Présentation
Quelle que soit la technologie de base de données, il est nécessaire d'avoir une configuration de surveillance, à la fois pour détecter les problèmes et prendre des mesures, ou simplement pour connaître l'état actuel de nos systèmes.
A cet effet il existe plusieurs outils, payants et gratuits. Dans ce blog, nous nous concentrerons sur un en particulier :Nagios Core.
Qu'est-ce que Nagios Core ?
Nagios Core est un système Open Source pour la surveillance des hôtes, des réseaux et des services. Il permet de configurer des alertes et a différents états pour celles-ci. Il permet la mise en place de plugins, développés par la communauté, ou encore nous permet de paramétrer nos propres scripts de monitoring.
Comment installer Nagios ?
La documentation officielle nous montre comment installer Nagios Core sur les systèmes CentOS ou Ubuntu.
Voyons un exemple des étapes nécessaires à l'installation sur CentOS 7.
Forfaits requis
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipTéléchargez Nagios Core, les plugins Nagios et NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzAjouter un utilisateur et un groupe Nagios
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheInstallation de Nagios
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgInstallation du plug-in Nagios et NRPE
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginNous ajoutons la ligne suivante à la fin de notre fichier /usr/local/nagios/etc/objects/command.cfg pour utiliser NRPE lors de la vérification de nos serveurs :
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios démarre
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdAccès Web
Nous créons l'utilisateur pour accéder à l'interface Web et nous pouvons entrer dans le site.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://IP_Address/nagios/
 Accès Web Nagios
Accès Web Nagios Comment configurer Nagios ?
Maintenant que nous avons installé notre Nagios, nous pouvons continuer la configuration. Pour cela, nous devons nous rendre à l'emplacement correspondant à notre installation, dans notre exemple /usr/local/nagios/etc.
Il existe plusieurs fichiers de configuration différents que vous devrez créer ou modifier avant de commencer à surveiller quoi que ce soit.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg : Le fichier de configuration CGI contient un certain nombre de directives qui affectent le fonctionnement des CGI. Il contient également une référence au fichier de configuration principal, afin que les CGI sachent comment vous avez configuré Nagios et où sont stockées vos définitions d'objets.
- htpasswd.users : Ce fichier contient les utilisateurs créés pour accéder à l'interface Web de Nagios.
- nagios.cfg : Le fichier de configuration principal contient un certain nombre de directives qui affectent le fonctionnement du démon Nagios Core.
- objets : Lorsque vous installez Nagios, plusieurs exemples de fichiers de configuration d'objets sont placés ici. Vous pouvez utiliser ces exemples de fichiers pour voir comment fonctionne l'héritage d'objet et apprendre à définir vos propres définitions d'objet. Les objets sont tous les éléments impliqués dans la logique de surveillance et de notification.
- ressource.cfg : Ceci est utilisé pour spécifier un fichier de ressources facultatif qui peut contenir des définitions de macro. Les macros vous permettent de référencer les informations des hôtes, des services et d'autres sources dans vos commandes.
Dans les objets, nous pouvons trouver des modèles, qui peuvent être utilisés lors de la création de nouveaux objets. Par exemple, nous pouvons voir que dans notre fichier /usr/local/nagios/etc/objects/templates.cfg, il y a un template nommé linux-server, qui va servir à ajouter nos serveurs.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}En utilisant ce modèle, nos hébergeurs hériteront de la configuration sans avoir à les spécifier un par un sur chaque serveur que nous ajouterons.
Nous avons également des commandes, des contacts et des périodes prédéfinis.
Les commandes seront utilisées par Nagios pour ses vérifications, et c'est ce que nous ajoutons dans le fichier de configuration de chaque serveur pour le surveiller. Par exemple, PING :
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Nous avons la possibilité de créer des contacts ou des groupes, et de spécifier quelles alertes je souhaite joindre à quelle personne ou groupe.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}Pour nos contrôles et alertes, nous pouvons configurer à quelles heures et quels jours nous voulons les recevoir. Si nous avons un service qui n'est pas critique, nous ne voulons probablement pas nous réveiller à l'aube, il serait donc bon d'alerter uniquement pendant les heures de travail pour éviter cela.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Voyons maintenant comment ajouter des alertes à nos Nagios.
Nous allons surveiller nos serveurs PostgreSQL, nous les ajoutons donc d'abord en tant qu'hôtes dans notre répertoire d'objets. Nous allons créer 3 nouveaux fichiers :
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Ensuite, nous devons les ajouter au fichier nagios.cfg et ici nous avons 2 options.
Ajoutez nos hôtes (fichiers cfg) un par un en utilisant la variable cfg_file (option par défaut) ou ajoutez tous les fichiers cfg que nous avons dans un répertoire en utilisant la variable cfg_dir.
Nous ajouterons les fichiers un par un en suivant la stratégie par défaut.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgAvec cela, nous avons nos hôtes surveillés. Il ne nous reste plus qu'à ajouter les services que nous voulons surveiller. Pour cela, nous utiliserons certaines vérifications déjà définies (check_ssh et check_ping), et nous ajouterons quelques vérifications de base du système d'exploitation telles que la charge et l'espace disque, entre autres, en utilisant NRPE.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancQu'est-ce que le NRPE ?
Exécuteur de plug-in distant Nagios. Cet outil nous permet d'exécuter les plugins Nagios sur un hôte distant de la manière la plus transparente possible.
Pour l'utiliser, nous devons installer le serveur dans chaque nœud que nous voulons surveiller, et notre Nagios se connectera en tant que client à chacun d'eux, en exécutant le ou les plugins correspondants.
Comment installer NRPE ?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpePuis on édite le fichier de configuration /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>Et on redémarre le service NRPE :
[example@sqldat.com ~]# systemctl restart nrpeNous pouvons tester la connexion en exécutant ce qui suit depuis notre serveur Nagios :
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Comment surveiller PostgreSQL ?
Lors de la surveillance de PostgreSQL, il y a deux domaines principaux à prendre en compte :le système d'exploitation et les bases de données.
Pour le système d'exploitation, NRPE a configuré certaines vérifications de base telles que l'espace disque et la charge, entre autres. Ces vérifications peuvent être activées très facilement de la manière suivante.
Dans nos nœuds, nous éditons le fichier /usr/local/nagios/etc/nrpe.cfg et allons là où se trouvent les lignes suivantes :
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Les noms entre crochets sont ceux que nous utiliserons dans notre serveur Nagios pour activer ces vérifications.
Dans notre Nagios, nous éditons les fichiers des 3 nœuds :
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgNous ajoutons ces vérifications que nous avons vues précédemment, laissant nos fichiers comme suit :
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}Et on redémarre le service nagios :
[example@sqldat.com ~]# systemctl start nagiosÀ ce stade, si nous allons dans la section des services de l'interface Web de notre Nagios, nous devrions avoir quelque chose comme ceci :
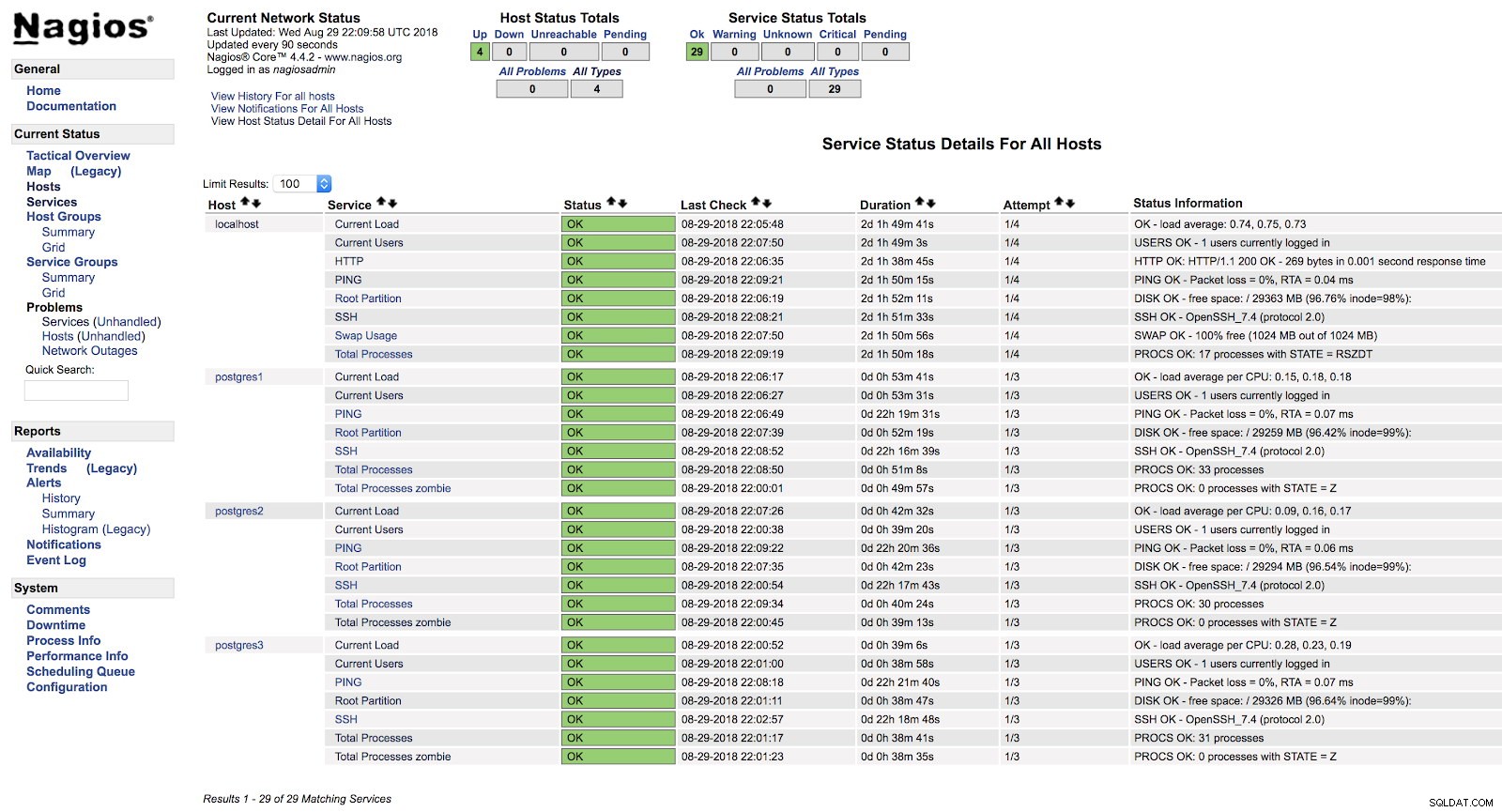 Alertes de l'hôte Nagios
Alertes de l'hôte Nagios De cette façon, nous couvrirons les vérifications de base de notre serveur au niveau du système d'exploitation.
Nous avons beaucoup plus de chèques que nous pouvons ajouter et nous pouvons même créer nos propres chèques (nous verrons un exemple plus tard).
Voyons maintenant comment surveiller notre moteur de base de données PostgreSQL à l'aide de deux des principaux plugins conçus pour cette tâche.
Check_postgres
L'un des plugins les plus populaires pour vérifier PostgreSQL est check_postgres de Bucardo.
Voyons comment l'installer et comment l'utiliser avec notre base de données PostgreSQL.
Forfaits requis
[example@sqldat.com ~]# yum install perl-develInstallation
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksCette dernière commande crée les liens pour utiliser toutes les fonctions de cette vérification, telles que check_postgres_connection, check_postgres_last_vacuum ou check_postgres_replication_slots entre autres.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Nous ajoutons dans notre fichier de configuration NRPE (/usr/local/nagios/etc/nrpe.cfg) la ligne pour exécuter le contrôle que nous voulons utiliser :
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100Dans notre exemple, nous avons ajouté 4 vérifications de base pour PostgreSQL. Nous surveillerons les verrous, les ballonnements, la connexion et les backends.
Dans le fichier correspondant à notre base de données sur le serveur Nagios (/usr/local/nagios/etc/objects/postgres1.cfg), nous ajoutons les entrées suivantes :
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}Et après avoir redémarré les deux services (NRPE et Nagios) sur les deux serveurs, nous pouvons voir nos alertes configurées.
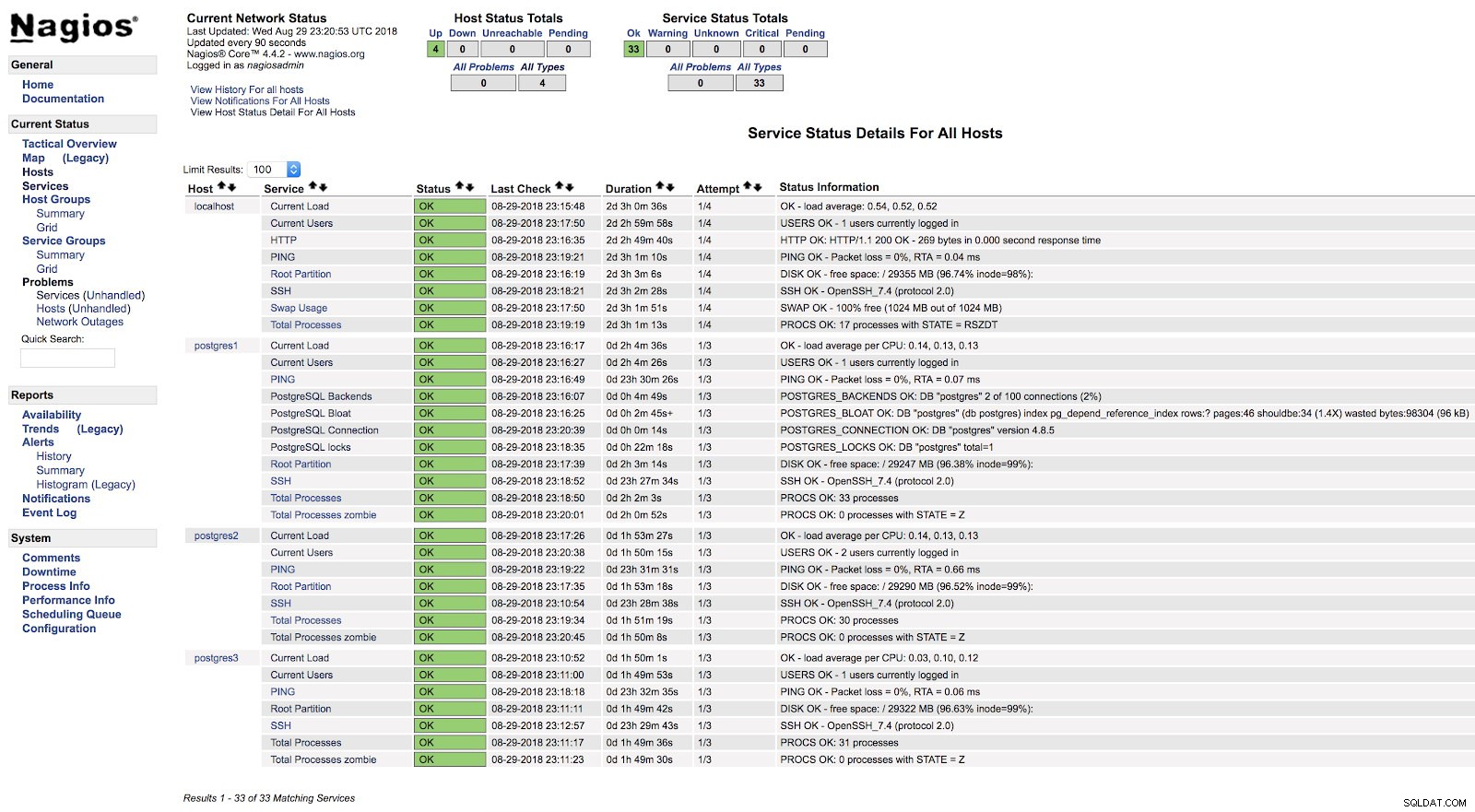 Nagios check_postgres Alertes
Nagios check_postgres Alertes Dans la documentation officielle du plugin check_postgres, vous pouvez trouver des informations sur les autres éléments à surveiller et comment le faire.
Vérifier_pgactivité
C'est maintenant au tour de check_pgactivity, également populaire pour surveiller notre base de données PostgreSQL.
Installation
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityNous ajoutons dans notre fichier de configuration NRPE (/usr/local/nagios/etc/nrpe.cfg) la ligne pour exécuter le contrôle que nous voulons utiliser :
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10Dans notre exemple, nous ajouterons 4 vérifications de base pour PostgreSQL. Nous surveillerons les backends, la connexion, les index invalides et les verrous.
Dans le fichier correspondant à notre base de données sur le serveur Nagios (/usr/local/nagios/etc/objects/postgres2.cfg), nous ajoutons les entrées suivantes :
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}Et après avoir redémarré les deux services (NRPE et Nagios) sur les deux serveurs, nous pouvons voir nos alertes configurées.
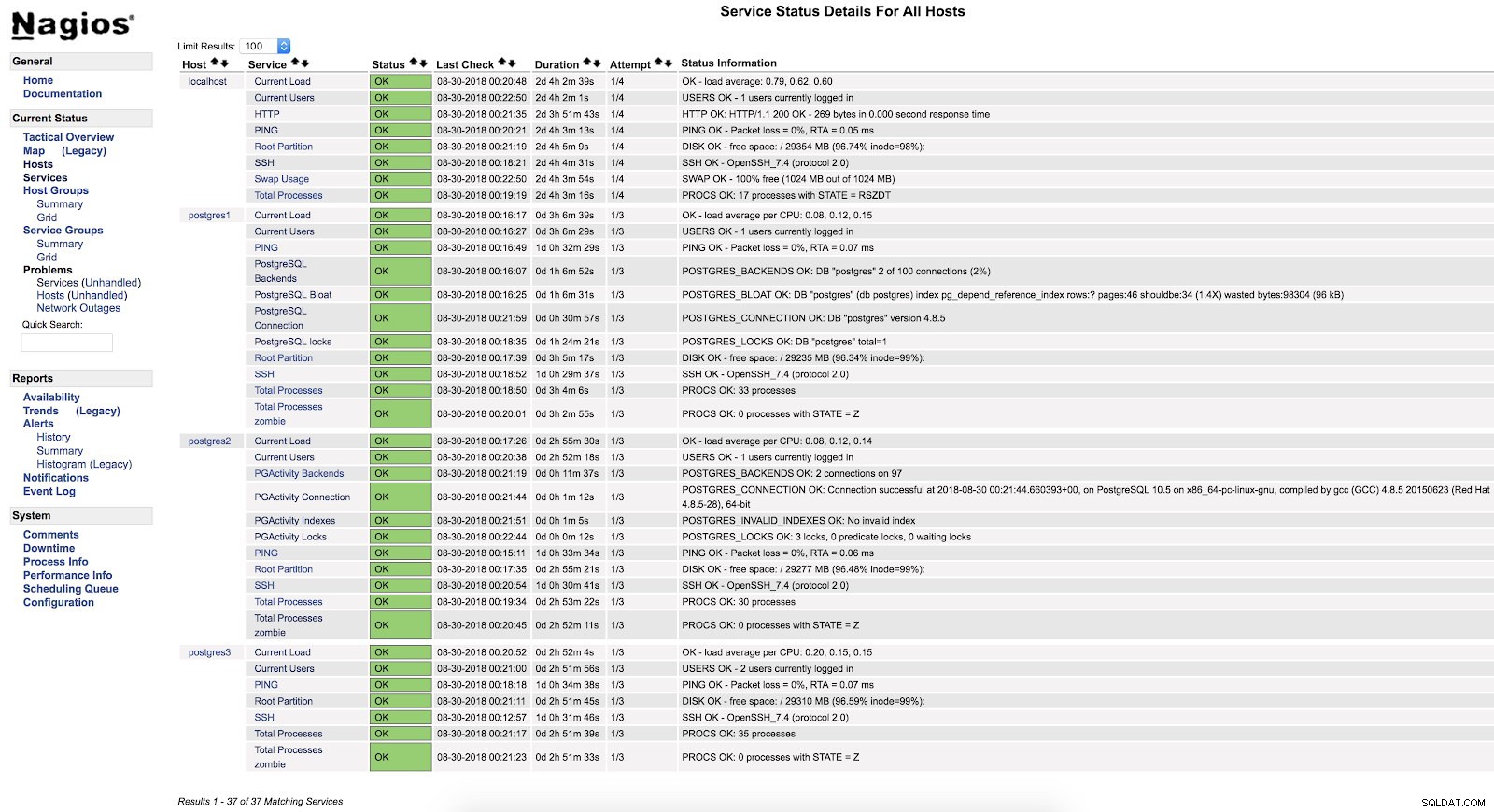 Alertes Nagios check_pgactivity
Alertes Nagios check_pgactivity Vérifier le journal des erreurs
L'une des vérifications les plus importantes, ou la plus importante, consiste à consulter notre journal des erreurs.
Ici, nous pouvons trouver différents types d'erreurs telles que FATAL ou deadlock, et c'est un bon point de départ pour analyser tout problème que nous avons dans notre base de données.
Pour vérifier notre journal d'erreurs, nous allons créer notre propre script de surveillance et l'intégrer dans notre Nagios (ce n'est qu'un exemple, ce script sera basique et a beaucoup de place pour l'amélioration).
Script
Nous allons créer le fichier /usr/local/nagios/libexec/check_postgres_log.sh sur notre serveur PostgreSQL3.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiL'important du script est de créer correctement les sorties correspondant à chaque état. Ces sorties sont lues par Nagios et chaque numéro correspond à un état :
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNDans notre exemple, nous n'utiliserons que 2 états, OK et CRITICAL, puisque nous sommes uniquement intéressés à savoir s'il y a des erreurs de type FATAL dans notre journal des erreurs à l'heure actuelle.
Le texte que nous utilisons avant notre sortie sera affiché par l'interface Web de notre Nagios, il doit donc être aussi clair que possible pour l'utiliser comme guide du problème.
Une fois que nous aurons terminé notre script de monitoring, nous allons procéder à lui donner les permissions d'exécution, l'attribuer à l'utilisateur nagios et l'ajouter à notre serveur de base de données NRPE ainsi qu'à notre Nagios :
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Redémarrez NRPE et Nagios. Ensuite, nous pouvons voir notre vérification dans l'interface de Nagios :
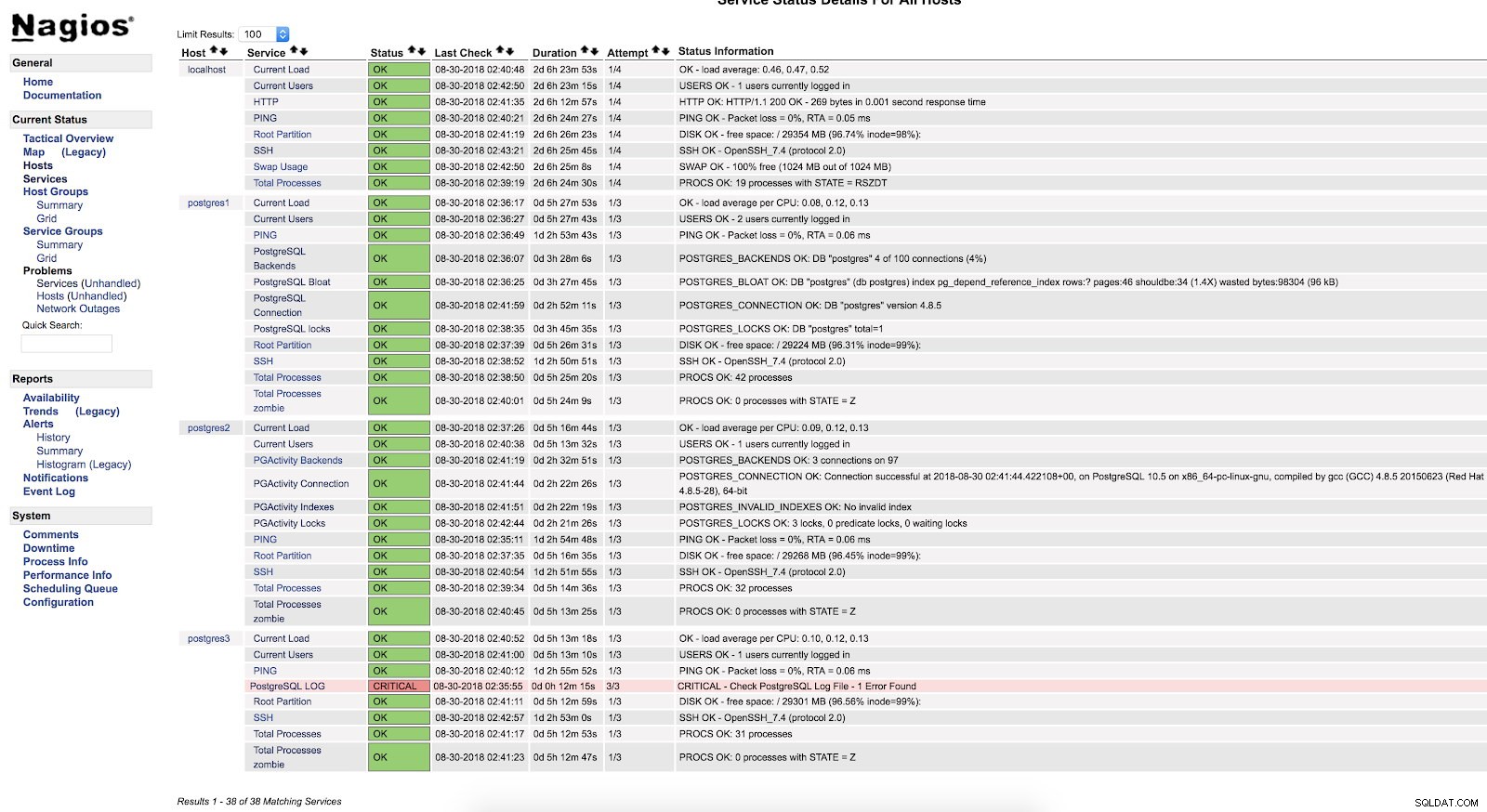 Alertes de script Nagios
Alertes de script Nagios Comme nous pouvons le voir, il est dans un état CRITIQUE, donc si nous allons dans le journal, nous pouvons voir ce qui suit :
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Pour plus d'informations sur ce que nous pouvons surveiller dans notre base de données PostgreSQL, je vous recommande de consulter nos blogs sur les performances et la surveillance ou ce webinaire sur les performances de PostgreSQL.
Sécurité et performances
Lors de la configuration de toute surveillance, que ce soit en utilisant des plugins ou notre propre script, nous devons être très prudents avec 2 choses très importantes - la sécurité et les performances.
Lorsque nous attribuons les autorisations nécessaires à la surveillance, nous devons être aussi restrictifs que possible, en limitant l'accès uniquement localement ou depuis notre serveur de surveillance, en utilisant des clés sécurisées, en cryptant le trafic, en permettant la connexion au minimum nécessaire pour que la surveillance fonctionne.
En ce qui concerne les performances, la surveillance est nécessaire, mais il est également nécessaire de l'utiliser en toute sécurité pour nos systèmes.
Nous devons faire attention à ne pas générer d'accès disque excessivement élevés ou exécuter des requêtes qui affectent négativement les performances de notre base de données.
Si nous avons de nombreuses transactions par seconde générant des gigaoctets de journaux et que nous continuons à rechercher des erreurs en permanence, ce n'est probablement pas le meilleur pour notre base de données. Nous devons donc maintenir un équilibre entre ce que nous surveillons, la fréquence et l'impact sur les performances.
Conclusion
Il existe plusieurs façons d'implémenter la surveillance ou de la configurer. Nous pouvons arriver à le faire aussi complexe ou aussi simple que nous le voulons. L'objectif de ce blog était de vous initier au monitoring de PostgreSQL à l'aide d'un des outils open source les plus utilisés. Nous avons également vu que la configuration est très flexible et peut être adaptée à différents besoins.
Et n'oubliez pas que nous pouvons toujours compter sur la communauté, alors je laisse quelques liens qui pourraient être d'une grande aide.
Forum d'assistance :https://support.nagios.com/forum/
Problèmes connus :https://github.com/NagiosEnterprises/nagioscore/issues
Plugins Nagios :https://exchange.nagios.org/directory/Plugins
Plugin Nagios pour ClusterControl :https://severalnines.com/blog/nagios-plugin-clustercontrol