Avec Disaster Recovery, nous visons à mettre en place des systèmes pour gérer tout ce qui pourrait mal tourner avec notre base de données. Que se passe-t-il si la base de données plante ? Que se passe-t-il si un développeur tronque accidentellement un tableau ? Que se passe-t-il si nous découvrons que certaines données ont été supprimées la semaine dernière mais que nous ne l'avons pas remarqué avant aujourd'hui ? Ces choses arrivent, et la mise en place d'un plan et d'un système solides fera passer le DBA pour un héros alors que le cœur de tous les autres s'est déjà arrêté lorsqu'une catastrophe pointe le bout de son nez.
Toute base de données ayant une valeur quelconque doit pouvoir implémenter une ou plusieurs options de récupération après sinistre. PostgreSQL intègre un système de réplication très solide et est suffisamment flexible pour être configuré dans de nombreuses configurations afin de faciliter la reprise après sinistre, en cas de problème. Nous nous concentrerons sur des scénarios tels que ceux évoqués ci-dessus, sur la configuration de nos options de reprise après sinistre et sur les avantages de chaque solution.
Haute disponibilité
Avec la réplication en continu dans PostgreSQL, la haute disponibilité est simple à configurer et à entretenir. L'objectif est de fournir un site de basculement qui peut être promu maître si la base de données principale tombe en panne pour une raison quelconque, telle qu'une panne matérielle, une panne logicielle ou même une panne de réseau. Héberger une réplique sur un autre hôte, c'est bien, mais l'héberger dans un autre centre de données, c'est encore mieux.
Pour plus de détails sur la configuration de la réplication en continu, Manynines propose une analyse approfondie détaillée disponible ici. La documentation officielle de PostgreSQL Streaming Replication contient des informations détaillées sur le protocole de réplication en continu et son fonctionnement.
Une configuration standard ressemblera à ceci, une base de données maître acceptant les connexions en lecture/écriture, avec une base de données répliquée recevant toutes les activités WAL en temps quasi réel, rejouant toutes les activités de changement de données localement.
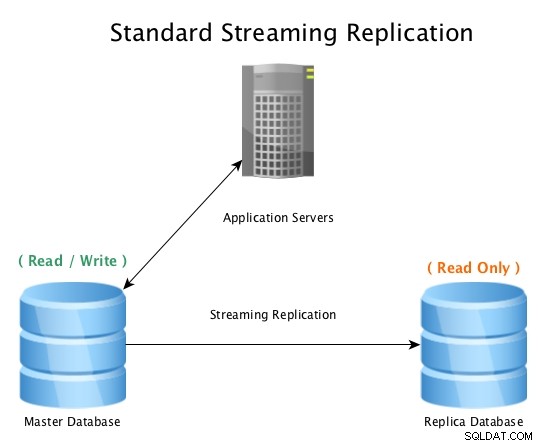 Réplication en continu standard avec PostgreSQL
Réplication en continu standard avec PostgreSQL Lorsque la base de données master devient inutilisable, une procédure de basculement est lancée pour la mettre hors ligne et promouvoir la base de données réplique en master, puis pointer toutes les connexions vers l'hôte nouvellement promu. Cela peut être fait en reconfigurant un équilibreur de charge, une configuration d'application, des alias IP ou d'autres moyens astucieux de rediriger le trafic.
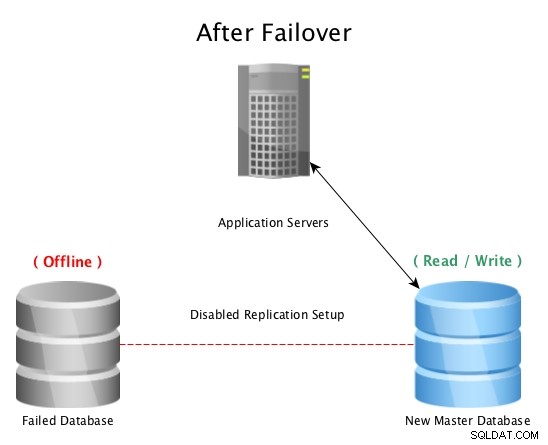 Après un basculement avec PostgreSQL Streaming Replication
Après un basculement avec PostgreSQL Streaming Replication Lorsqu'un sinistre frappe une base de données principale (telle qu'une panne de disque dur, une panne de courant ou tout ce qui empêche le maître de fonctionner comme prévu), le basculement vers un serveur de secours est le moyen le plus rapide de rester en ligne pour répondre aux requêtes des applications ou des clients sans sérieux temps d'arrêt. La course est alors lancée pour réparer l'hôte de base de données défaillant ou mettre en ligne une nouvelle réplique pour maintenir le filet de sécurité d'avoir une réserve prête à l'emploi. Avoir plusieurs veilles garantira que la fenêtre après une panne désastreuse est également prête pour une panne secondaire, aussi improbable que cela puisse paraître.
Remarque :lors du basculement vers un réplica en streaming, il reprendra là où le maître précédent s'est arrêté, ce qui permet de maintenir la base de données en ligne, mais de ne pas récupérer les données perdues accidentellement.
Récupération ponctuelle
Une autre option de récupération après sinistre est la récupération ponctuelle (PITR). Avec PITR, une copie de la base de données peut être récupérée à tout moment, tant que nous avons une sauvegarde de base antérieure à cette date et tous les segments WAL nécessaires jusqu'à cette date.
Une option de récupération ponctuelle n'est pas mise en ligne aussi rapidement qu'un Hot Standby, mais le principal avantage est de pouvoir récupérer un instantané de base de données avant un événement important tel qu'une table supprimée, l'insertion de mauvaises données ou même une corruption inexplicable des données. . Tout ce qui détruirait des données de telle manière que nous voudrions en obtenir une copie avant cette destruction, PITR sauve la mise.
La récupération ponctuelle fonctionne en créant des instantanés périodiques de la base de données, généralement en utilisant le programme pg_basebackup, et en conservant des copies archivées de tous les fichiers WAL générés par le maître
Configuration de la récupération à un moment précis
L'installation nécessite quelques options de configuration définies sur le maître, dont certaines sont compatibles avec les valeurs par défaut de la dernière version actuelle, PostgreSQL 11. Dans cet exemple, nous allons copier le fichier de 16 Mo directement sur notre hôte PITR distant à l'aide de rsync , et de les compresser de l'autre côté avec une tâche cron.
Archivage WAL
Maître postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'REMARQUE : Le paramètre archive_command peut être beaucoup de choses, l'objectif global est d'envoyer tous les fichiers WAL archivés vers un autre hôte pour des raisons de sécurité. Si nous perdons des fichiers WAL, PITR après le fichier WAL perdu devient impossible. Laissez libre cours à votre créativité en matière de programmation, mais assurez-vous qu'elle est fiable.
[Facultatif] Compressez les fichiers WAL archivés :
Chaque configuration variera quelque peu, mais à moins que la base de données en question soit très légère dans les mises à jour de données, l'accumulation de fichiers de 16 Mo remplira assez rapidement l'espace disque. Un script de compression facile, configuré via cron, pourrait ressembler à ci-dessous.
compresser_WAL_archive.sh :
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]REMARQUE : Au cours de toute méthode de récupération, tous les fichiers compressés devront être décompressés ultérieurement. Certains administrateurs choisissent de ne compresser les fichiers qu'après un nombre de jours X, en gardant un espace global faible, mais en gardant également les fichiers WAL les plus récents prêts pour la récupération sans travail supplémentaire. Choisissez la meilleure option pour les bases de données en question afin de maximiser votre vitesse de récupération.
Sauvegardes de base
L'un des composants clés d'une sauvegarde PITR est la sauvegarde de base et la fréquence des sauvegardes de base. Celles-ci peuvent être horaires, quotidiennes, hebdomadaires, mensuelles, mais choisissez la meilleure option en fonction des besoins de récupération ainsi que du trafic de la rotation des données de la base de données. Si nous avons des sauvegardes hebdomadaires tous les dimanches et que nous devons récupérer jusqu'au samedi après-midi, nous mettons en ligne la sauvegarde de base du dimanche précédent avec tous les fichiers WAL entre cette sauvegarde et le samedi après-midi. Si ce processus de récupération prend 10 heures à traiter, c'est probablement trop long, les sauvegardes de base quotidiennes réduiront ce temps de récupération, puisque la sauvegarde de base serait de ce matin, mais augmentera également la quantité de travail sur l'hôte pour la sauvegarde de base lui-même.
Si une récupération d'une semaine de fichiers WAL ne prend que quelques minutes, car la base de données connaît un faible taux de désabonnement, les sauvegardes hebdomadaires conviennent. Les mêmes données existeront à la fin, mais la vitesse à laquelle vous pourrez y accéder est la clé.
Dans notre exemple, nous allons configurer une sauvegarde de base hebdomadaire, et puisque nous utilisons la réplication en continu pour la haute disponibilité, en plus de réduire la charge sur le maître, nous allons créer la sauvegarde de base à partir de la base de données répliquée.
base_backup.sh :
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zREMARQUE : La commande pg_basebackup suppose que cet hôte est configuré pour un accès sans mot de passe pour la "réplication" de l'utilisateur sur le maître, ce qui peut être fait soit par "confiance" dans pg_hba pour cet hôte de sauvegarde PITR, mot de passe dans le fichier .pgpass, ou d'autres moyens plus sécurisés . Gardez la sécurité à l'esprit lors de la configuration des sauvegardes.
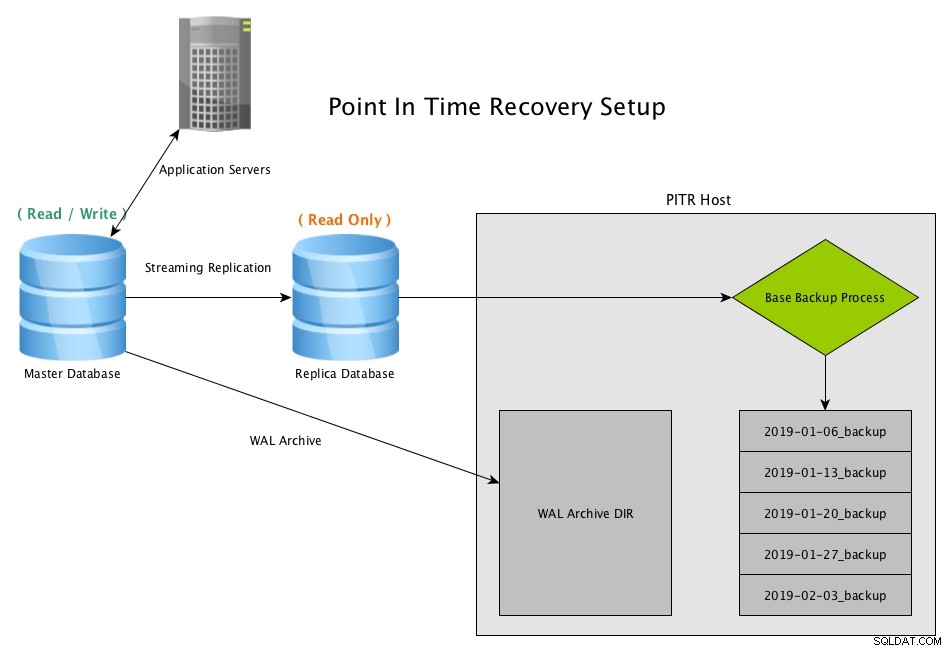 Récupération ponctuelle (PITR) d'une réplique en continu avec PostgreSQLTélécharger le livre blanc aujourd'hui Gestion et automatisation de PostgreSQL avec ClusterControlEn savoir plus ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blanc
Récupération ponctuelle (PITR) d'une réplique en continu avec PostgreSQLTélécharger le livre blanc aujourd'hui Gestion et automatisation de PostgreSQL avec ClusterControlEn savoir plus ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blanc Scénario de récupération PITR
La configuration de la récupération ponctuelle n'est qu'une partie du travail, la récupération des données est l'autre partie. Avec un peu de chance, cela n'arrivera peut-être jamais, mais il est fortement suggéré de faire périodiquement une restauration d'une sauvegarde PITR pour valider que le système fonctionne et pour s'assurer que le processus est connu / correctement scénarisé.
Dans notre scénario de test, nous choisirons un moment dans le temps pour récupérer et lancer le processus de récupération. Par exemple :le vendredi matin, un développeur pousse un nouveau changement de code en production sans passer par une révision du code, et cela détruit un tas de données client importantes. Étant donné que notre Hot Standby est toujours synchronisé avec le maître, le basculement vers celui-ci ne résoudrait rien, car il s'agirait des mêmes données. Les sauvegardes PITR sont ce qui nous sauvera.
Le code push est entré à 11h, nous devons donc restaurer la base de données juste avant cette heure, 10h59, nous décidons, et heureusement, nous faisons des sauvegardes quotidiennes afin que nous ayons une sauvegarde à partir de minuit ce matin. Comme nous ne savons pas ce qui a été détruit, nous décidons également de faire une restauration complète de cette base de données sur notre hôte PITR, et de la mettre en ligne en tant que maître, car elle a les mêmes spécifications matérielles que le maître, juste au cas où cela scénario s'est produit.
Éteindre le maître
Puisque nous avons décidé de restaurer entièrement à partir d'une sauvegarde et de la promouvoir en tant que maître, il n'est pas nécessaire de la conserver en ligne. Nous l'avons éteint, mais nous le gardons au cas où nous aurions besoin de récupérer quoi que ce soit plus tard, juste au cas où.
Configurer la sauvegarde de base pour la restauration
Ensuite, sur notre hôte PITR, nous récupérons notre sauvegarde de base la plus récente avant l'événement, qui est la sauvegarde "2018-12-21_backup".
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Avec cela, la sauvegarde de base, ainsi que les fichiers WAL fournis par pg_basebackup sont prêts à fonctionner, si nous le mettons en ligne maintenant, il récupérera au point où la sauvegarde a eu lieu, mais nous voulons récupérer toutes les transactions WAL entre minuit et 11h59, nous avons donc configuré notre fichier recovery.conf.
Créer recovery.conf
Étant donné que cette sauvegarde provient en réalité d'un réplica en streaming, il existe probablement déjà un fichier recovery.conf avec les paramètres du réplica. Nous allons l'écraser avec de nouveaux paramètres. Une liste d'informations détaillées pour toutes les différentes options est disponible dans la documentation de PostgreSQL ici.
En faisant attention aux fichiers WAL, la commande de restauration copiera les fichiers compressés dont elle a besoin dans le répertoire de restauration, les décompressera, puis se déplacera là où PostgreSQL en a besoin pour la récupération. Les fichiers WAL d'origine resteront là où ils se trouvent au cas où ils seraient nécessaires pour d'autres raisons.
Nouveau recovery.conf :
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Démarrer le processus de récupération
Maintenant que tout est configuré, nous allons lancer le processus de récupération. Lorsque cela se produit, il est judicieux de suivre le journal de la base de données pour vous assurer qu'il se rétablit comme prévu.
Démarrez la base de données :
pg_ctl -D /var/lib/pgsql/11/data startSuivez les journaux :
Il y aura de nombreuses entrées de journal indiquant que la base de données est en train de récupérer à partir de fichiers d'archive, et à un certain moment, une ligne indiquant "la récupération s'arrête avant la validation de la transaction…"
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07À ce stade, le processus de récupération a ingéré tous les fichiers WAL, mais doit également être révisé avant d'être mis en ligne en tant que maître. Dans cet exemple, le journal note que la transaction suivante après l'heure cible de récupération de 11:59:00 était 11:59:01 et qu'elle n'a pas été récupérée. Pour vérifier, connectez-vous à la base de données et jetez un coup d'œil, la base de données en cours d'exécution doit être un instantané à 11h59 exactement.
Quand tout semble bon, il est temps de promouvoir la reprise en maître.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Maintenant, la base de données est en ligne, récupérée au point que nous avons décidé, et accepte les connexions en lecture/écriture en tant que nœud maître. Assurez-vous que tous les paramètres de configuration sont corrects et prêts pour la production.
La base de données est en ligne, mais le processus de récupération n'est pas encore terminé ! Maintenant que cette sauvegarde PITR est en ligne en tant que maître, une nouvelle configuration de veille et PITR doit être configurée, jusque-là, ce nouveau maître peut être en ligne et servir des applications, mais il n'est pas à l'abri d'un autre sinistre tant que tout n'est pas configuré à nouveau.
Autres scénarios de récupération ponctuelle
Rétablir une sauvegarde PITR pour une base de données entière est un cas extrême, mais il existe d'autres scénarios où seul un sous-ensemble de données est manquant, corrompu ou mauvais. Dans ces cas, nous pouvons faire preuve de créativité avec nos options de récupération. Sans mettre le maître hors ligne et le remplacer par une sauvegarde, nous pouvons mettre une sauvegarde PITR en ligne à l'heure exacte que nous voulons sur un autre hôte (ou un autre port si l'espace n'est pas un problème), et exporter les données récupérées à partir de la sauvegarde directement dans la base de données principale. Cela peut être utilisé pour récupérer une poignée de lignes, une poignée de tables ou toute configuration de données nécessaire.
Avec la réplication en continu et la récupération ponctuelle, PostgreSQL nous offre une grande flexibilité pour nous assurer que nous pouvons récupérer toutes les données dont nous avons besoin, tant que nous avons des hôtes de secours prêts à fonctionner en tant que maître ou des sauvegardes prêtes à être récupérées. Une bonne option de récupération après sinistre peut être encore étendue avec d'autres options de sauvegarde, plus de nœuds de réplique, plusieurs sites de sauvegarde sur différents centres de données et continents, des pg_dumps périodiques sur une autre réplique, etc.
Ces options peuvent s'additionner, mais la vraie question est "quelle est la valeur des données et combien êtes-vous prêt à dépenser pour les récupérer ?". Dans de nombreux cas, la perte de données est la fin d'une entreprise. De bonnes options de reprise après sinistre doivent donc être en place pour éviter que le pire ne se produise.