Dans tous les moteurs de bases de données relationnelles, il est nécessaire de générer un meilleur plan possible qui correspond à l'exécution de la requête avec le moins de temps et de ressources. Généralement, toutes les bases de données génèrent des plans dans un format arborescent, où le nœud feuille de chaque arbre de plan est appelé nœud de balayage de table. Ce nœud particulier du plan correspond à l'algorithme à utiliser pour récupérer les données de la table de base.
Par exemple, considérez un exemple de requête simple comme SELECT * FROM TBL1, TBL2 where TBL2.ID>1000 ; et supposons que le plan généré est le suivant :
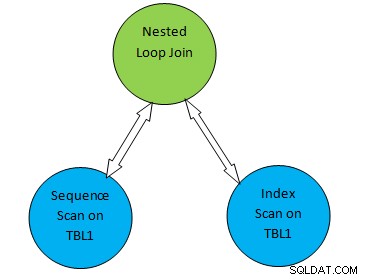
Ainsi, dans l'arborescence du plan ci-dessus, "Analyse séquentielle sur TBL1" et " Balayage d'index sur TBL2 » correspond à la méthode de balayage de table sur la table TBL1 et TBL2 respectivement. Ainsi, selon ce plan, TBL1 sera récupéré séquentiellement à partir des pages correspondantes et TBL2 sera accessible à l'aide de INDEX Scan.
Choisir la bonne méthode d'analyse dans le cadre du plan est très important en termes de performances globales des requêtes.
Avant d'aborder tous les types de méthodes d'analyse prises en charge par PostgreSQL, révisons quelques-uns des principaux points clés qui seront fréquemment utilisés au fur et à mesure que nous parcourrons le blog.
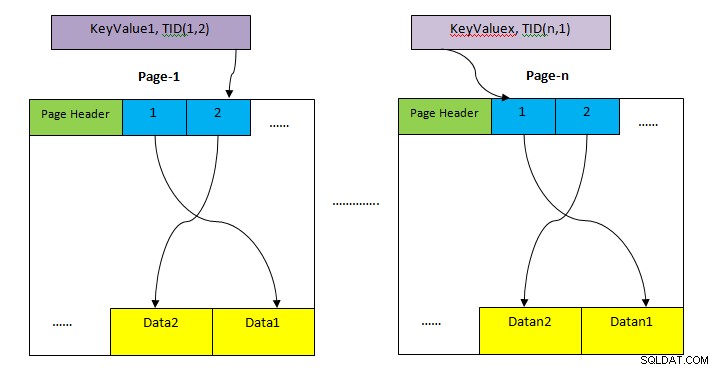
- TAS : Zone de stockage pour stocker toute la rangée de la table. Celui-ci est divisé en plusieurs pages (comme indiqué dans l'image ci-dessus) et chaque taille de page est par défaut de 8 Ko. Dans chaque page, chaque pointeur d'élément (par exemple, 1, 2, ….) pointe vers des données dans la page.
- Stockage d'index : Ce stockage ne stocke que les valeurs de clé, c'est-à-dire la valeur des colonnes contenue par l'index. Il est également divisé en plusieurs pages et chaque taille de page est par défaut de 8 Ko.
- Identifiant de tuple (TID) : TID est un nombre de 6 octets qui se compose de deux parties. La première partie est un numéro de page de 4 octets et un index de tuple de 2 octets restants à l'intérieur de la page. La combinaison de ces deux nombres pointe de manière unique vers l'emplacement de stockage d'un tuple particulier.
Actuellement, PostgreSQL prend en charge les méthodes d'analyse ci-dessous grâce auxquelles toutes les données requises peuvent être lues à partir de la table :
- Analyse séquentielle
- Analyse de l'index
- Analyse d'index uniquement
- Numérisation bitmap
- Analyse TID
Chacune de ces méthodes d'analyse est également utile en fonction de la requête et d'autres paramètres, par ex. cardinalité de table, sélectivité de table, coût d'E/S de disque, coût d'E/S aléatoire, coût d'E/S de séquence, etc. .
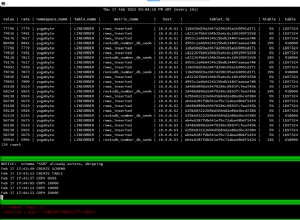
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEAinsi, dans cet exemple, un million d'enregistrements sont insérés, puis la table est analysée afin que toutes les statistiques soient à jour.
Analyse séquentielle
Comme son nom l'indique, une analyse séquentielle d'une table est effectuée en analysant séquentiellement tous les pointeurs d'éléments de toutes les pages des tables correspondantes. Donc, s'il y a 100 pages pour une table particulière et qu'il y a 1000 enregistrements dans chaque page, dans le cadre de l'analyse séquentielle, il récupérera 100*1000 enregistrements et vérifiera s'il correspond au niveau d'isolement et également à la clause de prédicat. Ainsi, même si un seul enregistrement est sélectionné dans le cadre de l'analyse complète de la table, il devra analyser 100 000 enregistrements pour trouver un enregistrement qualifié conformément à la condition.
Conformément au tableau et aux données ci-dessus, la requête suivante entraînera une analyse séquentielle car la majorité des données sont sélectionnées.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)REMARQUE
Bien que sans calculer et comparer le coût du plan, il est presque impossible de dire quel type d'analyse sera utilisé. Mais pour que l'analyse séquentielle soit utilisée, au moins les critères ci-dessous doivent correspondre :
- Aucun index disponible sur la clé, qui fait partie du prédicat.
- La majorité des lignes sont récupérées dans le cadre de la requête SQL.
CONSEILS
Dans le cas où seulement très peu de % de lignes sont récupérées et que le prédicat se trouve sur une (ou plusieurs) colonne, essayez d'évaluer les performances avec ou sans index.
Analyse d'index
Contrairement à l'analyse séquentielle, l'analyse d'index ne récupère pas tous les enregistrements de manière séquentielle. Il utilise plutôt une structure de données différente (selon le type d'index) correspondant à l'index impliqué dans la requête et localise la clause de données requises (selon le prédicat) avec des analyses très minimales. Ensuite, l'entrée trouvée à l'aide de l'analyse d'index pointe directement vers les données dans la zone de tas (comme indiqué dans la figure ci-dessus), qui sont ensuite extraites pour vérifier la visibilité selon le niveau d'isolement. Il y a donc deux étapes pour l'analyse de l'index :
- Récupérer des données à partir de la structure de données liée à l'index. Il renvoie le TID des données correspondantes dans le tas.
- Ensuite, la page de tas correspondante est directement accessible pour obtenir des données entières. Cette étape supplémentaire est requise pour les raisons ci-dessous :
- La requête peut avoir demandé de récupérer plus de colonnes que ce qui est disponible dans l'index correspondant.
- Les informations de visibilité ne sont pas conservées avec les données d'index. Ainsi, afin de vérifier la visibilité des données selon le niveau d'isolement, il doit accéder aux données du tas.
Maintenant, nous pouvons nous demander pourquoi ne pas toujours utiliser Index Scan s'il est si efficace. Donc, comme nous le savons, tout a un coût. Ici, le coût impliqué est lié au type d'E / S que nous effectuons. Dans le cas de l'analyse d'index, des E/S aléatoires sont impliquées car pour chaque enregistrement trouvé dans le stockage d'index, il doit extraire les données correspondantes du stockage HEAP, tandis qu'en cas d'analyse séquentielle, des E/S de séquence sont impliquées, ce qui ne prend qu'environ 25 % de la synchronisation des E/S aléatoires.
Ainsi, l'analyse d'index ne doit être choisie que si le gain global dépasse les frais généraux encourus en raison du coût d'E/S aléatoire.
Conformément au tableau et aux données ci-dessus, la requête suivante entraînera une analyse d'index car un seul enregistrement est sélectionné. Ainsi, les E/S aléatoires sont moindres et la recherche de l'enregistrement correspondant est rapide.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Analyse d'index uniquement
L'analyse de l'index uniquement est similaire à l'analyse de l'index, à l'exception de la deuxième étape, c'est-à-dire que, comme son nom l'indique, elle analyse uniquement la structure des données d'index. Il existe deux conditions préalables supplémentaires pour choisir l'analyse de l'index uniquement par rapport à l'analyse de l'index :
- La requête ne doit récupérer que les colonnes clés qui font partie de l'index.
- Tous les tuples (enregistrements) de la page de tas sélectionnée doivent être visibles. Comme indiqué dans la section précédente, la structure des données d'index ne conserve pas les informations de visibilité. Par conséquent, afin de sélectionner uniquement des données à partir de l'index, nous devons éviter de vérifier la visibilité, ce qui pourrait se produire si toutes les données de cette page sont considérées comme visibles.
La requête suivante entraînera une analyse d'index uniquement. Même si cette requête est presque similaire en termes de sélection du nombre d'enregistrements, mais comme seul le champ clé (c'est-à-dire "num") est sélectionné, elle choisira Index Only Scan.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Analyse Bitmap
Le scan bitmap est un mélange de scan d'index et de scan séquentiel. Il essaie de résoudre l'inconvénient de l'analyse d'index mais conserve tout son avantage. Comme indiqué ci-dessus pour chaque donnée trouvée dans la structure de données d'index, il doit trouver les données correspondantes dans la page de tas. Donc, alternativement, il doit récupérer la page d'index une fois, puis suivre la page de tas, ce qui provoque beaucoup d'E/S aléatoires. Ainsi, la méthode d'analyse bitmap tire parti des avantages de l'analyse d'index sans E/S aléatoires. Cela fonctionne à deux niveaux comme ci-dessous :
- Bitmap Index Scan :d'abord, il récupère toutes les données d'index à partir de la structure de données d'index et crée un bitmap de tous les TID. Pour une compréhension simple, vous pouvez considérer que ce bitmap contient un hachage de toutes les pages (haché basé sur le numéro de page) et chaque entrée de page contient un tableau de tous les décalages dans cette page.
- Analyse du tas bitmap :comme son nom l'indique, il lit le bitmap des pages, puis analyse les données du tas correspondant à la page stockée et au décalage. À la fin, il vérifie la visibilité et le prédicat, etc. et renvoie le tuple en fonction du résultat de toutes ces vérifications.
La requête ci-dessous entraînera une analyse Bitmap car elle ne sélectionne pas très peu d'enregistrements (c'est-à-dire trop pour l'analyse d'index) et en même temps ne sélectionne pas un grand nombre d'enregistrements (c'est-à-dire trop peu pour une analyse séquentielle scanner).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Considérez maintenant la requête ci-dessous, qui sélectionne le même nombre d'enregistrements mais uniquement les champs clés (c'est-à-dire uniquement les colonnes d'index). Puisqu'il ne sélectionne que la clé, il n'a pas besoin de référencer des pages de tas pour d'autres parties de données et, par conséquent, il n'y a pas d'E/S aléatoires impliquées. Cette requête choisira donc Index Only Scan au lieu de Bitmap Scan.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Analyse TID
TID, comme mentionné ci-dessus, est un nombre de 6 octets qui se compose d'un numéro de page de 4 octets et d'un index de tuple de 2 octets restants à l'intérieur de la page. L'analyse TID est un type d'analyse très spécifique dans PostgreSQL et n'est sélectionnée que s'il y a TID dans le prédicat de la requête. Considérez ci-dessous la requête démontrant le TID Scan :
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Ainsi, ici, dans le prédicat, au lieu de donner une valeur exacte de la colonne comme condition, TID est fourni. C'est quelque chose de similaire à la recherche basée sur ROWID dans Oracle.
Bonus
Toutes les méthodes d'analyse sont largement utilisées et célèbres. De plus, ces méthodes d'analyse sont disponibles dans presque toutes les bases de données relationnelles. Mais il existe une autre méthode d'analyse récemment en discussion dans la communauté PostgreSQL et également récemment ajoutée dans d'autres bases de données relationnelles. Il s'appelle "Loose IndexScan" dans MySQL, "Index Skip Scan" dans Oracle et "Jump Scan" dans DB2.
Cette méthode d'analyse est utilisée pour un scénario spécifique où une valeur distincte de la colonne clé principale de l'index B-Tree est sélectionnée. Dans le cadre de cette analyse, il évite de parcourir toutes les valeurs de colonne de clé égales plutôt que de parcourir la première valeur unique, puis de passer à la suivante.
Ce travail est toujours en cours dans PostgreSQL avec le nom provisoire "Index Skip Scan" et nous pouvons nous attendre à le voir dans une future version.