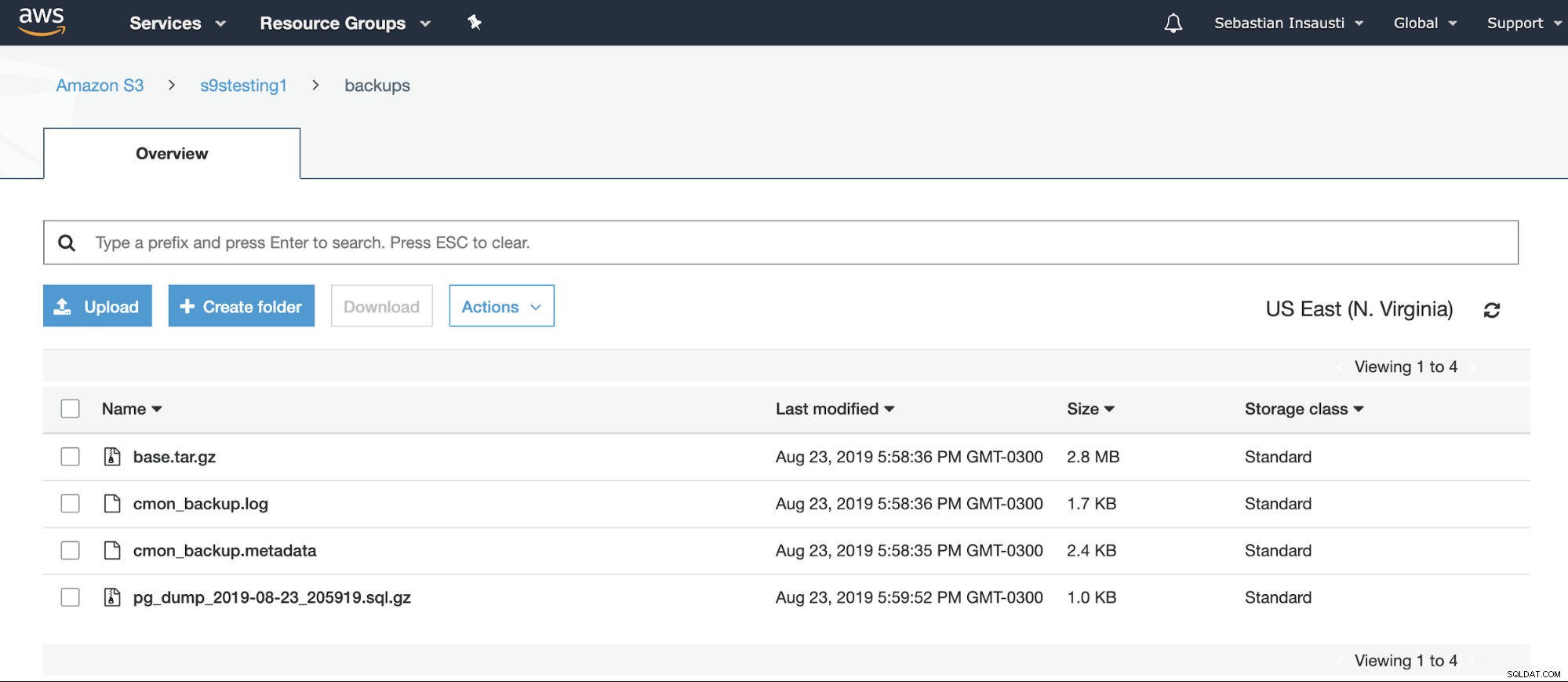
Ou même en utilisant l'AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzPour plus d'informations sur l'AWS S3 CLI, vous pouvez consulter la documentation AWS officielle.
Glacier Amazon S3
Il s'agit de la version la moins chère d'Amazon S3. La principale différence entre eux est la vitesse et l'accessibilité. Vous pouvez utiliser Amazon S3 Glacier si le coût du stockage doit rester faible et si vous n'avez pas besoin d'un accès d'une milliseconde à vos données. L'utilisation est une autre différence importante entre eux.
Comment l'utiliser
Au lieu de compartiments, Amazon S3 Glacier utilise des coffres. C'est un conteneur pour stocker n'importe quel objet. Ainsi, la première étape consiste à accéder à la console de gestion Amazon S3 Glacier et à créer un nouveau coffre-fort.
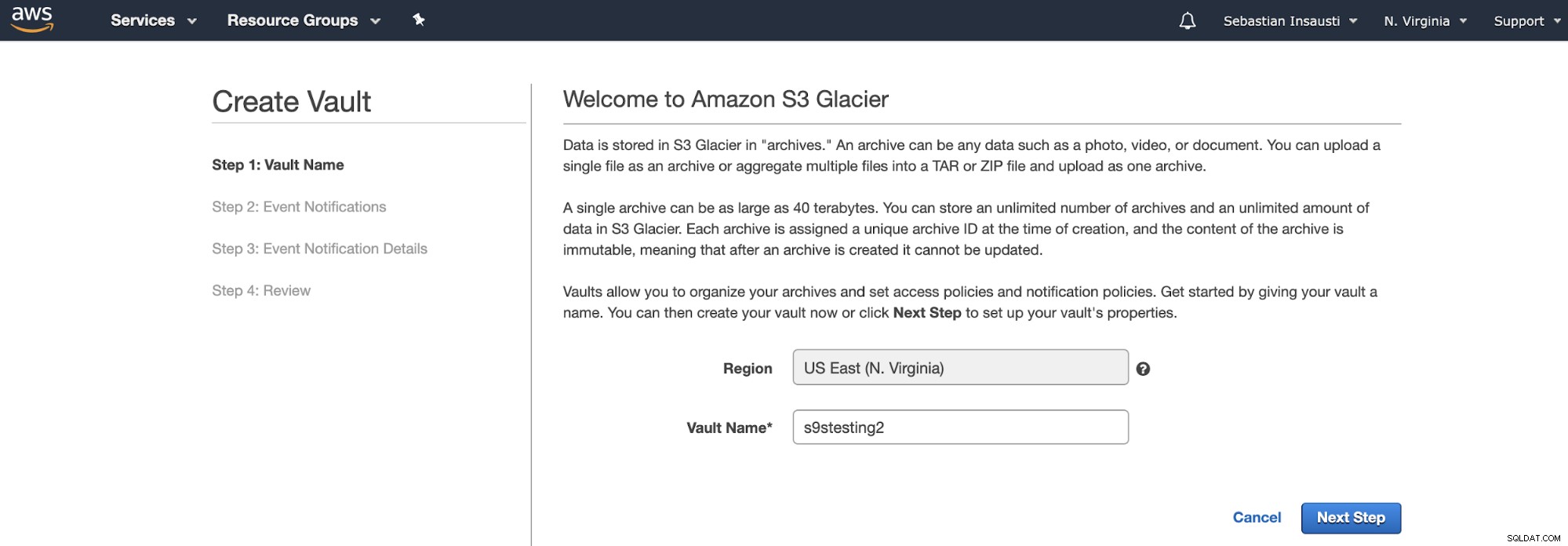
Ici, nous devons ajouter le nom du coffre-fort et la région et, dans l'étape suivante, nous pouvons activer les notifications d'événements qui utilisent Amazon Simple Notification Service (Amazon SNS).
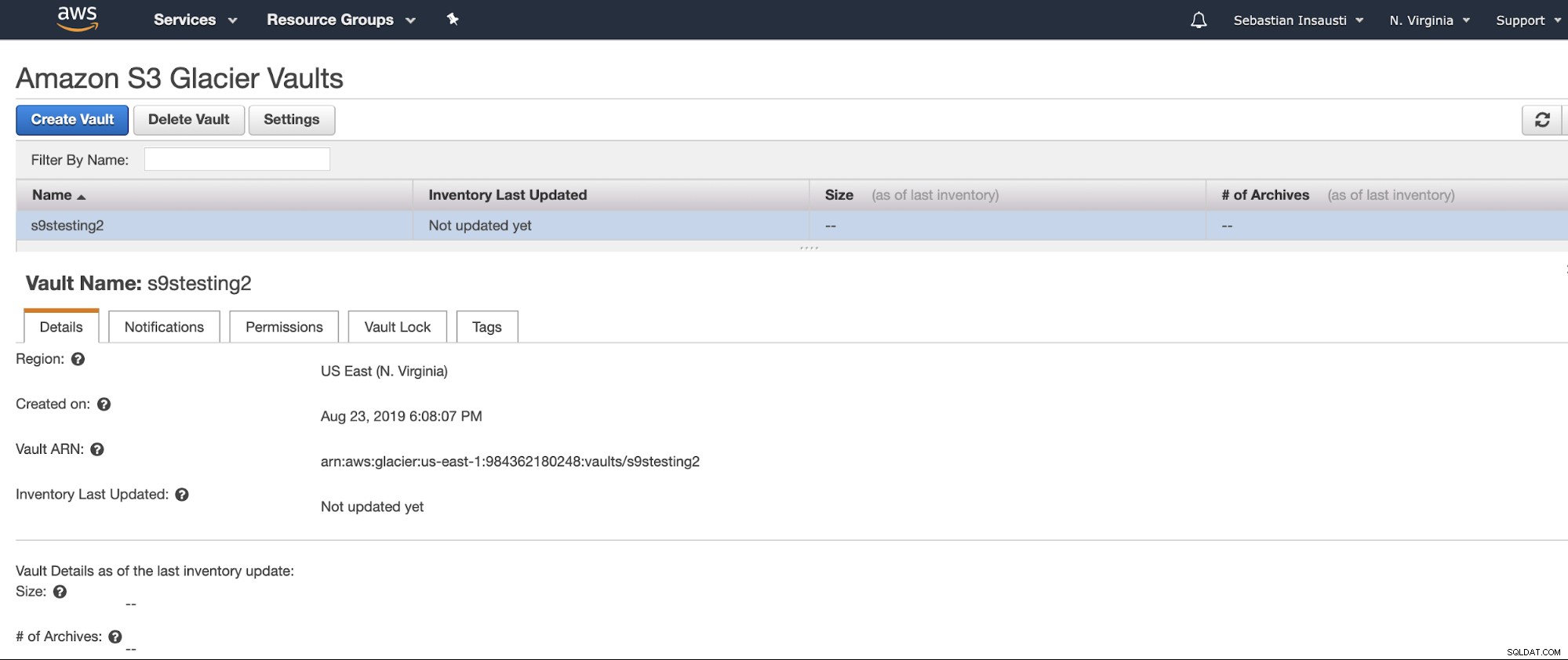
Maintenant que nous avons créé notre coffre-fort, nous pouvons y accéder depuis l'AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Ça marche. Alors maintenant, nous pouvons télécharger notre sauvegarde ici.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Une chose importante est que l'état du coffre-fort est mis à jour environ une fois par jour, nous devons donc attendre de voir le fichier téléchargé.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Voici notre fichier téléchargé sur notre S3 Glacier Vault.
Pour plus d'informations sur AWS Glacier CLI, vous pouvez consulter la documentation AWS officielle.
EC2
Cette option de magasin de sauvegarde est la plus coûteuse et la plus longue, mais elle est utile si vous souhaitez avoir un contrôle total sur l'environnement de stockage de sauvegarde et souhaitez effectuer des tâches personnalisées sur les sauvegardes (par exemple, la vérification de la sauvegarde .)
Amazon EC2 (Elastic Compute Cloud) est un service Web qui fournit une capacité de calcul redimensionnable dans le cloud. Il vous offre un contrôle complet de vos ressources informatiques et vous permet de tout mettre en place et configurer sur vos instances depuis votre système d'exploitation jusqu'à vos applications. Il vous permet également d'augmenter rapidement la capacité, à la hausse comme à la baisse, en fonction de l'évolution de vos besoins informatiques.
Amazon EC2 prend en charge différents systèmes d'exploitation comme Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux et FreeBSD.
Comment l'utiliser
Allez dans la section Amazon EC2 et appuyez sur Launch Instance. Dans un premier temps, vous devez choisir le système d'exploitation de l'instance EC2.
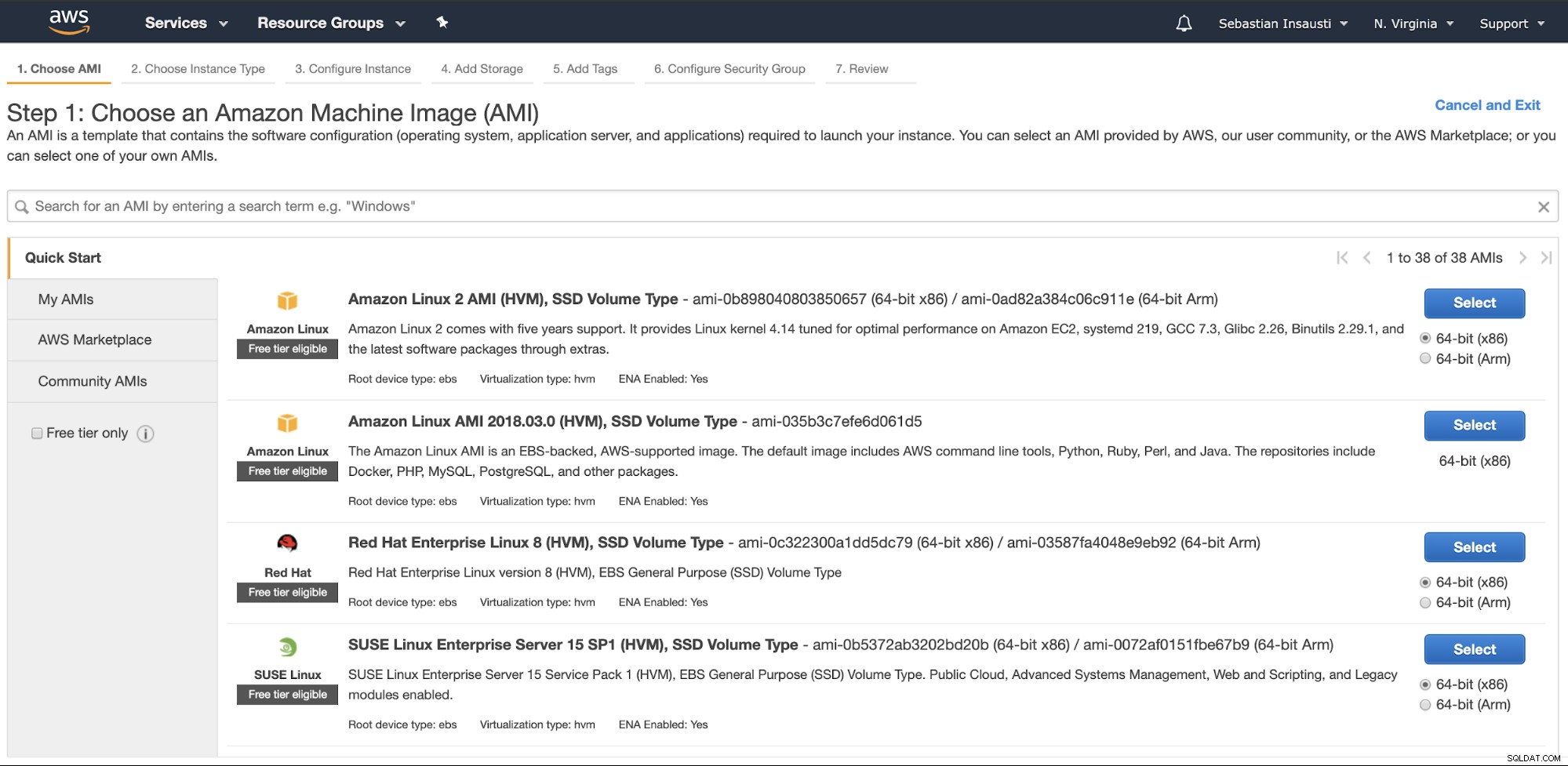
À l'étape suivante, vous devez choisir les ressources pour la nouvelle instance.
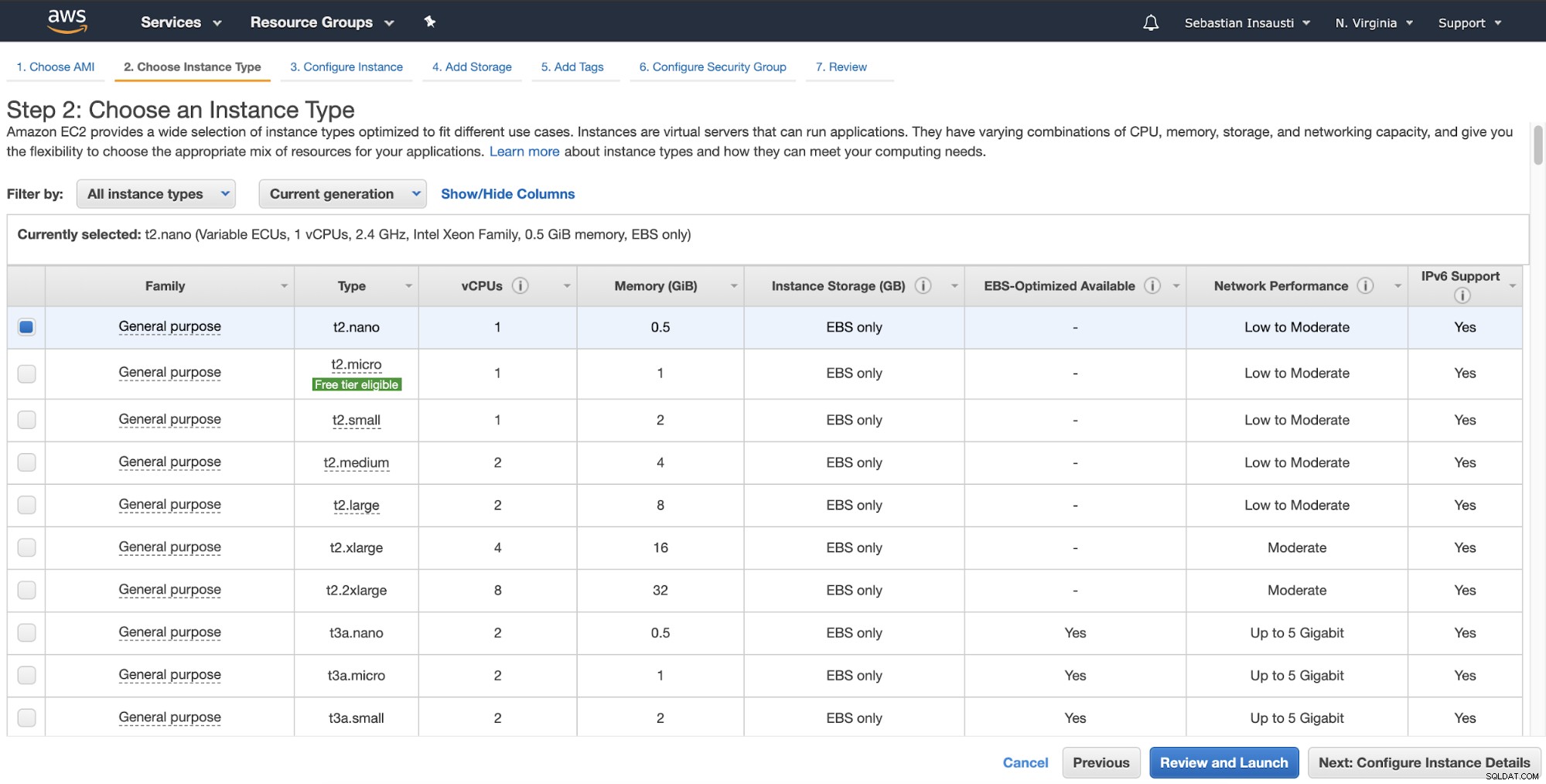
Ensuite, vous pouvez spécifier une configuration plus détaillée comme le réseau, le sous-réseau, etc. .
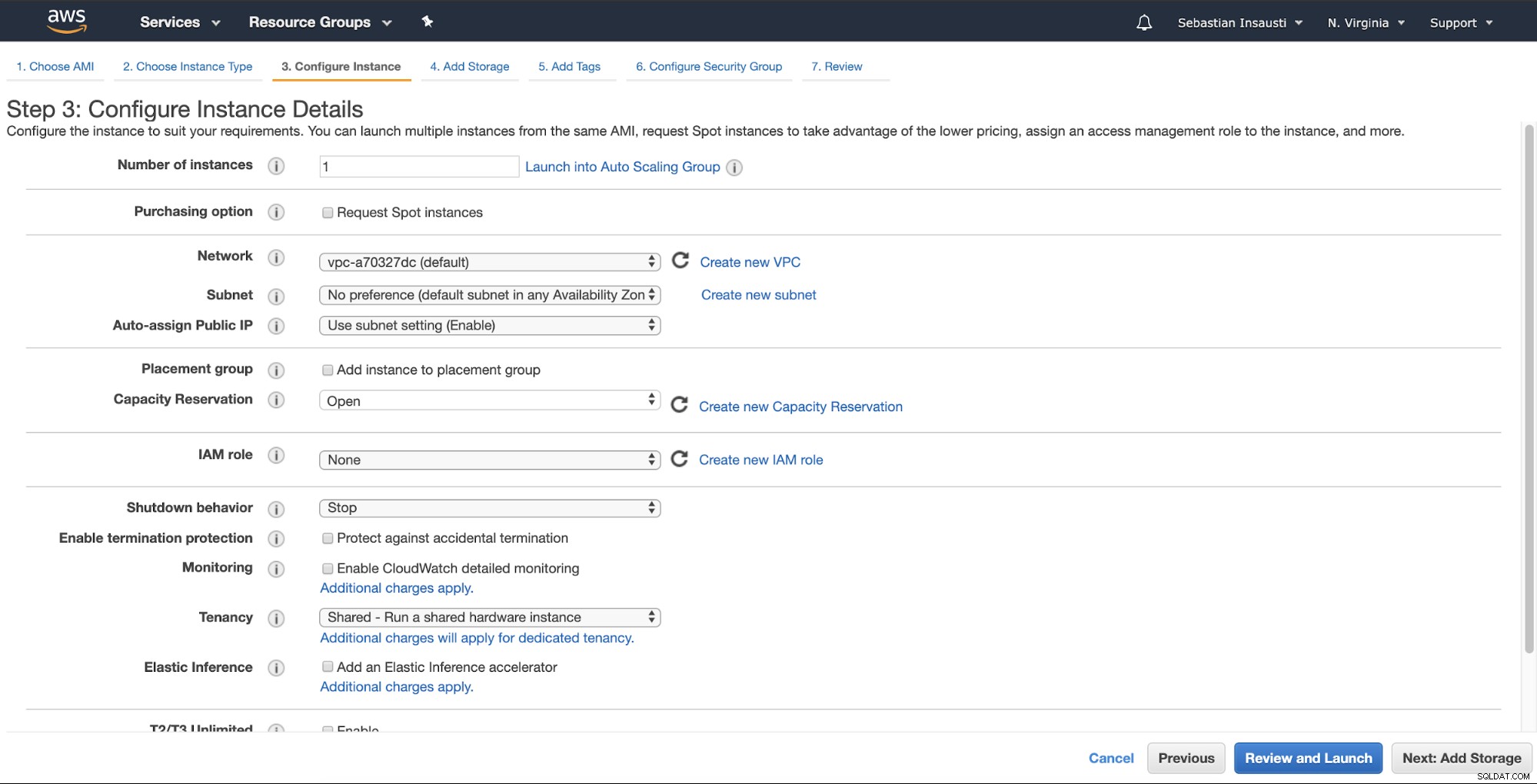
Maintenant, nous pouvons ajouter plus de capacité de stockage sur cette nouvelle instance, et comme un serveur de sauvegarde, nous devrions le faire.
Lorsque nous avons terminé la tâche de création, nous pouvons accéder à la section Instances pour voir notre nouvelle instance EC2.
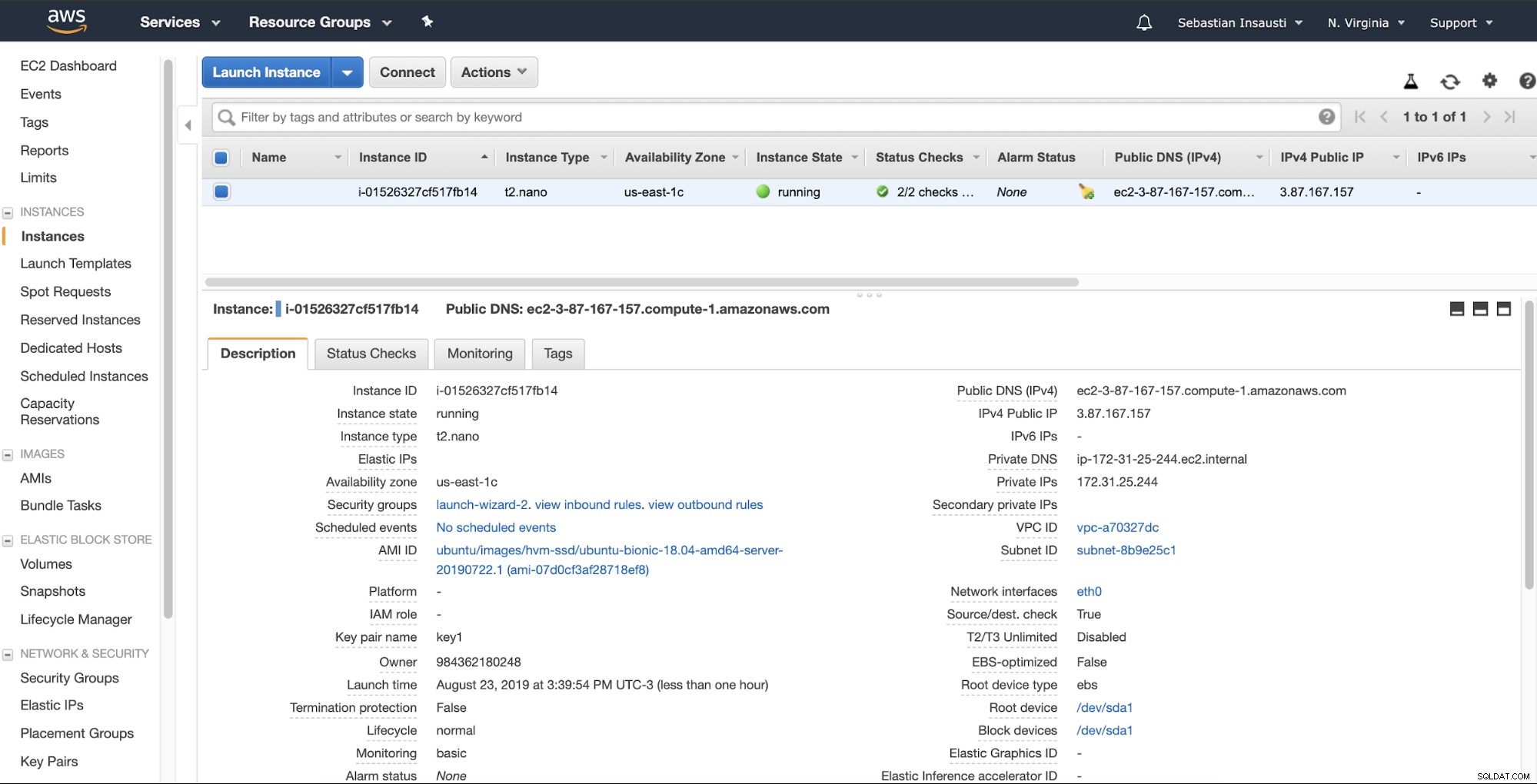
Lorsque l'instance est prête (état de l'instance en cours d'exécution), vous pouvez stocker le sauvegardes ici, par exemple, en l'envoyant via SSH ou FTP en utilisant le DNS public créé par AWS. Voyons un exemple avec Rsync et un autre avec la commande SCP Linux.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00Sauvegarde AWS
AWS Backup est un service de sauvegarde centralisé qui vous offre des fonctionnalités de gestion des sauvegardes, telles que la planification des sauvegardes, la gestion de la rétention et la surveillance des sauvegardes, ainsi que des fonctionnalités supplémentaires, telles que les sauvegardes à cycle de vie vers un système à faible coût. niveau de stockage, stockage de sauvegarde et chiffrement indépendant de ses données source et politiques d'accès aux sauvegardes.
Vous pouvez utiliser AWS Backup pour gérer les sauvegardes des volumes EBS, des bases de données RDS, des tables DynamoDB, des systèmes de fichiers EFS et des volumes Storage Gateway.
Comment l'utiliser
Accédez à la section AWS Backup sur AWS Management Console.
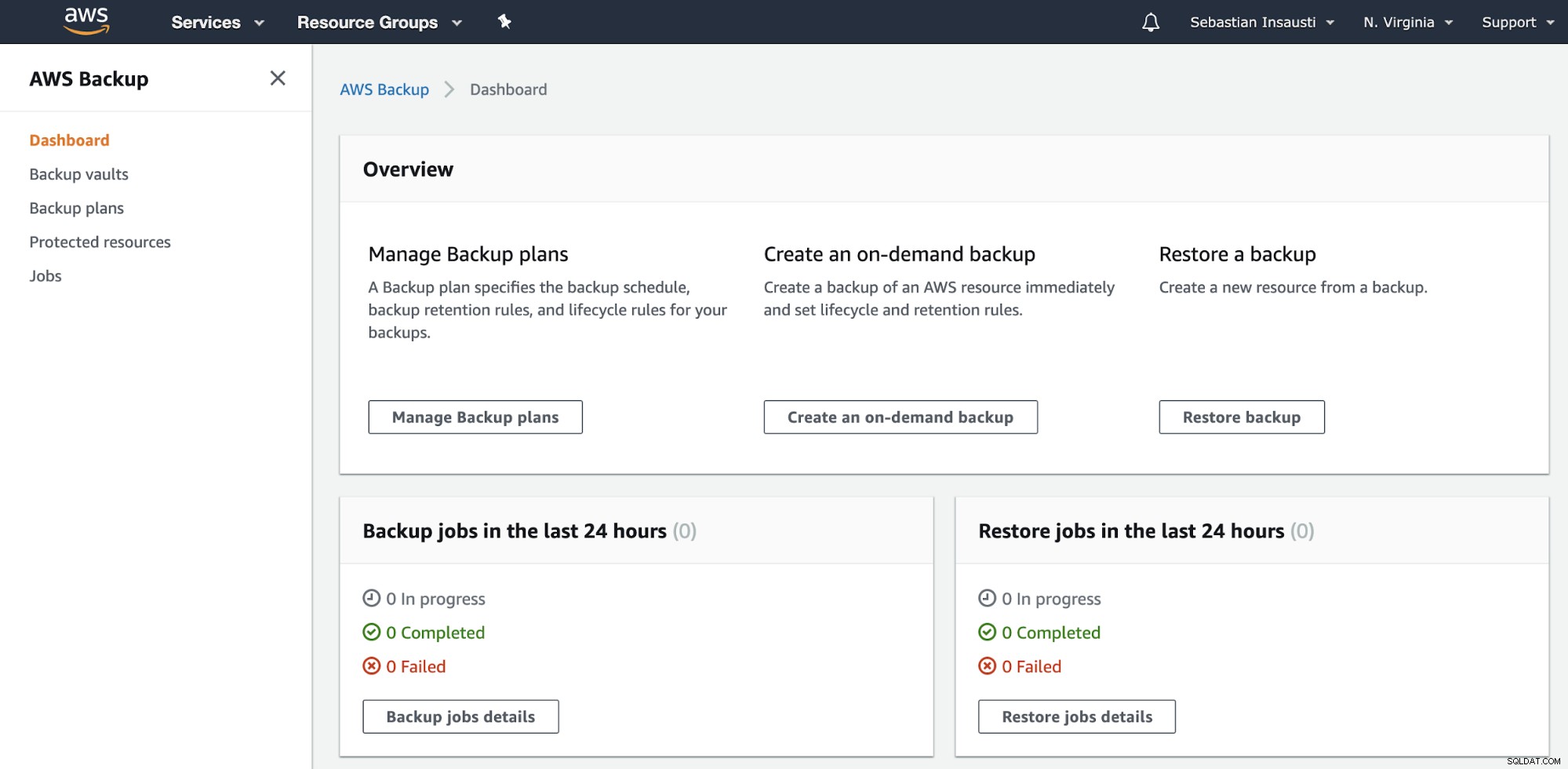
Ici, vous avez différentes options, telles que Planifier, Créer ou Restaurer une sauvegarde . Voyons comment créer une nouvelle sauvegarde.
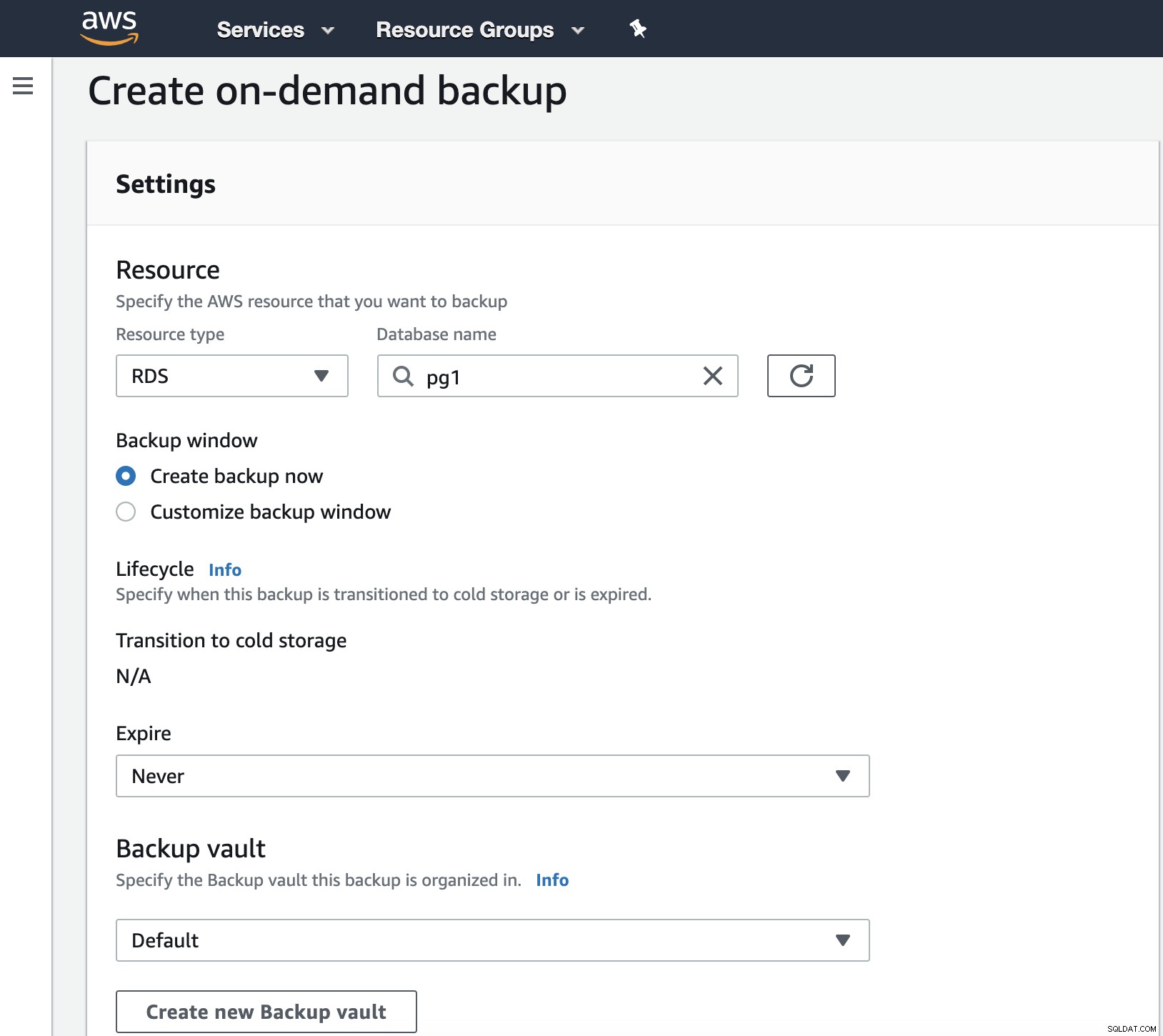
Dans cette étape, nous devons choisir le type de ressource qui peut être DynamoDB, RDS, EBS, EFS ou Storage Gateway, et plus de détails comme la date d'expiration, le coffre-fort de sauvegarde et le rôle IAM.
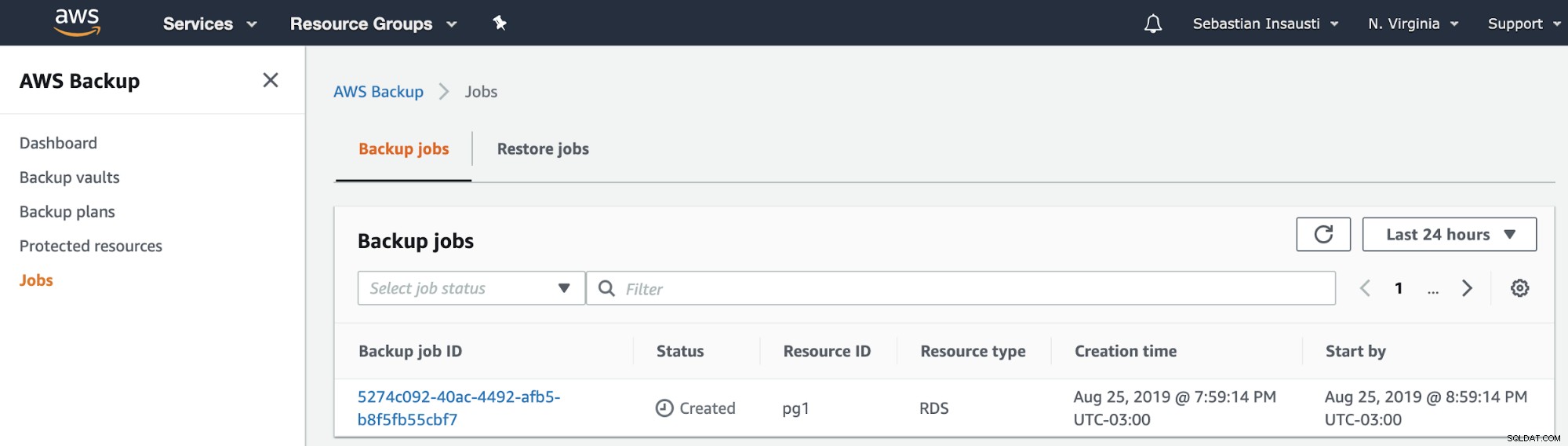
Ensuite, nous pouvons voir la nouvelle tâche créée dans la section AWS Backup Jobs .
Instantané
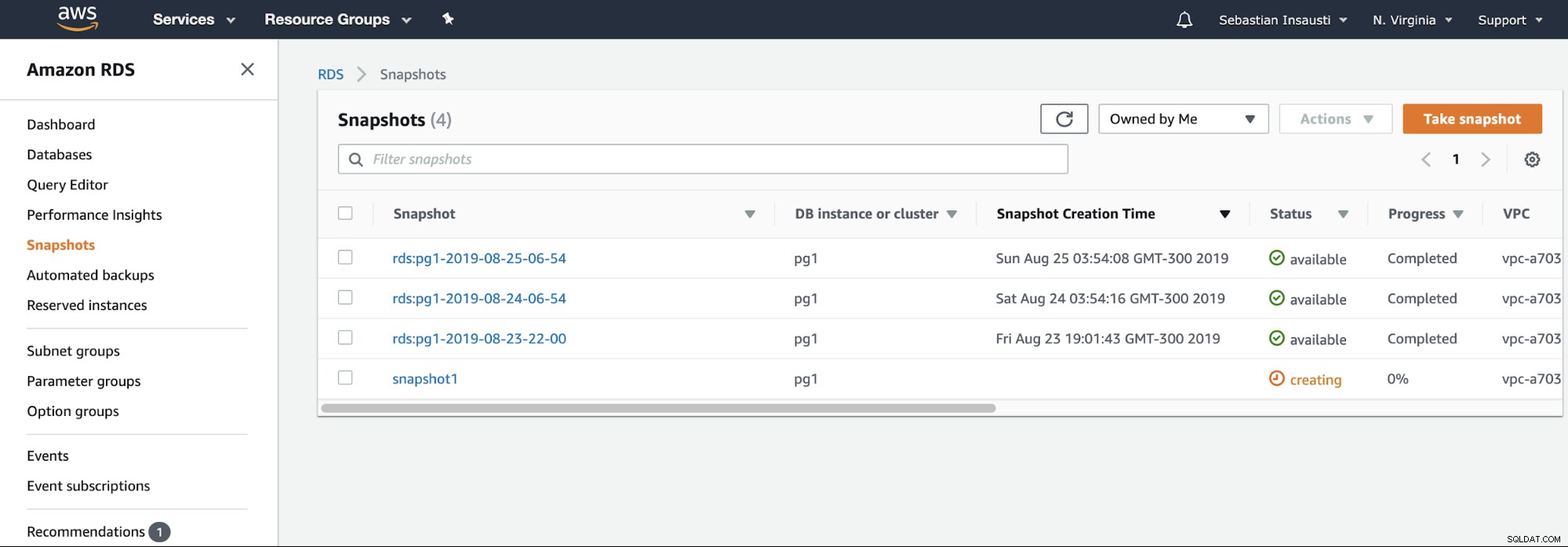
Maintenant, nous pouvons mentionner cette option connue dans tous les environnements de virtualisation. L'instantané est une sauvegarde effectuée à un moment précis, et AWS nous permet de l'utiliser pour les produits AWS. Prenons un exemple d'instantané RDS.
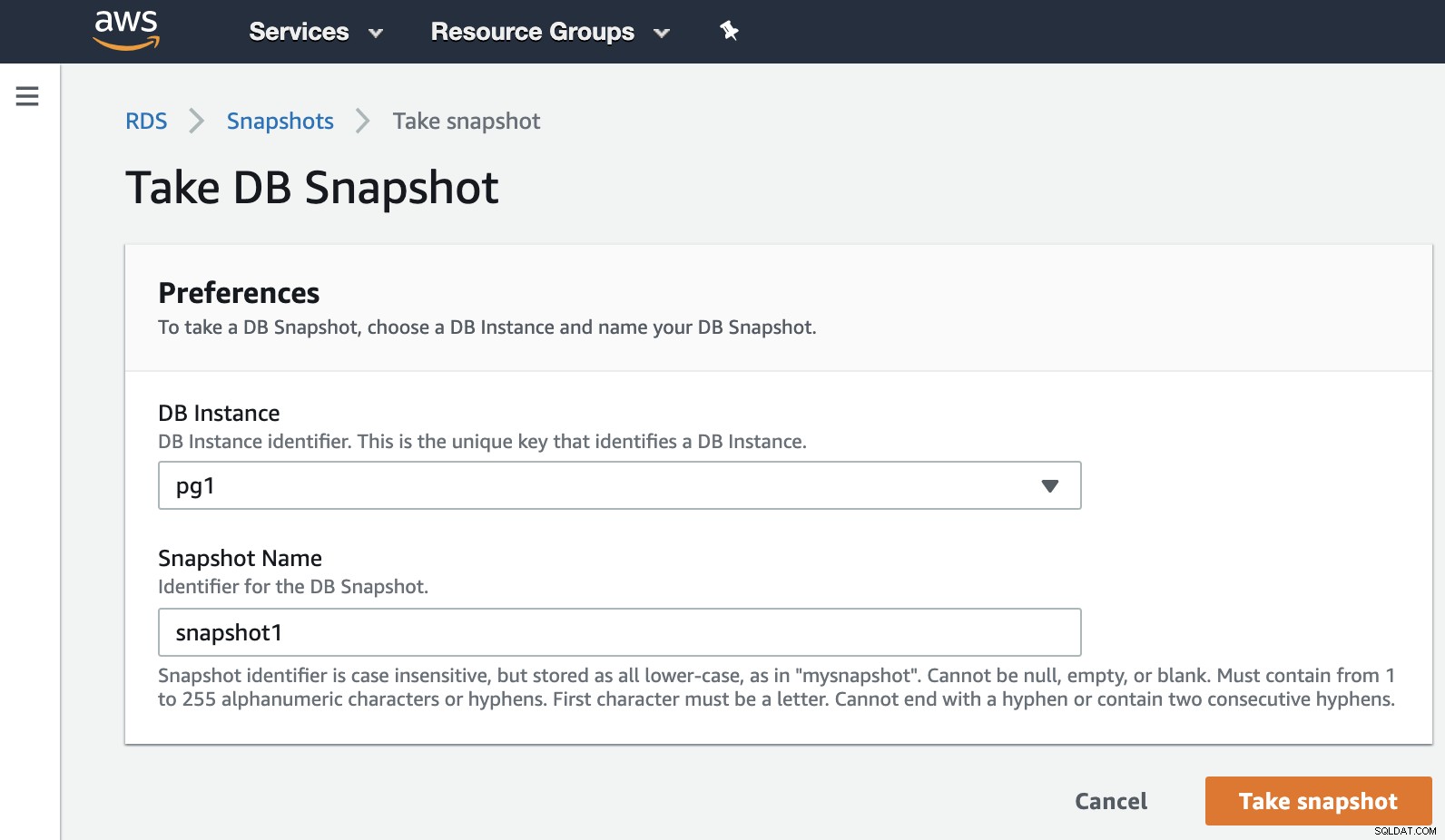
Il nous suffit de choisir l'instance et d'ajouter le nom de l'instantané, et c'est ce. Nous pouvons voir cet instantané et l'instantané précédent dans la section Instantané RDS.
Gérer vos sauvegardes avec ClusterControl
ClusterControl est un système de gestion complet pour les bases de données open source qui automatise les fonctions de déploiement et de gestion, ainsi que la surveillance de la santé et des performances. ClusterControl prend en charge le déploiement, la gestion, la surveillance et la mise à l'échelle pour différentes technologies et environnements de base de données, EC2 inclus. Ainsi, nous pouvons, par exemple, créer notre instance EC2 sur AWS, et déployer/importer notre service de base de données avec ClusterControl.

Création d'une sauvegarde
Pour cette tâche, accédez à ClusterControl -> Sélectionnez Cluster -> Sauvegarde -> Créer une sauvegarde.
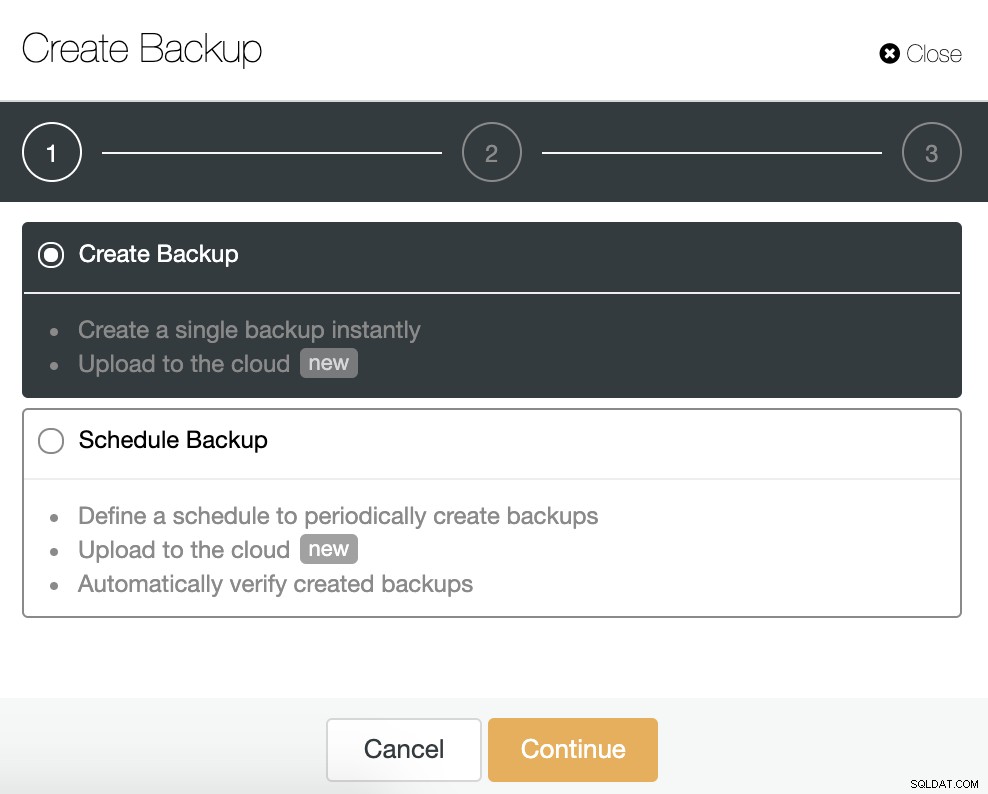
Nous pouvons créer une nouvelle sauvegarde ou en configurer une planifiée. Pour notre exemple, nous allons créer une seule sauvegarde instantanément.
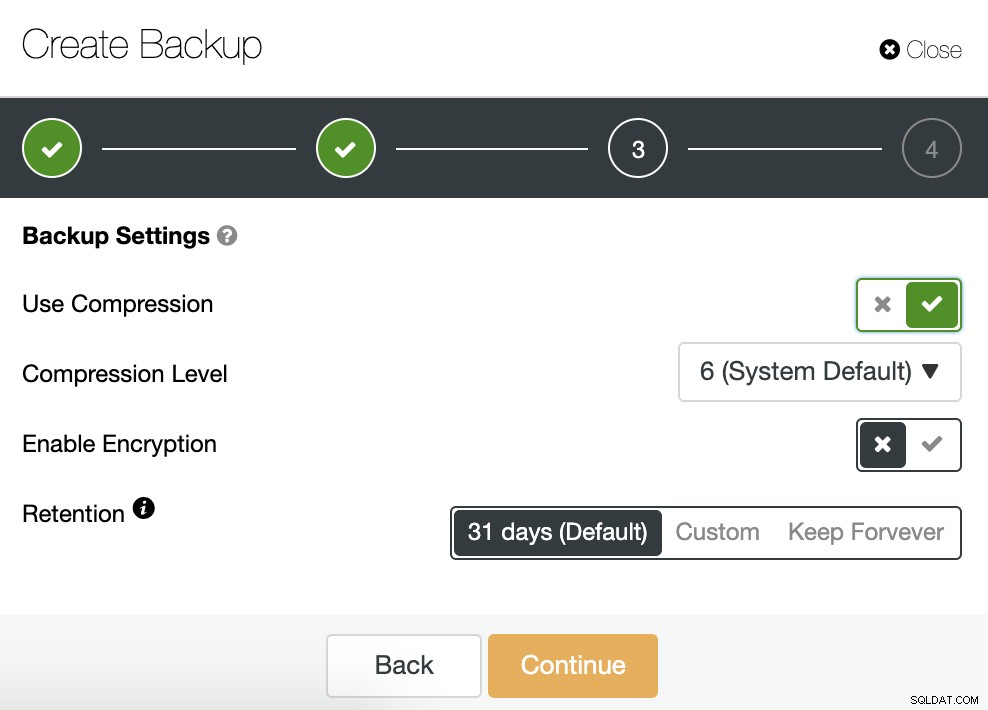
Nous devons choisir une méthode, le serveur à partir duquel la sauvegarde sera prise , et où nous voulons stocker la sauvegarde. Nous pouvons également télécharger notre sauvegarde sur le cloud (AWS, Google ou Azure) en activant le bouton correspondant.
Ensuite, nous spécifions l'utilisation de la compression, le niveau de compression, le chiffrement et la rétention période pour notre sauvegarde.
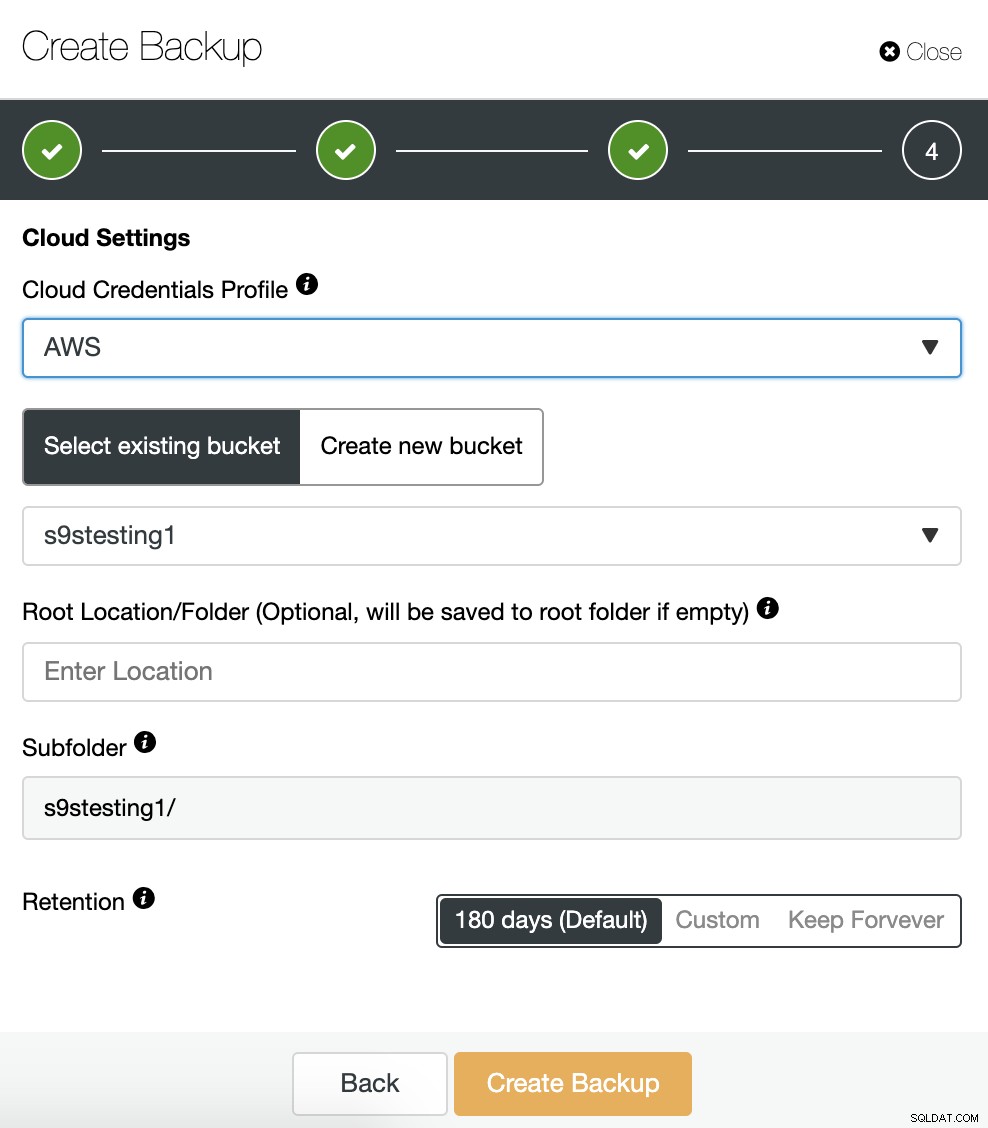
Si nous avons activé l'option de sauvegarde de téléchargement vers le cloud, nous verrons une section pour spécifier le fournisseur de cloud (dans ce cas AWS) et les informations d'identification (ClusterControl -> Intégrations -> Fournisseurs de cloud). Pour AWS, il utilise le service S3, nous devons donc sélectionner un Bucket ou même en créer un nouveau pour stocker nos sauvegardes.
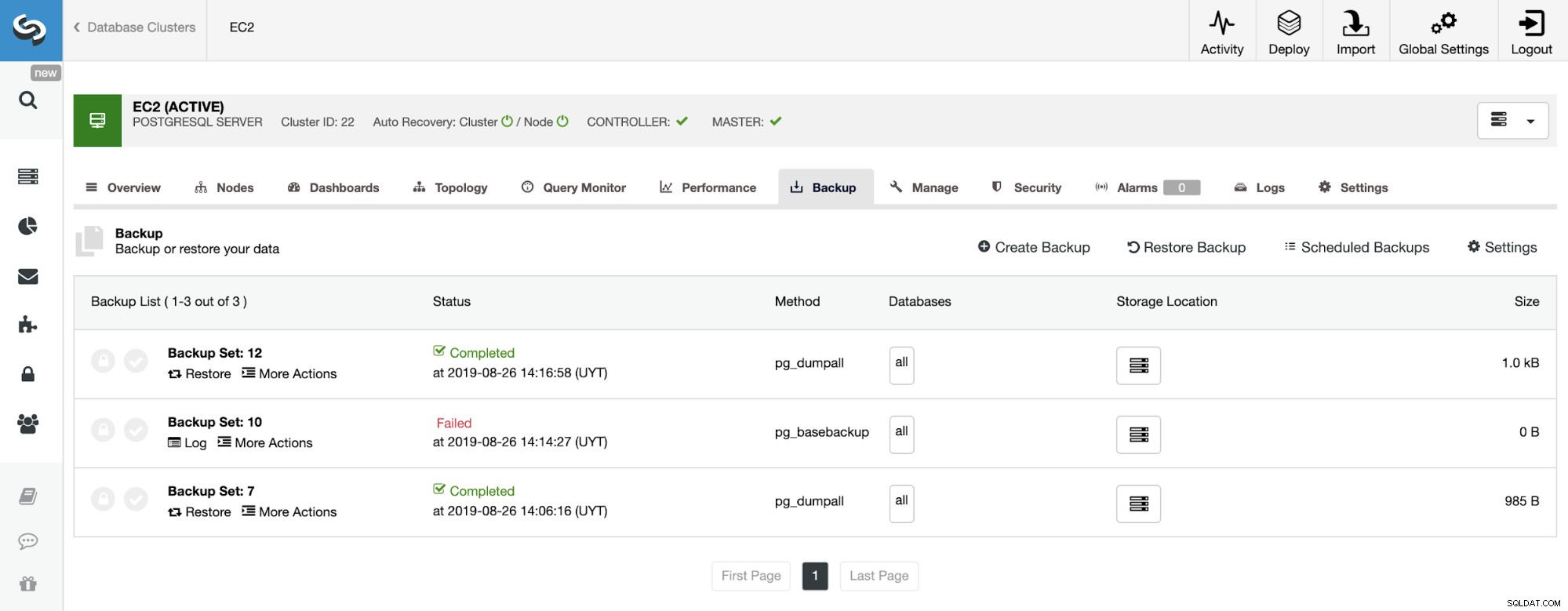
Sur la section de sauvegarde, nous pouvons voir la progression de la sauvegarde, et des informations telles que la méthode, la taille, l'emplacement, etc.
Conclusion
Amazon AWS nous permet de stocker nos sauvegardes PostgreSQL, que nous l'utilisions comme fournisseur cloud de base de données ou non. Pour avoir un plan de sauvegarde efficace, vous devez envisager de stocker au moins une copie de sauvegarde de la base de données dans le cloud pour éviter la perte de données en cas de panne matérielle dans un autre magasin de sauvegarde. Le cloud vous permet de stocker autant de sauvegardes que vous souhaitez stocker ou payer.