Il s'agit de la deuxième partie de la série multi-série Solutions infonuagiques gérées pour l'analyse comparative de PostgreSQL . Dans la partie 1, j'ai présenté un aperçu des outils disponibles, j'ai expliqué la raison de l'utilisation de la procédure AWS Benchmark pour Aurora, ainsi que les versions de PostgreSQL à utiliser, et j'ai passé en revue Amazon Aurora PostgreSQL 10.6.
Dans cette partie, pgbench et sysbench seront exécutés sur Amazon RDS pour PostgreSQL 11.1. Au moment d'écrire ces lignes, la dernière version de PostgreSQL est la 11.2 publiée il y a environ un mois.
Cela vaut la peine de s'arrêter une seconde pour passer rapidement en revue les versions de PostgreSQL actuellement disponibles dans le cloud :
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS pour PostgreSQL 11.1
- Google Cloud SQL pour PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
Amazon est à nouveau gagnant, avec son offre RDS, en fournissant la version la plus récente de PostgreSQL. Comme annoncé sur le forum RDS, AWS a rendu PostgreSQL 11.1 disponible le 13 mars, soit quatre mois après la sortie de la communauté.
Configuration de l'environnement
Quelques notes sur les contraintes liées à la mise en place de l'environnement et à l'exécution du benchmark, points qui ont été abordés plus en détail lors de la partie 1 de cette série :
- Aucune modification des paramètres GUC par défaut du fournisseur de cloud.
- Les connexions sont limitées à un maximum de 1 000 car le correctif AWS pour pgbench ne s'est pas appliqué proprement. Sur une note connexe, j'ai dû télécharger le correctif de synchronisation AWS à partir de cette soumission pgsql-hackers car il n'était plus disponible sur le lien mentionné dans le guide.
- La mise en réseau améliorée doit être activée pour l'instance client.
- La base de données n'inclut pas de réplica.
- Le stockage de la base de données n'est pas chiffré.
- Les instances client et cible se trouvent dans la même zone de disponibilité.
Tout d'abord, configurez le client et les instances de base de données :
- Le client est une instance EC2 r4.8xlarge à la demande :
- vCPU :32 (16 cœurs x 2 threads/cœur)
- RAM :244 Gio
- Stockage :EBS optimisé
- Réseau :10 Gigabits
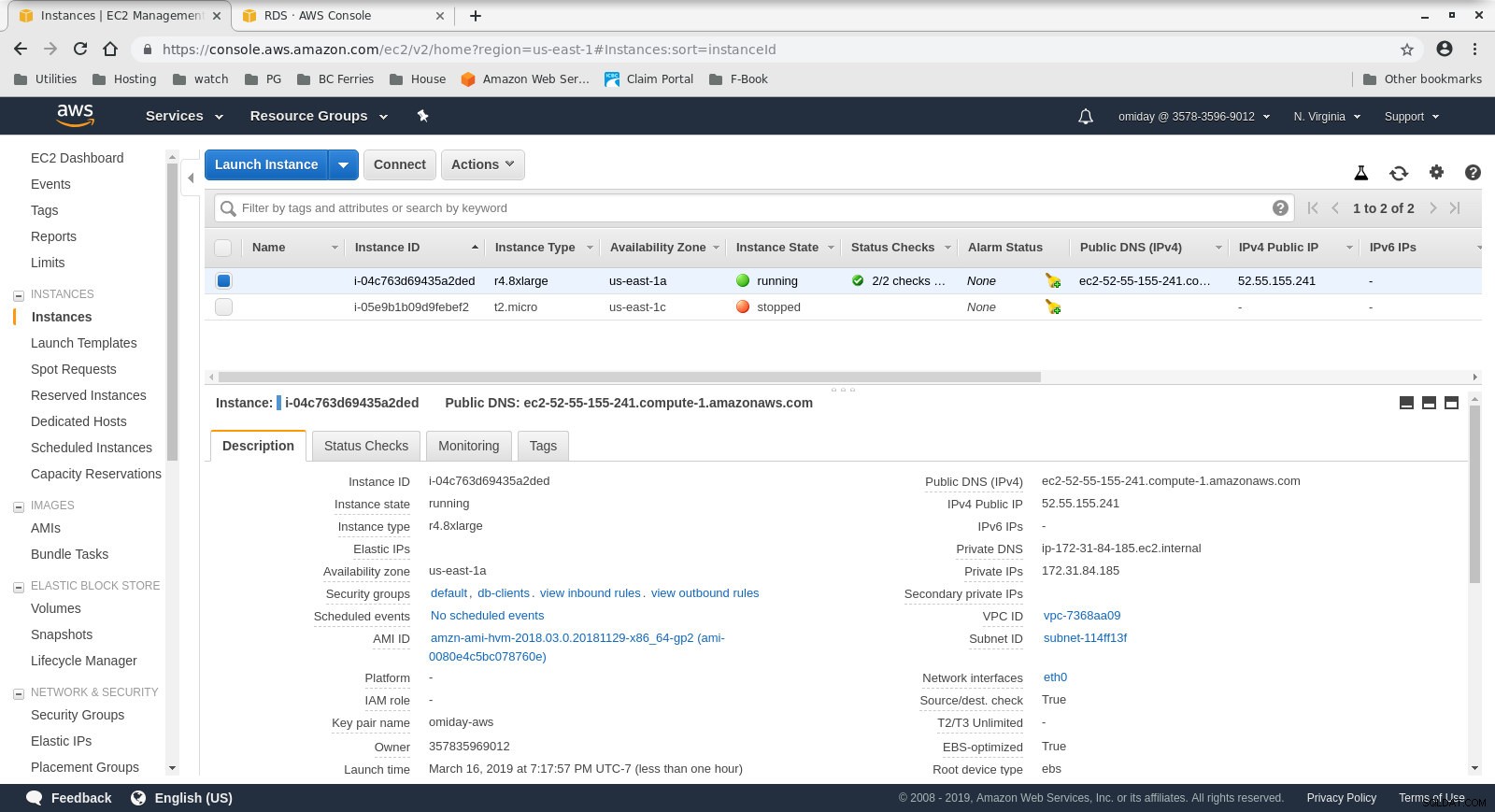 Configuration des instances clientes
Configuration des instances clientes - Le cluster de bases de données est un db.r4.2xlarge à la demande :
- processeur virtuel :8
- RAM :61 Gio
- Stockage :EBS optimisé
- Réseau :1 750 Mbit/s de bande passante maximale sur une connexion jusqu'à 10 Gbit/s
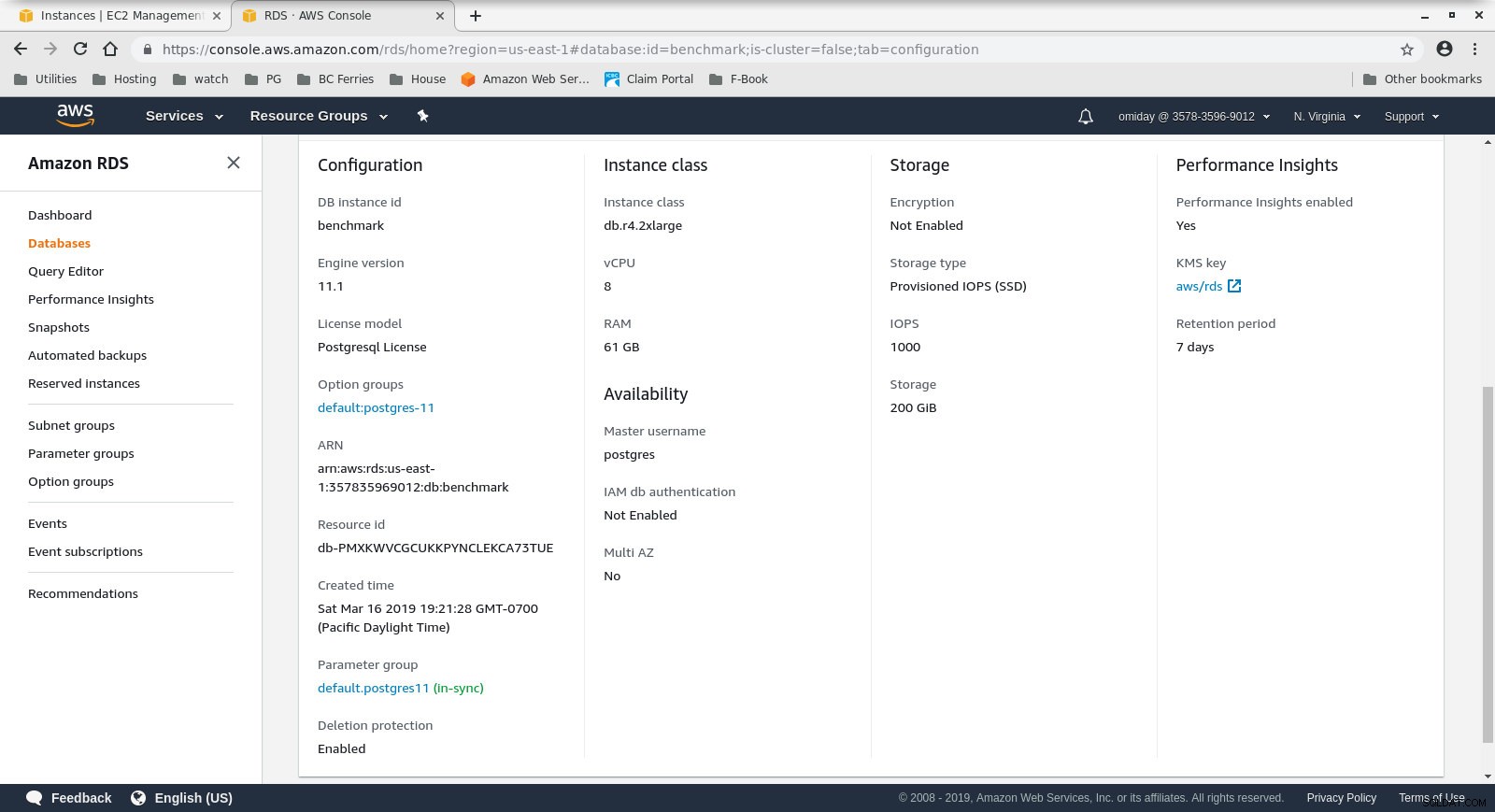 Configuration de l'instance de base de données
Configuration de l'instance de base de données
Ensuite, installez et configurez les outils de benchmark, pgbench et sysbench, en suivant les instructions du guide Amazon.
La dernière étape pour préparer l'environnement consiste à configurer les paramètres de connexion PostgreSQL. Une façon de le faire est d'initialiser les variables d'environnement dans .bashrc. De plus, nous devons définir les chemins vers les binaires et les bibliothèques PostgreSQL :
exporter PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
Verify that everything is in place:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 11.1
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 11.1
[example@sqldat.com ~]# sysbench --version
sysbench 0.5Exécution des benchmarks
pgench
Tout d'abord, initialisez la base de données pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000Le processus d'initialisation prend un certain temps et, lors de son exécution, génère le résultat suivant :
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data...
100000 of 1000000000 tuples (0%) done (elapsed 0.06 s, remaining 599.79 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.15 s, remaining 739.16 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.22 s, remaining 742.21 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 814.64 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.41 s, remaining 825.82 s)
600000 of 1000000000 tuples (0%) done (elapsed 0.51 s, remaining 854.13 s)
700000 of 1000000000 tuples (0%) done (elapsed 0.66 s, remaining 937.01 s)
800000 of 1000000000 tuples (0%) done (elapsed 1.52 s, remaining 1897.42 s)
900000 of 1000000000 tuples (0%) done (elapsed 1.66 s, remaining 1840.08 s)
...
500600000 of 1000000000 tuples (50%) done (elapsed 814.78 s, remaining 812.83 s)
500700000 of 1000000000 tuples (50%) done (elapsed 814.81 s, remaining 812.53 s)
500800000 of 1000000000 tuples (50%) done (elapsed 814.83 s, remaining 812.23 s)
500900000 of 1000000000 tuples (50%) done (elapsed 815.11 s, remaining 812.19 s)
501000000 of 1000000000 tuples (50%) done (elapsed 815.20 s, remaining 811.94 s)
...
999200000 of 1000000000 tuples (99%) done (elapsed 1645.02 s, remaining 1.32 s)
999300000 of 1000000000 tuples (99%) done (elapsed 1645.17 s, remaining 1.15 s)
999400000 of 1000000000 tuples (99%) done (elapsed 1645.20 s, remaining 0.99 s)
999500000 of 1000000000 tuples (99%) done (elapsed 1645.23 s, remaining 0.82 s)
999600000 of 1000000000 tuples (99%) done (elapsed 1645.26 s, remaining 0.66 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1645.28 s, remaining 0.49 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1645.51 s, remaining 0.33 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1645.77 s, remaining 0.16 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1646.03 s, remaining 0.00 s)
vacuuming...
creating primary keys...
total time: 5538.86 s (drop 0.00 s, tables 0.01 s, insert 1647.08 s, commit 0.03 s, primary 1251.60 s, foreign 0.00 s, vacuum 2640.14 s)
done.Une fois cette partie terminée, vérifiez que la base de données PostgreSQL a été remplie. La version simplifiée suivante de la requête d'utilisation du disque peut être utilisée pour renvoyer la taille de la base de données PostgreSQL :
SELECT
d.datname AS Name,
pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
FROM pg_catalog.pg_database d
WHERE d.datname = 'postgres';…et le résultat :
name | owner | size
----------+----------+--------
postgres | postgres | 160 GB
(1 row)Une fois toutes les préparations terminées, nous pouvons commencer le test de lecture/écriture de pgbench :
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048Après 10 minutes, nous obtenons les résultats :
starting vacuum...end.
progress: 60.0 s, 878.3 tps, lat 1101.258 ms stddev 339.491
progress: 120.0 s, 885.2 tps, lat 1132.301 ms stddev 292.551
progress: 180.0 s, 656.3 tps, lat 1522.102 ms stddev 666.017
progress: 240.0 s, 436.8 tps, lat 2277.140 ms stddev 524.603
progress: 300.0 s, 742.2 tps, lat 1363.558 ms stddev 578.541
progress: 360.0 s, 866.4 tps, lat 1146.972 ms stddev 301.861
progress: 420.0 s, 878.2 tps, lat 1143.939 ms stddev 304.396
progress: 480.0 s, 872.7 tps, lat 1139.892 ms stddev 304.421
progress: 540.0 s, 881.0 tps, lat 1132.373 ms stddev 311.890
progress: 600.0 s, 729.3 tps, lat 1366.517 ms stddev 867.784
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 470582
latency average = 1274.340 ms
latency stddev = 544.179 ms
tps = 782.084354 (including connections establishing)
tps = 783.610726 (excluding connections establishing)sysbench
La première étape consiste à ajouter des données :
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareLa commande crée 250 tables, chaque table ayant 2 index :
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Regardons les index :
postgres=> \di
List of relations
Schema | Name | Type | Owner | Table
--------+-----------------------+-------+----------+------------------
public | k_1 | index | postgres | sbtest1
public | k_10 | index | postgres | sbtest10
public | k_100 | index | postgres | sbtest100
public | k_101 | index | postgres | sbtest101
public | k_102 | index | postgres | sbtest102
public | k_103 | index | postgres | sbtest103
...
public | k_97 | index | postgres | sbtest97
public | k_98 | index | postgres | sbtest98
public | k_99 | index | postgres | sbtest99
public | pgbench_accounts_pkey | index | postgres | pgbench_accounts
public | pgbench_branches_pkey | index | postgres | pgbench_branches
public | pgbench_tellers_pkey | index | postgres | pgbench_tellers
public | sbtest100_pkey | index | postgres | sbtest100
public | sbtest101_pkey | index | postgres | sbtest101
public | sbtest102_pkey | index | postgres | sbtest102
public | sbtest103_pkey | index | postgres | sbtest103
public | sbtest104_pkey | index | postgres | sbtest104
public | sbtest105_pkey | index | postgres | sbtest105
...
public | sbtest97_pkey | index | postgres | sbtest97
public | sbtest98_pkey | index | postgres | sbtest98
public | sbtest99_pkey | index | postgres | sbtest99
public | sbtest9_pkey | index | postgres | sbtest9
(503 rows)Ça a l'air bien... pour commencer le test, lancez simplement :
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runUne note d'avertissement :
Le stockage RDS n'est pas "élastique", ce qui signifie que l'espace de stockage alloué lors de la création de l'instance doit être suffisamment grand pour contenir la quantité de données générées lors du benchmark, sinon RDS échouera avec :
FATAL: PQexec() failed: 7 PANIC: could not write to file "pg_wal/xlogtemp.29144": No space left on device
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: COMMIT
FATAL: failed to execute function `event': 3
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
WARNING: terminating connection because of crash of another server processLa taille de stockage peut être augmentée sans arrêter la base de données, cependant, il m'a fallu environ 30 minutes pour la faire passer de 200 Gio à 500 Gio :
 Augmentation de l'espace de stockage sur RDS
Augmentation de l'espace de stockage sur RDS Et voici les résultats des tests sysbench :
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1070.40, reads: 0.00, writes: 4309.35, response time: 1808.81ms (95%), errors: 0.02, reconnects: 0.00
[ 120s] threads: 1000, tps: 889.68, reads: 0.00, writes: 3575.35, response time: 1951.12ms (95%), errors: 0.02, reconnects: 0.00
[ 180s] threads: 1000, tps: 574.57, reads: 0.00, writes: 2320.62, response time: 3936.73ms (95%), errors: 0.00, reconnects: 0.00
[ 240s] threads: 1000, tps: 232.10, reads: 0.00, writes: 928.43, response time: 10994.37ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 242.40, reads: 0.00, writes: 969.60, response time: 9412.39ms (95%), errors: 0.00, reconnects: 0.00
[ 360s] threads: 1000, tps: 257.73, reads: 0.00, writes: 1030.98, response time: 8833.64ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 264.65, reads: 0.00, writes: 1036.60, response time: 9192.42ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 278.07, reads: 0.00, writes: 1134.27, response time: 7133.76ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 250.40, reads: 0.00, writes: 1001.53, response time: 9628.97ms (95%), errors: 0.00, reconnects: 0.00
[ 600s] threads: 1000, tps: 249.97, reads: 0.00, writes: 996.92, response time: 10724.58ms (95%), errors: 0.00, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 1038401
other: 519199
total: 1557600
transactions: 259598 (428.59 per sec.)
read/write requests: 1038401 (1714.36 per sec.)
other operations: 519199 (857.18 per sec.)
ignored errors: 3 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 605.7086s
total number of events: 259598
total time taken by event execution: 602999.7582s
response time:
min: 55.02ms
avg: 2322.82ms
max: 13133.36ms
approx. 95 percentile: 8400.39ms
Threads fairness:
events (avg/stddev): 259.5980/3.20
execution time (avg/stddev): 602.9998/2.77Métriques de référence
Les métriques peuvent être capturées à l'aide des outils de surveillance AWS CloudWatch et Performance Insights. Voici quelques exemples pour les curieux :
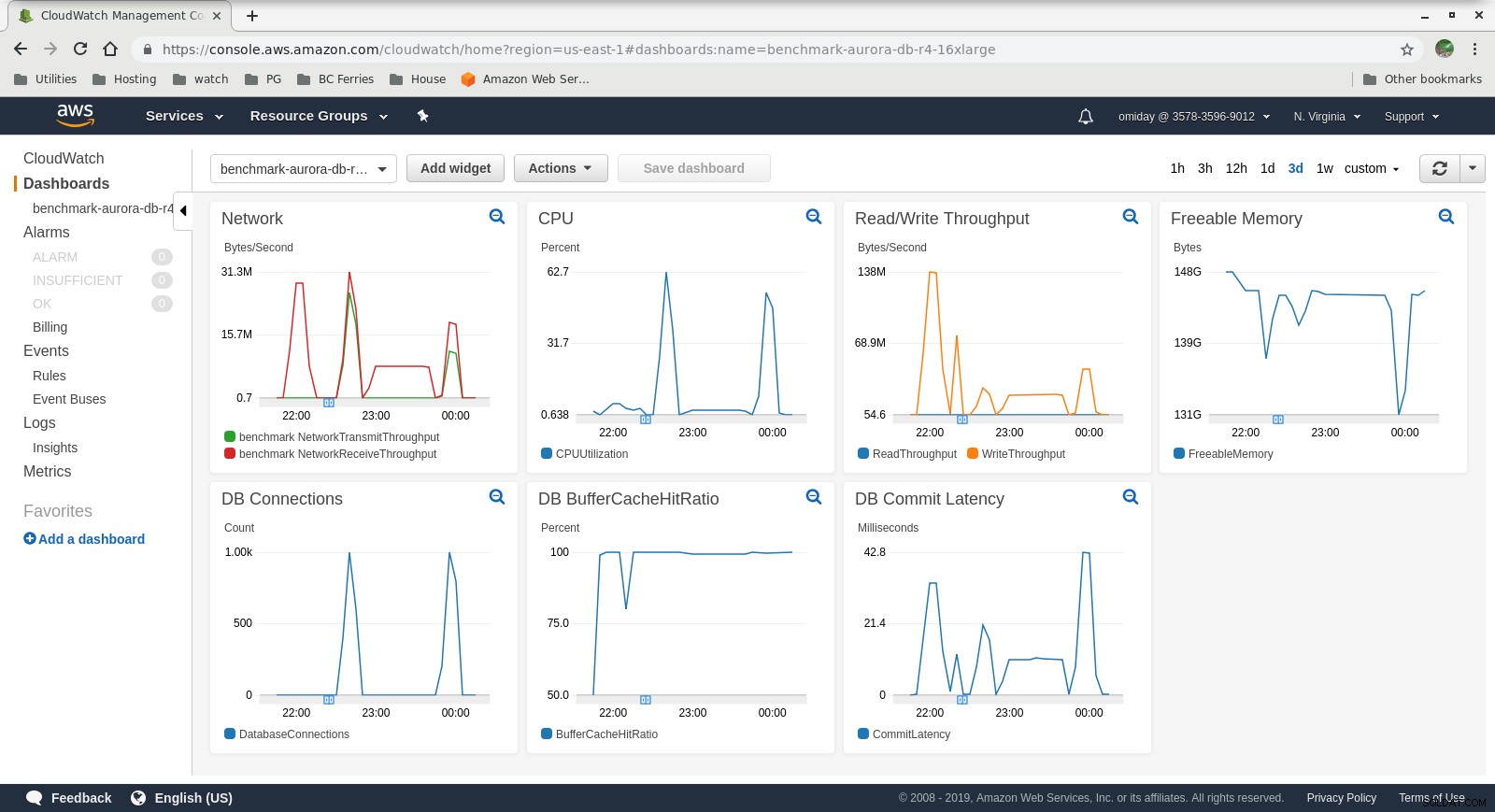 Métriques CloudWatch de l'instance de base de données
Métriques CloudWatch de l'instance de base de données 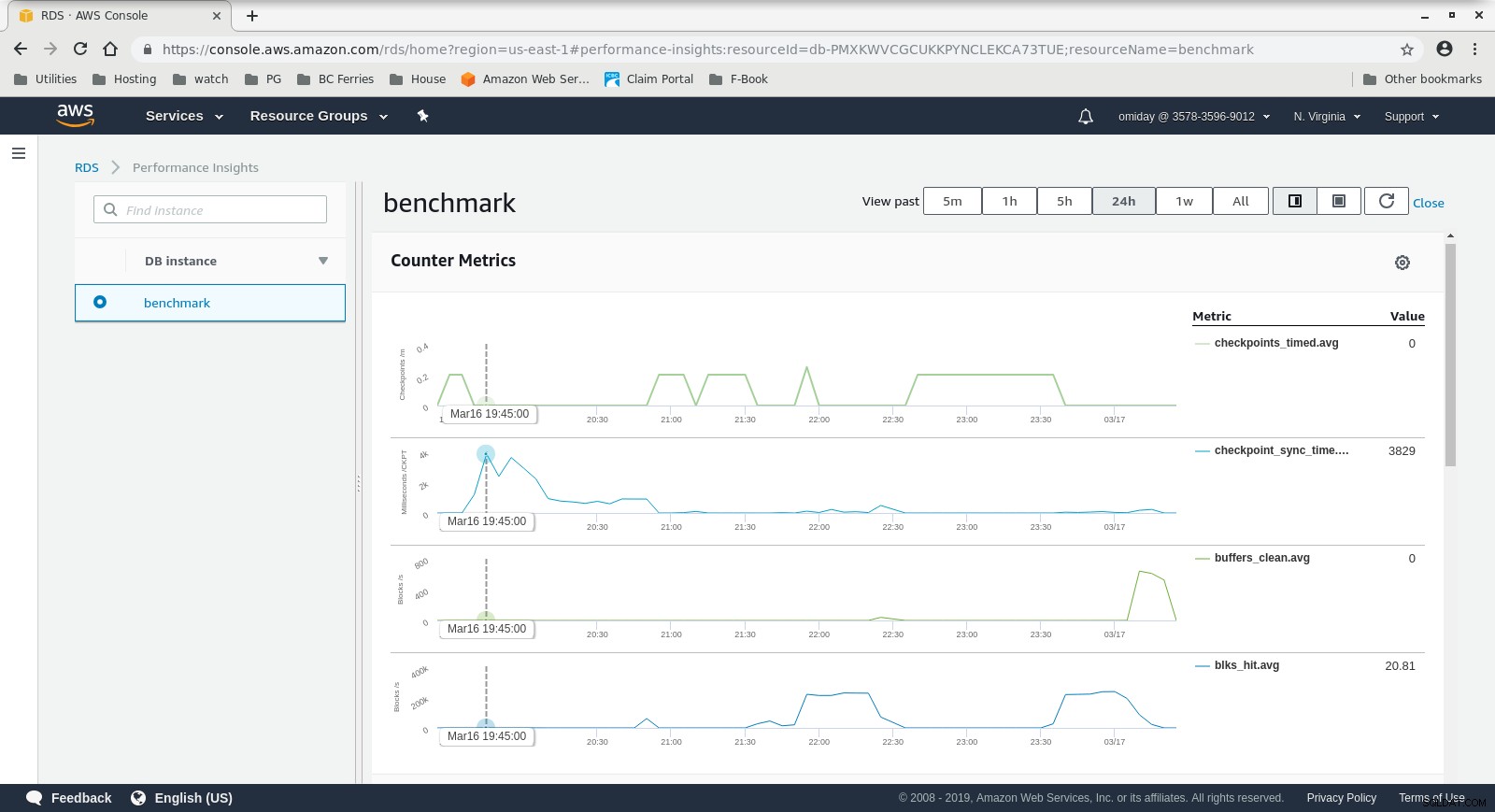 Informations sur les performances RDS - Mesures de compteur
Informations sur les performances RDS - Mesures de compteur 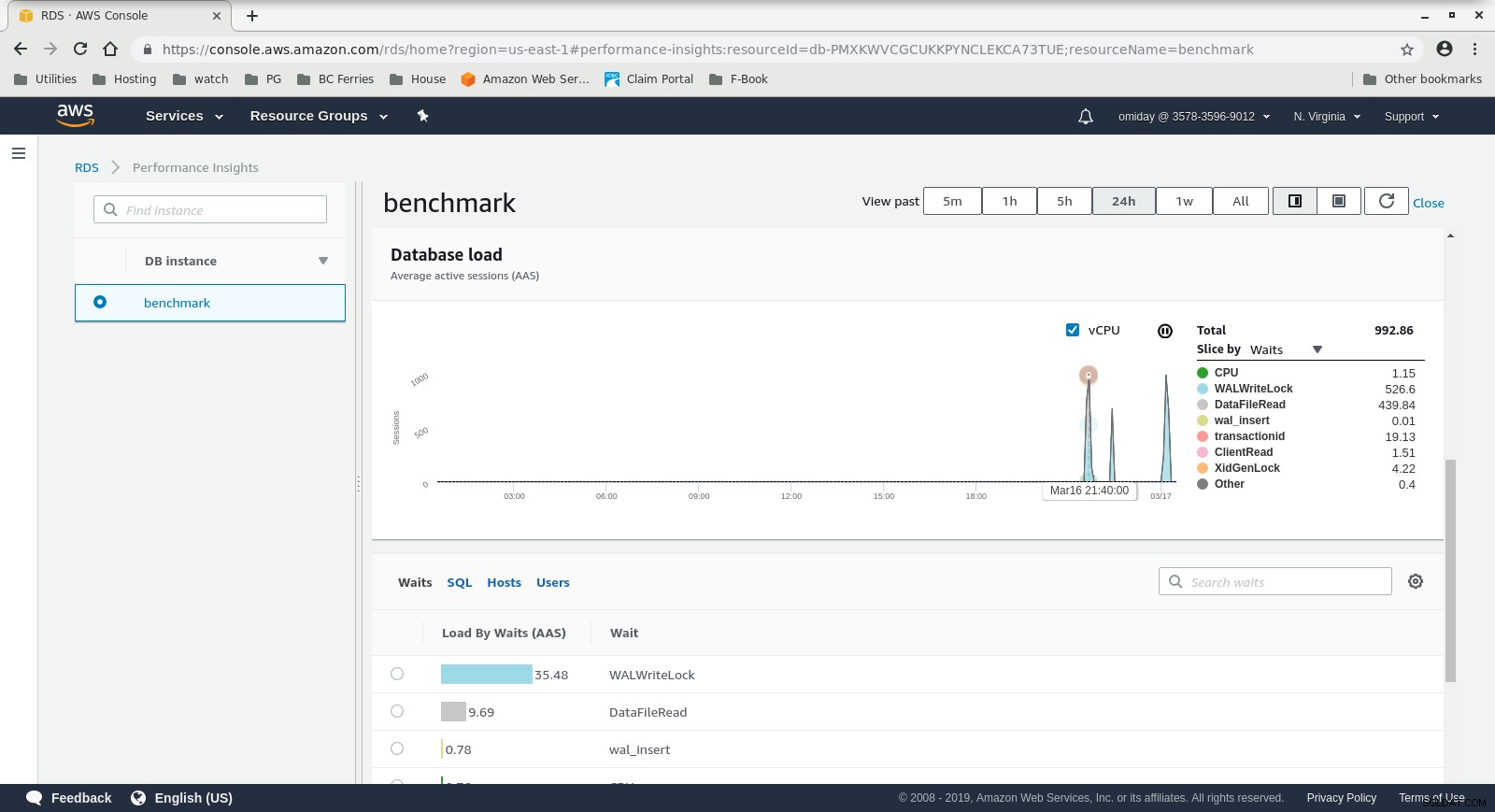 Informations sur les performances RDS - Chargement de la base de données
Informations sur les performances RDS - Chargement de la base de données Résultats
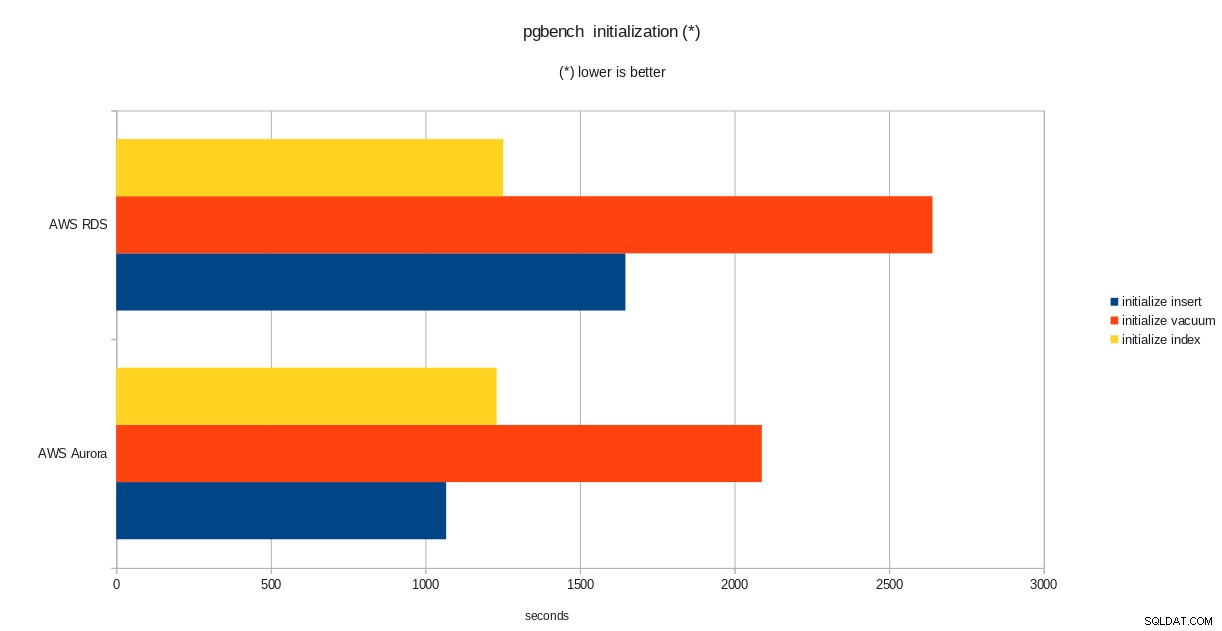 résultats de l'initialisation de pgbench
résultats de l'initialisation de pgbench 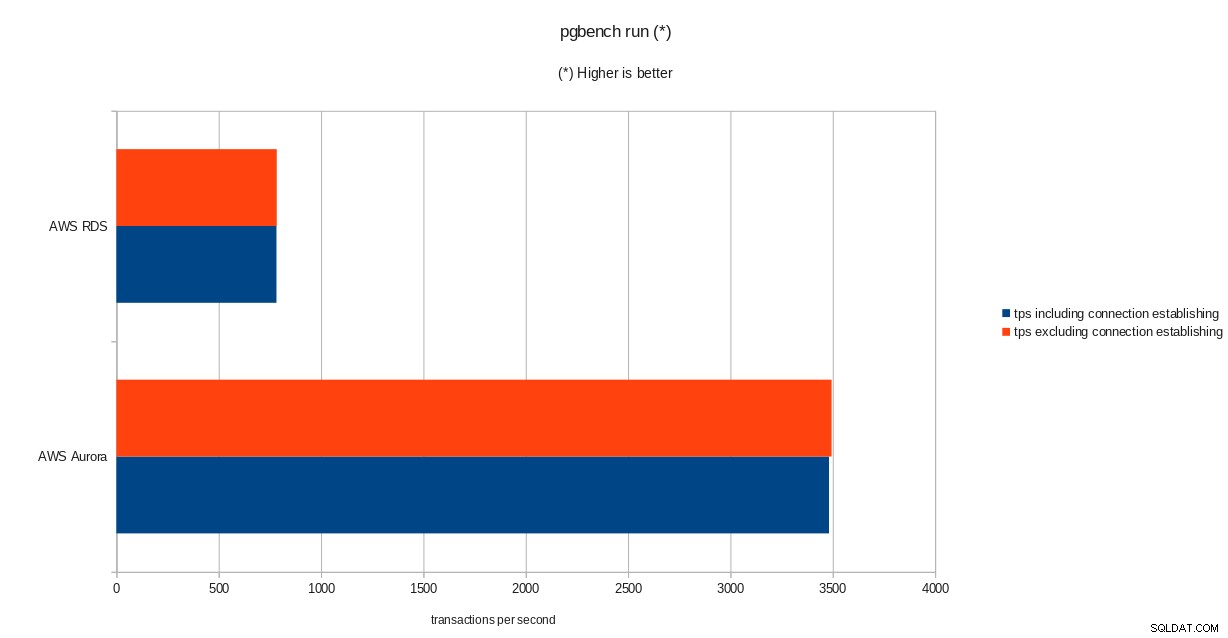 résultats de l'exécution de pgbench
résultats de l'exécution de pgbench 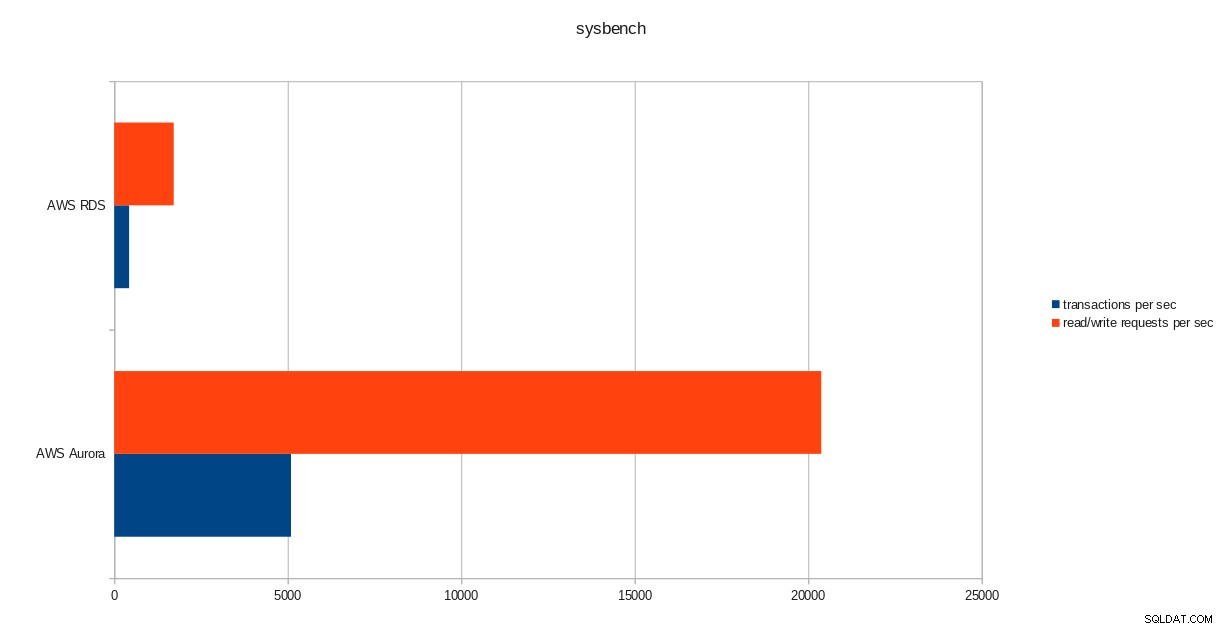 résultats de sysbench
résultats de sysbench Conclusion
Malgré l'exécution de la version 10.6 de PostgreSQL, Amazon Aurora surpasse clairement RDS qui est à la version 11.1, et cela n'est pas une surprise. Selon les FAQ d'Aurora, Amazon s'est donné beaucoup de mal pour améliorer les performances globales de la base de données qui a été construite sur un moteur de stockage repensé.
Suivant de la série
La partie suivante portera sur Google Cloud SQL pour PostgreSQL.