L'utilisation de la réplication pour vos bases de données PostgreSQL peut être utile non seulement pour disposer d'un environnement hautement disponible et tolérant aux pannes, mais également pour améliorer les performances de votre système en équilibrant le trafic entre les nœuds de secours. Dans cette première partie du blog en deux parties, nous allons voir quelques concepts liés à la réplication PostgreSQL.
Méthodes de réplication dans PostgreSQL
Il existe différentes méthodes de réplication de données dans PostgreSQL, mais nous nous concentrerons ici sur les deux méthodes principales :la réplication en continu et la réplication logique.
Réplication en continu
La réplication en continu PostgreSQL, la réplication PostgreSQL la plus courante, est une réplication physique qui réplique les modifications octet par octet, créant une copie identique de la base de données sur un autre serveur. Il est basé sur la méthode d'envoi de journaux. Les enregistrements WAL sont directement déplacés d'un serveur de base de données vers un autre pour être appliqués. On peut dire que c'est une sorte de PITR continu.
Ce transfert WAL est effectué de deux manières différentes, en transférant les enregistrements WAL un fichier (segment WAL) à la fois (envoi de journaux basé sur les fichiers) et en transférant les enregistrements WAL (un fichier WAL est composé de WAL records) à la volée (record based log shipping), entre un serveur primaire et un ou plusieurs serveurs de secours, sans attendre que le fichier WAL soit rempli.
En pratique, un processus appelé récepteur WAL, s'exécutant sur le serveur de secours, se connectera au serveur principal à l'aide d'une connexion TCP/IP. Dans le serveur primaire, un autre processus existe, nommé WAL sender, et est chargé d'envoyer les registres WAL au serveur de secours au fur et à mesure qu'ils se produisent.
Une réplication de flux de base peut être représentée comme suit :
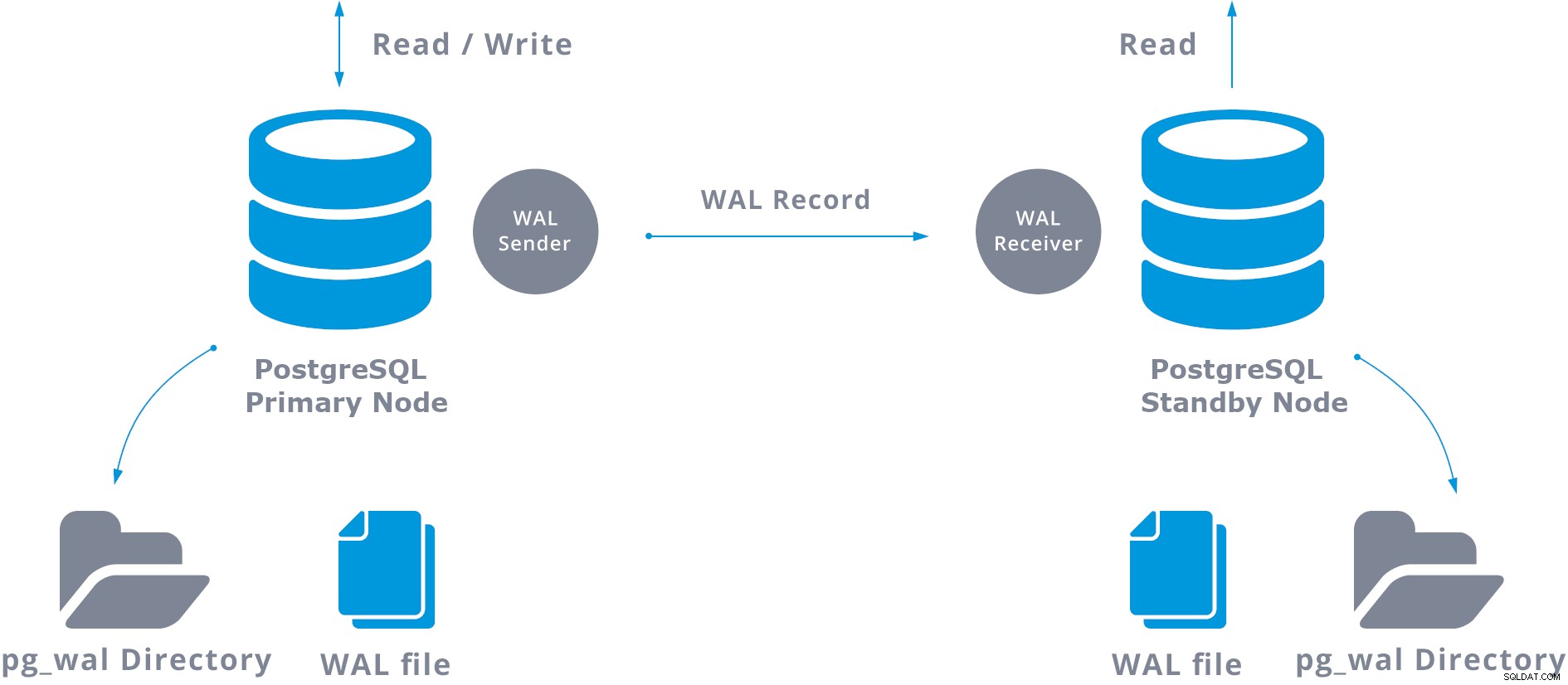
Lors de la configuration de la réplication en continu, vous avez la possibilité d'activer l'archivage WAL. Ce n'est pas obligatoire, mais c'est extrêmement important pour une configuration de réplication robuste, car il est nécessaire d'éviter que le serveur principal ne recycle les anciens fichiers WAL qui n'ont pas encore été appliqués au serveur de secours. Si cela se produit, vous devrez recréer la réplique à partir de zéro.
Réplication logique
La réplication logique PostgreSQL est une méthode de réplication des objets de données et de leurs modifications, basée sur leur identité de réplication (généralement une clé primaire). Il est basé sur un mode de publication et d'abonnement, où un ou plusieurs abonnés s'abonnent à une ou plusieurs publications sur un nœud d'éditeur.
Une publication est un ensemble de modifications générées à partir d'une table ou d'un groupe de tables. Le nœud où une publication est définie est appelé éditeur. Un abonnement est le côté aval de la réplication logique. Le nœud où un abonnement est défini est appelé l'abonné, et il définit la connexion à une autre base de données et un ensemble de publications (une ou plusieurs) auxquelles il souhaite s'abonner. Les abonnés extraient les données des publications auxquelles ils sont abonnés.
La réplication logique est construite avec une architecture similaire à la réplication physique en continu. Il est implémenté par les processus "walsender" et "apply". Le processus walsender lance le décodage logique du WAL et charge le plugin de décodage logique standard. Le plugin transforme les modifications lues depuis WAL vers le protocole de réplication logique et filtre les données en fonction de la spécification de publication. Les données sont ensuite transférées en continu à l'aide du protocole de réplication en continu vers le travailleur d'application, qui mappe les données sur des tables locales et applique les modifications individuelles au fur et à mesure de leur réception, dans un ordre transactionnel correct.
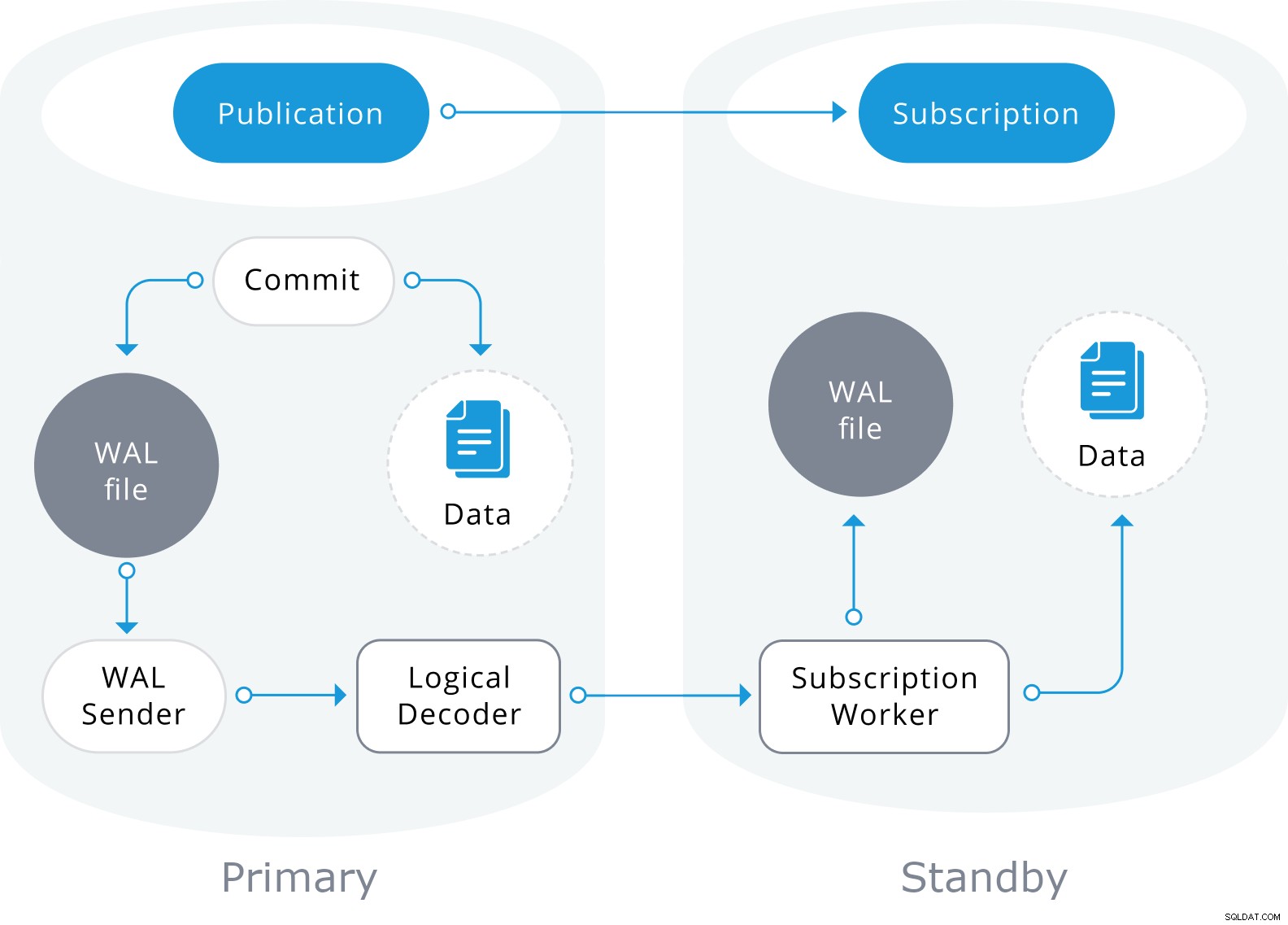
La réplication logique commence par prendre un instantané des données sur la base de données de l'éditeur et copier cela à l'abonné. Les données initiales des tables souscrites existantes sont prises en instantané et copiées dans une instance parallèle d'un type spécial de processus d'application. Ce processus créera son propre emplacement de réplication temporaire et copiera les données existantes. Une fois les données existantes copiées, l'agent passe en mode de synchronisation, ce qui garantit que la table est mise à un état synchronisé avec le processus d'application principal en diffusant en continu toutes les modifications survenues lors de la copie initiale des données à l'aide de la réplication logique standard. Une fois la synchronisation effectuée, le contrôle de la réplication de la table est rendu au processus d'application principal où la réplication se poursuit normalement. Les modifications apportées à l'éditeur sont envoyées à l'abonné au fur et à mesure qu'elles se produisent en temps réel.
Modes de réplication dans PostgreSQL
La réplication dans PostgreSQL peut être synchrone ou asynchrone.
Réplication asynchrone
C'est le mode par défaut. Ici, il est possible d'avoir certaines transactions validées dans le nœud principal qui n'ont pas encore été répliquées sur le serveur de secours. Cela signifie qu'il existe une possibilité de perte de données potentielle. Ce délai dans le processus de validation est censé être très faible si le serveur de secours est suffisamment puissant pour suivre la charge. Si ce petit risque de perte de données n'est pas acceptable dans l'entreprise, vous pouvez utiliser la réplication synchrone à la place.
Réplication synchrone
Chaque validation d'une transaction d'écriture attendra la confirmation que la validation a été écrite dans le journal d'écriture anticipée sur le disque du serveur principal et du serveur de secours. Cette méthode minimise la possibilité de perte de données. Pour qu'une perte de données se produise, il faudrait que le primaire et le standby tombent en panne en même temps.
L'inconvénient de cette méthode est le même pour toutes les méthodes synchrones car avec cette méthode le temps de réponse pour chaque transaction d'écriture augmente. Cela est dû à la nécessité d'attendre jusqu'à toutes les confirmations que la transaction a été validée. Heureusement, les transactions en lecture seule ne seront pas affectées par cela mais ; uniquement les transactions d'écriture.
Haute disponibilité pour la réplication PostgreSQL
La haute disponibilité est une exigence pour de nombreux systèmes, quelle que soit la technologie utilisée, et il existe différentes approches pour y parvenir à l'aide de différents outils.
Équilibrage de charge
Les équilibreurs de charge sont des outils qui peuvent être utilisés pour gérer le trafic de votre application afin de tirer le meilleur parti de votre architecture de base de données. Non seulement il est utile pour équilibrer la charge de nos bases de données, mais il aide également les applications à être redirigées vers les nœuds disponibles/sains et même à spécifier des ports avec des rôles différents.
HAProxy est un équilibreur de charge qui répartit le trafic d'une origine vers une ou plusieurs destinations et peut définir des règles et/ou des protocoles spécifiques pour cette tâche. Si l'une des destinations cesse de répondre, elle est marquée comme étant hors ligne et le trafic est envoyé au reste des destinations disponibles. Avoir un seul nœud Load Balancer générera un point de défaillance unique, donc pour éviter cela, vous devez déployer au moins deux nœuds HAProxy et configurer Keepalived entre eux.
Keepalived est un service qui nous permet de configurer une adresse IP virtuelle au sein d'un groupe de serveurs actifs/passifs. Cette adresse IP virtuelle est attribuée à un serveur actif. Si ce serveur tombe en panne, l'IP est automatiquement migrée vers le serveur passif "Secondaire", lui permettant de continuer à fonctionner avec la même IP de manière transparente pour les systèmes.
Améliorer les performances de la réplication PostgreSQL
La performance est toujours importante dans n'importe quel système. Vous devrez faire bon usage des ressources disponibles pour assurer le meilleur temps de réponse possible et il existe différentes façons de le faire. Chaque connexion à une base de données consomme des ressources. L'un des moyens d'améliorer les performances de votre base de données PostgreSQL consiste donc à disposer d'un bon pool de connexions entre votre application et les serveurs de base de données.
Groupeurs de connexions
Un regroupement de connexions est une méthode pour créer un pool de connexions et les réutiliser, en évitant d'ouvrir constamment de nouvelles connexions à la base de données, ce qui augmentera considérablement les performances de vos applications. PgBouncer est un pooleur de connexions populaire conçu pour PostgreSQL.
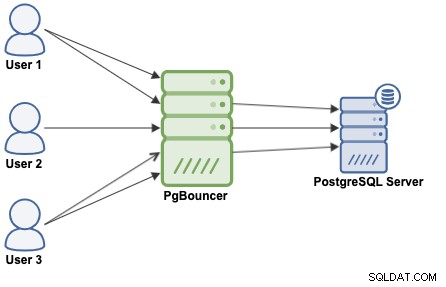
PgBouncer agit comme un serveur PostgreSQL, il vous suffit donc d'accéder à votre base de données en utilisant les informations de PgBouncer (adresse IP/nom d'hôte et port), et PgBouncer créera une connexion au serveur PostgreSQL, ou en réutilisera une si elle existe.
Lorsque PgBouncer reçoit une connexion, il effectue l'authentification, qui dépend de la méthode spécifiée dans le fichier de configuration. PgBouncer prend en charge tous les mécanismes d'authentification pris en charge par le serveur PostgreSQL. Après cela, PgBouncer recherche une connexion en cache, avec la même combinaison nom d'utilisateur + base de données. Si une connexion en cache est trouvée, il renvoie la connexion au client, sinon, il crée une nouvelle connexion. En fonction de la configuration de PgBouncer et du nombre de connexions actives, il est possible que la nouvelle connexion soit mise en file d'attente jusqu'à ce qu'elle puisse être créée, voire abandonnée.
Avec tous ces concepts mentionnés, dans la deuxième partie de ce blog, nous verrons comment vous pouvez les combiner pour avoir un bon environnement de réplication dans PostgreSQL.