La gestion du trafic vers la base de données peut devenir de plus en plus difficile à mesure qu'elle augmente et que la base de données est en fait répartie sur plusieurs serveurs. Les clients PostgreSQL communiquent généralement avec un seul point de terminaison. Lorsqu'un nœud principal tombe en panne, les clients de la base de données continuent de réessayer avec la même adresse IP. Si vous avez basculé vers un nœud secondaire, l'application doit être mise à jour avec le nouveau point de terminaison. C'est là que vous voudriez placer un équilibreur de charge entre les applications et les instances de base de données. Il peut diriger les applications vers des nœuds de base de données disponibles/sains et basculer si nécessaire. Un autre avantage serait d'augmenter les performances de lecture en utilisant efficacement les répliques. Il est possible de créer un port en lecture seule qui équilibre les lectures entre les répliques. Dans ce blog, nous aborderons HAProxy. Nous verrons ce que c'est, comment cela fonctionne et comment le déployer pour PostgreSQL.
Qu'est-ce que HAProxy ?
HAProxy est un proxy open source qui peut être utilisé pour implémenter la haute disponibilité, l'équilibrage de charge et le proxy pour les applications basées sur TCP et HTTP.
En tant qu'équilibreur de charge, HAProxy distribue le trafic d'une origine vers une ou plusieurs destinations et peut définir des règles et/ou des protocoles spécifiques pour cette tâche. Si l'une des destinations cesse de répondre, elle est marquée comme étant hors ligne et le trafic est envoyé vers le reste des destinations disponibles.
Comment installer et configurer HAProxy manuellement
Pour installer HAProxy sur Linux, vous pouvez utiliser les commandes suivantes :
Sur le système d'exploitation Ubuntu/Debian :
$ apt-get install haproxy -ySur le système d'exploitation CentOS/RedHat :
$ yum install haproxy -yEt puis nous devons éditer le fichier de configuration suivant pour gérer notre configuration HAProxy :
$ /etc/haproxy/haproxy.cfgConfigurer notre HAProxy n'est pas compliqué, mais nous devons savoir ce que nous faisons. Nous avons plusieurs paramètres à configurer, selon la façon dont nous voulons que HAProxy fonctionne. Pour plus d'informations, nous pouvons suivre la documentation sur la configuration de HAProxy.
Regardons un exemple de configuration de base. Supposons que vous ayez la topologie de base de données suivante :
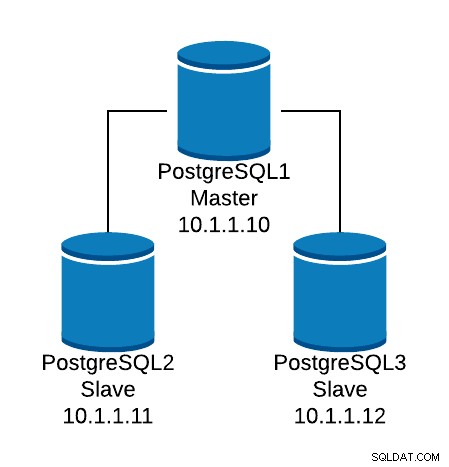 Exemple de topologie de base de données
Exemple de topologie de base de données Nous voulons créer un écouteur HAProxy pour équilibrer le trafic de lecture entre les trois nœuds.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkComme nous l'avons mentionné précédemment, il y a plusieurs paramètres à configurer ici, et cette configuration dépend de ce que nous voulons faire. Par exemple :
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkComment HAProxy fonctionne sur ClusterControl
Pour PostgreSQL, HAProxy est configuré par ClusterControl avec deux ports différents par défaut, un en lecture-écriture et un en lecture seule.
 ClusterControl Load Balancer Deploy Information 1
ClusterControl Load Balancer Deploy Information 1 Dans notre port en lecture-écriture, nous avons notre serveur maître en ligne et le reste de nos nœuds hors ligne, et dans le port en lecture seule, nous avons à la fois le maître et les esclaves en ligne.
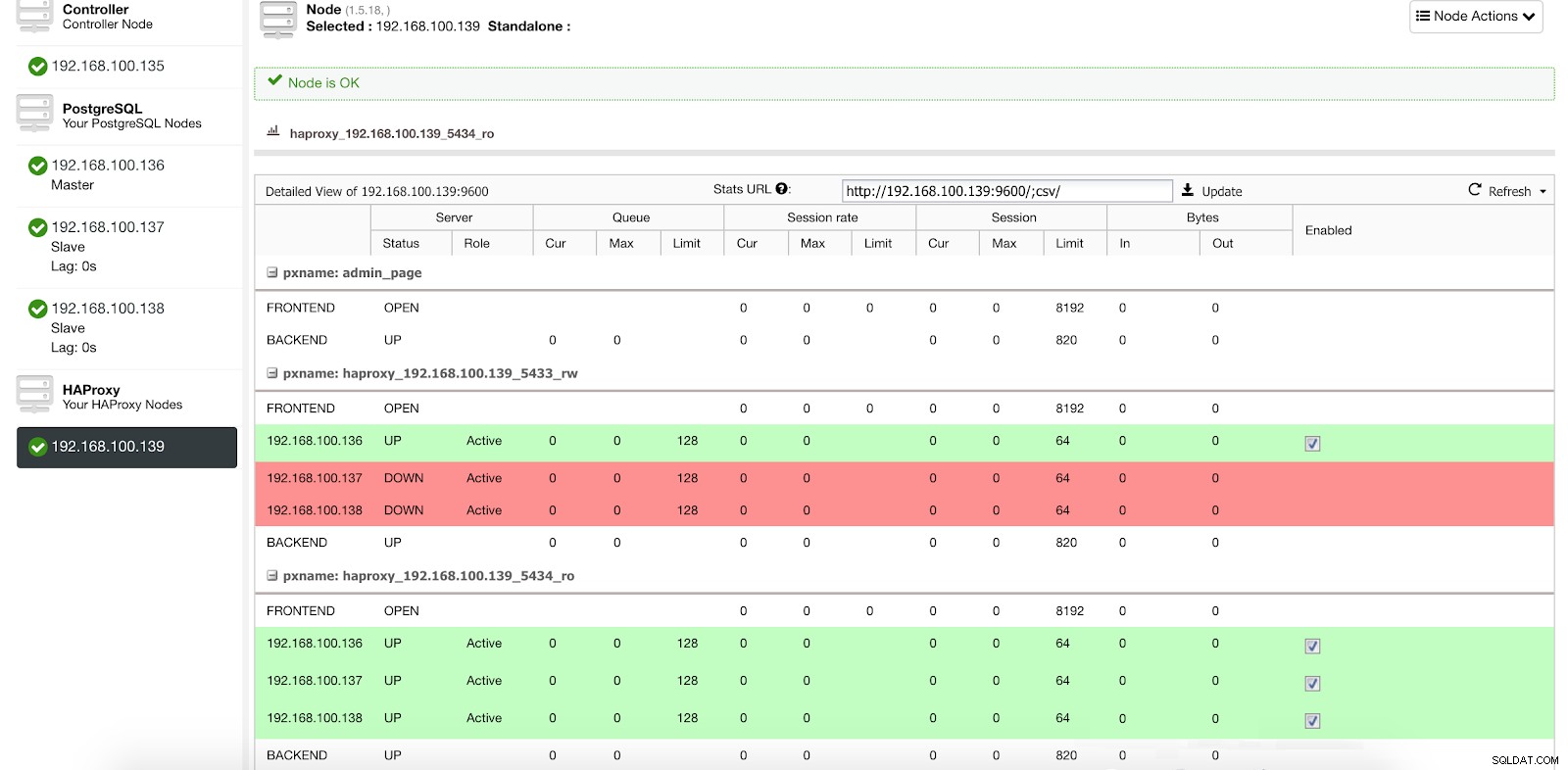 Statistiques de l'équilibreur de charge ClusterControl 1
Statistiques de l'équilibreur de charge ClusterControl 1 Lorsque HAProxy détecte qu'un de nos nœuds, qu'il soit maître ou esclave, n'est pas accessible, il le marque automatiquement comme hors ligne et n'en tient pas compte lors de l'envoi du trafic. La détection est effectuée par des scripts de vérification de l'état configurés par ClusterControl au moment du déploiement. Ceux-ci vérifient si les instances sont actives, si elles sont en cours de récupération ou sont en lecture seule.
Lorsque ClusterControl promeut un esclave en maître, notre HAProxy marque l'ancien maître comme étant hors ligne (pour les deux ports) et met le nœud promu en ligne (dans le port de lecture-écriture).
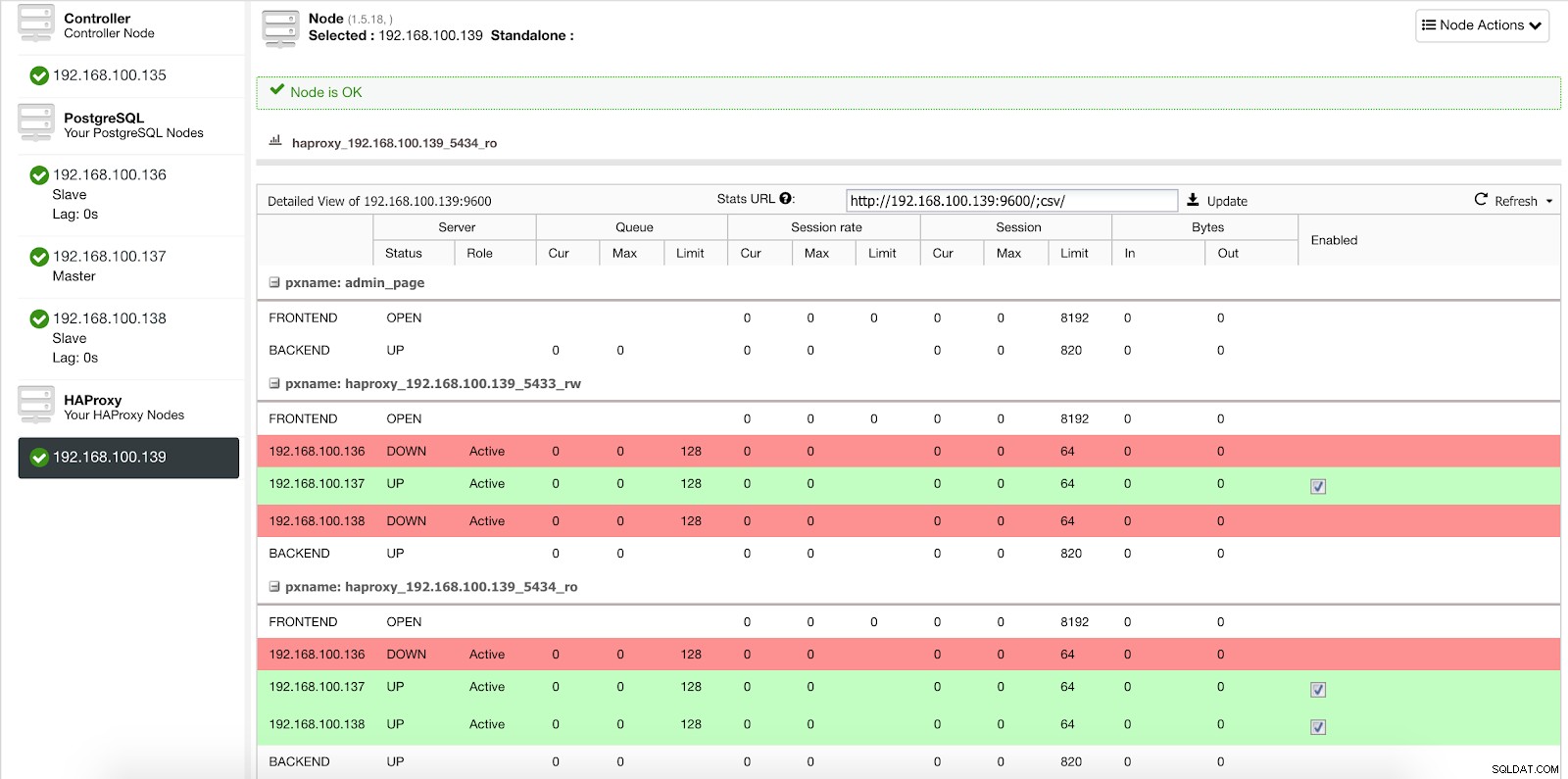 Statistiques de l'équilibreur de charge ClusterControl 2
Statistiques de l'équilibreur de charge ClusterControl 2 De cette façon, nos systèmes continuent de fonctionner normalement et sans notre intervention.
Comment déployer HAProxy avec ClusterControl
Dans notre exemple, nous avons créé un environnement avec 1 maître et 2 esclaves - voir une capture d'écran de la vue topologique dans ClusterControl. Nous allons maintenant ajouter notre équilibreur de charge HAProxy.
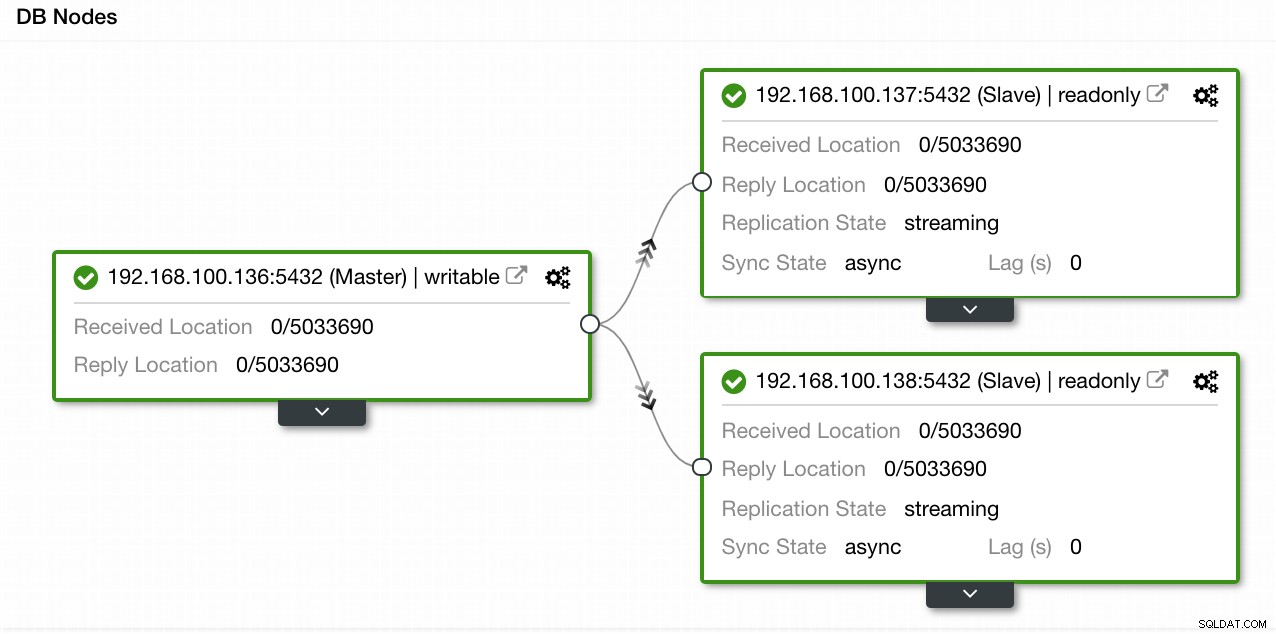 Vue de topologie ClusterControl 1
Vue de topologie ClusterControl 1 Pour cette tâche, nous devons accéder à ClusterControl -> Actions de cluster PostgreSQL -> Ajouter un équilibreur de charge
 Menu Actions du cluster ClusterControl
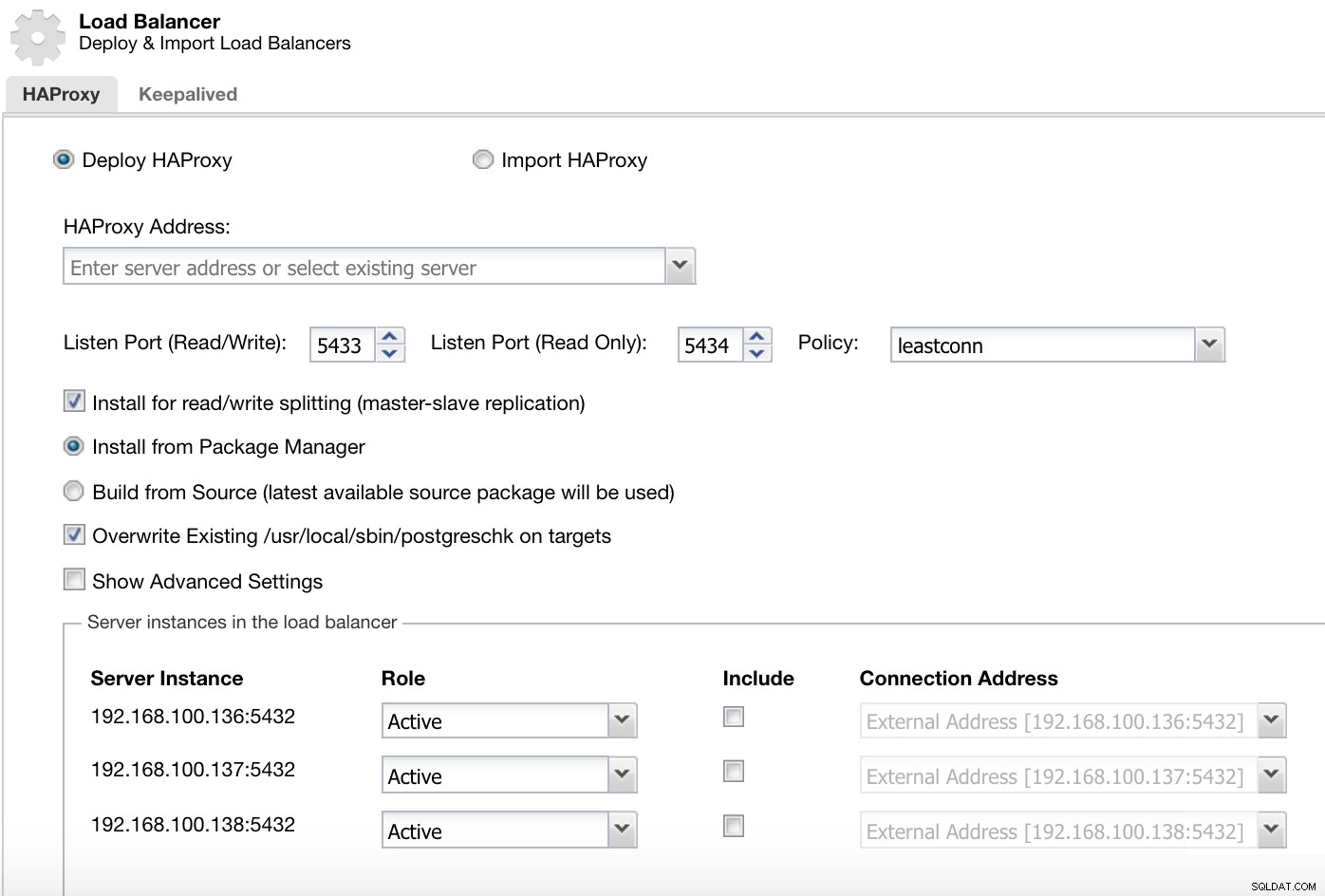
Menu Actions du cluster ClusterControl Ici, nous devons ajouter les informations que ClusterControl utilisera pour installer et configurer notre équilibreur de charge HAProxy.
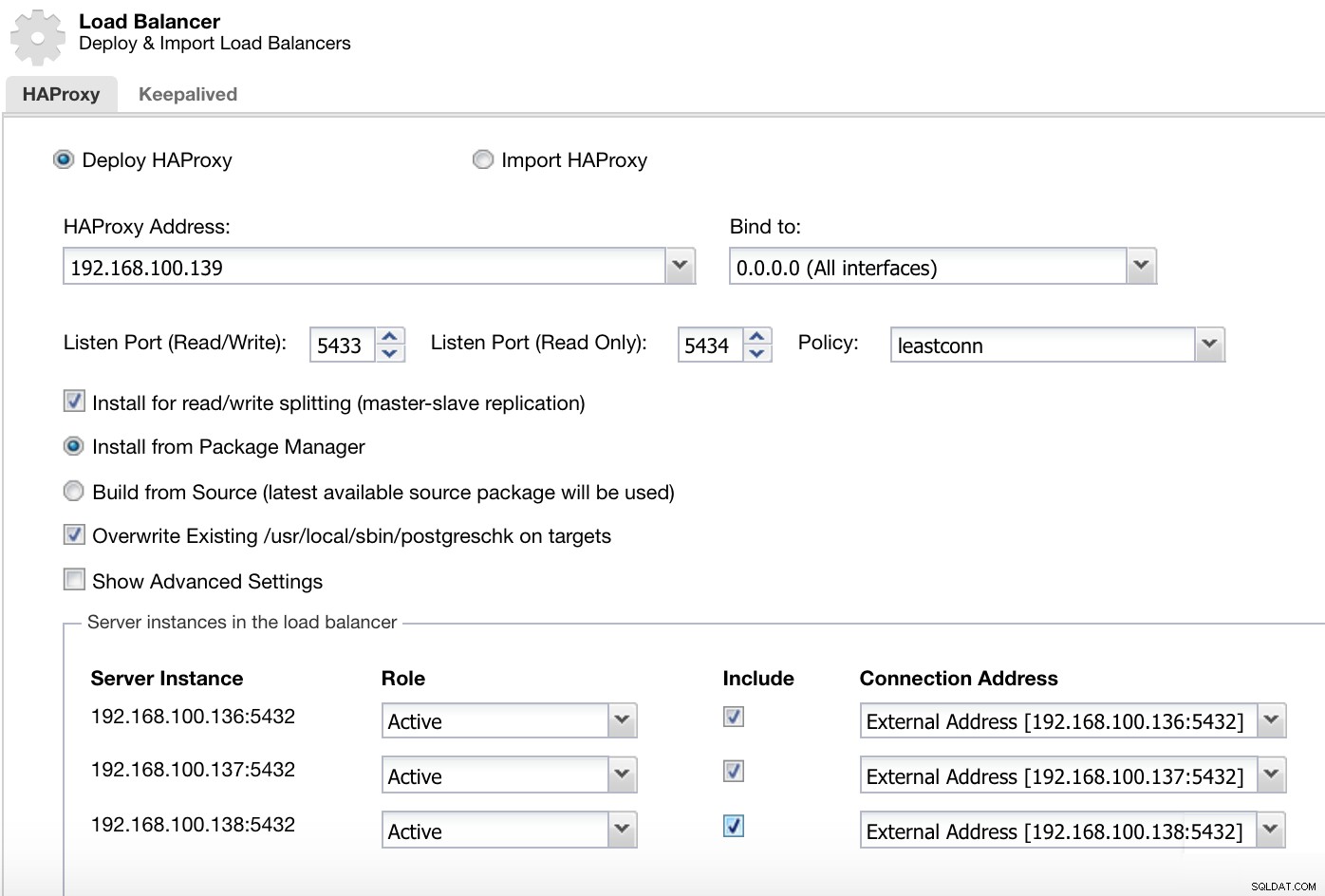 ClusterControl Load Balancer Deploy Information 2
ClusterControl Load Balancer Deploy Information 2 Les informations que nous devons introduire sont :
Action :déployer ou importer.
Adresse HAProxy :adresse IP de notre serveur HAProxy.
Lier à :Interface ou adresse IP où HAProxy écoutera.
Port d'écoute (lecture/écriture) :port pour le mode lecture/écriture.
Port d'écoute (lecture seule) :port pour le mode lecture seule.
Politique :Il peut s'agir :
- leastconn :le serveur avec le plus petit nombre de connexions reçoit la connexion.
- roundrobin :chaque serveur est utilisé à tour de rôle, en fonction de son poids.
- source :l'adresse IP source est hachée et divisée par le poids total des serveurs en cours d'exécution pour désigner le serveur qui recevra la requête.
Installer pour le fractionnement en lecture/écriture :pour la réplication maître-esclave.
Source :nous pouvons choisir d'installer à partir d'un gestionnaire de packages ou de créer à partir de la source.
Remplacer postgreschk existant sur les cibles.
Et nous devons sélectionner les serveurs que vous souhaitez ajouter à la configuration HAProxy et quelques informations supplémentaires telles que :
Rôle :il peut être actif ou de secours.
Inclure :Oui ou Non.
Informations sur l'adresse de connexion.
Nous pouvons également configurer des paramètres avancés tels que l'utilisateur administrateur, le nom du backend, les délais d'attente, etc.
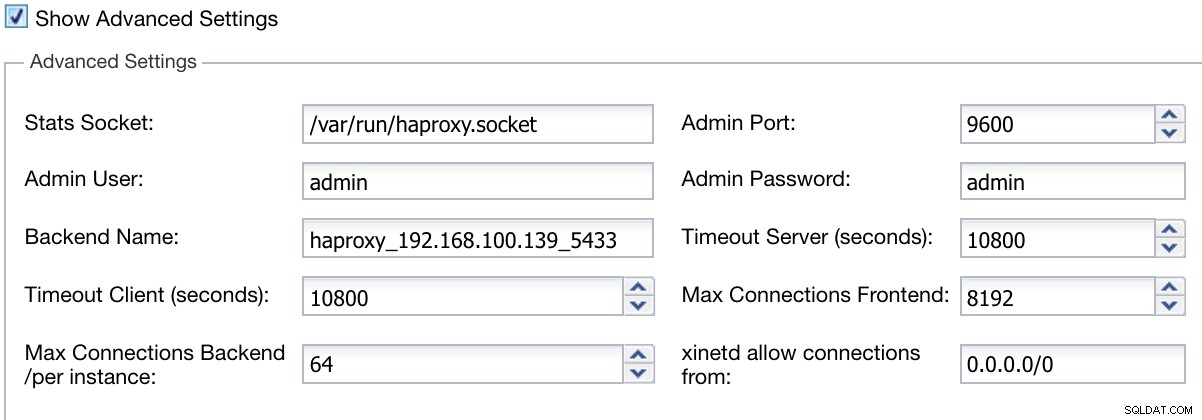 ClusterControl Load Balancer Deploy Information Avancé
ClusterControl Load Balancer Deploy Information Avancé Lorsque vous avez terminé la configuration et confirmé le déploiement, nous pouvons suivre la progression dans la section Activité de l'interface utilisateur de ClusterControl.
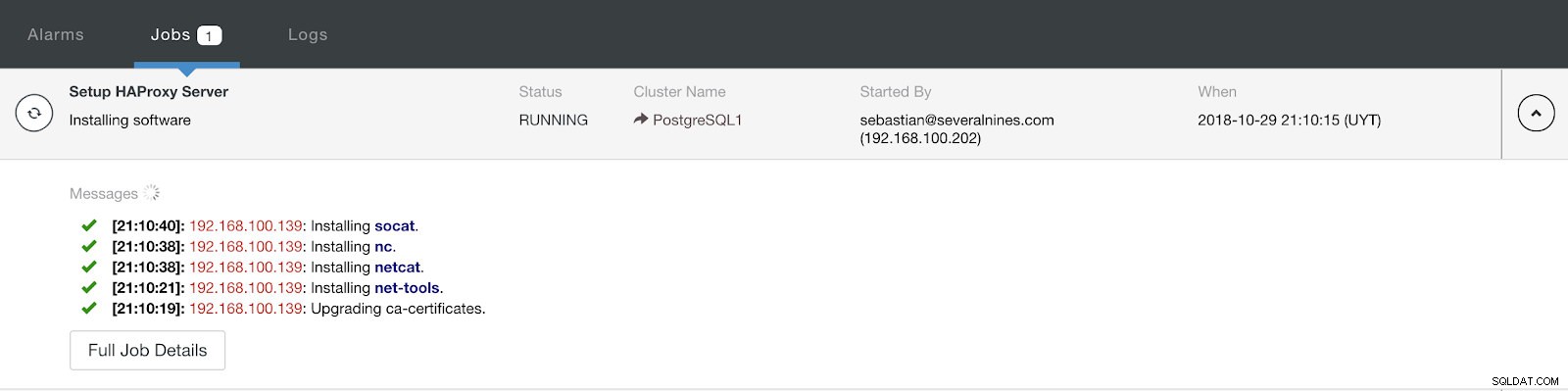 Section d'activité de contrôle de cluster
Section d'activité de contrôle de cluster Une fois terminé, nous devrions avoir la topologie suivante :
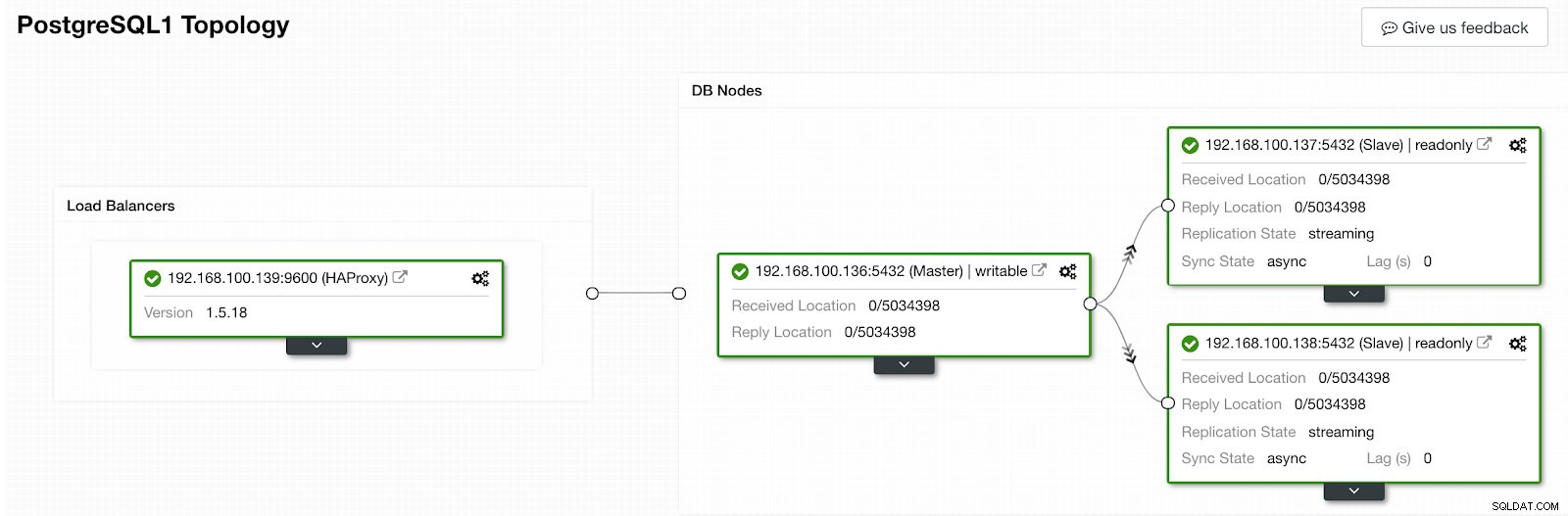 Vue de topologie ClusterControl 2
Vue de topologie ClusterControl 2 Nous pouvons améliorer notre conception HA en ajoutant un nouveau nœud HAProxy et en configurant le service Keepalived entre eux. Tout cela peut être effectué par ClusterControl. Pour plus d'informations, vous pouvez consulter notre blog précédent sur PostgreSQL et HA.
Utilisation de ClusterControl CLI pour ajouter un équilibreur de charge HAProxy
Également connu sous le nom d'outils s9s, ce package facultatif a été introduit dans la version 1.4.1 de ClusterControl, qui contient un binaire appelé s9s. Il s'agit d'un outil en ligne de commande pour interagir, contrôler et gérer votre infrastructure de base de données à l'aide de ClusterControl. Le projet de ligne de commande s9s est open source et peut être trouvé sur GitHub.
À partir de la version 1.4.1, le script d'installation installera automatiquement le package (s9s-tools) sur le nœud ClusterControl.
ClusterControl CLI ouvre une nouvelle porte pour l'automatisation des clusters où vous pouvez facilement l'intégrer aux outils d'automatisation de déploiement existants comme Ansible, Puppet, Chef ou Salt.
Regardons un exemple de création d'un équilibreur de charge HAProxy avec l'adresse IP 192.168.100.142 sur l'ID de cluster 1 :
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.Et ensuite, nous pouvons vérifier tous nos nœuds à partir de la ligne de commande :
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Pour plus d'informations sur s9s et son utilisation, vous pouvez consulter la documentation officielle ou ce blog sur ce sujet.
Conclusion
Dans ce blog, nous avons examiné comment HAProxy peut nous aider à gérer le trafic provenant de l'application vers notre base de données PostgreSQL. Nous avons vérifié comment il peut être déployé et configuré manuellement, puis nous avons vu comment il peut être automatisé avec ClusterControl. Afin d'éviter que HAProxy ne devienne un point de défaillance unique (SPOF), assurez-vous de déployer au moins deux instances HAProxy et d'implémenter quelque chose comme Keepalived et Virtual IP par-dessus.