Dans la première partie de ce blog, nous avons mentionné quelques concepts importants liés à un bon environnement de réplication PostgreSQL. Voyons maintenant comment combiner toutes ces choses de manière simple en utilisant ClusterControl. Pour cela, nous supposerons que vous avez installé ClusterControl, mais si ce n'est pas le cas, vous pouvez vous rendre sur le site officiel ou vous référer à la documentation officielle pour l'installer.
Déploiement de la réplication en continu PostgreSQL
Pour effectuer un déploiement d'un cluster PostgreSQL depuis ClusterControl, sélectionnez l'option Déployer et suivez les instructions qui s'affichent.
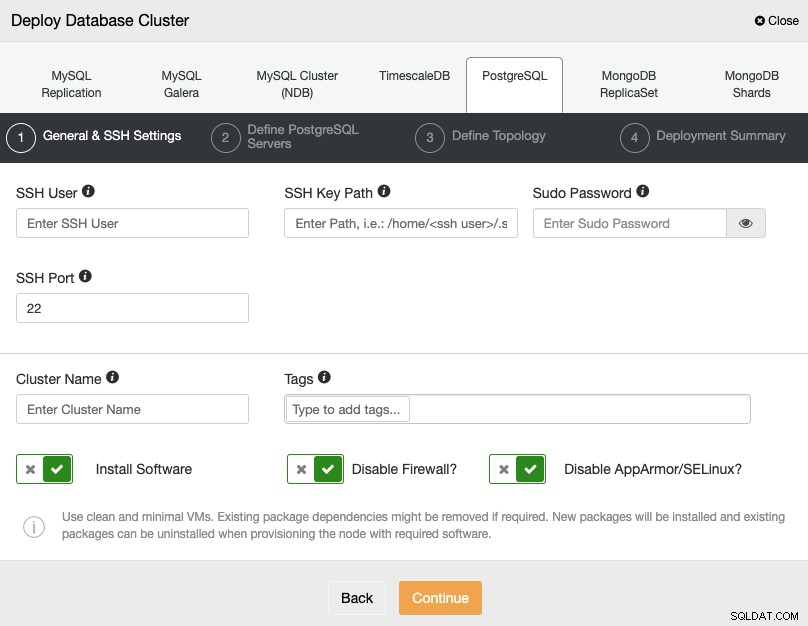
Lorsque vous sélectionnez PostgreSQL, vous devez spécifier l'utilisateur, la clé ou le mot de passe, et Port pour se connecter en SSH à vos serveurs. Vous pouvez également ajouter un nom pour votre nouveau cluster et spécifier si vous souhaitez que ClusterControl installe le logiciel et les configurations correspondants pour vous.
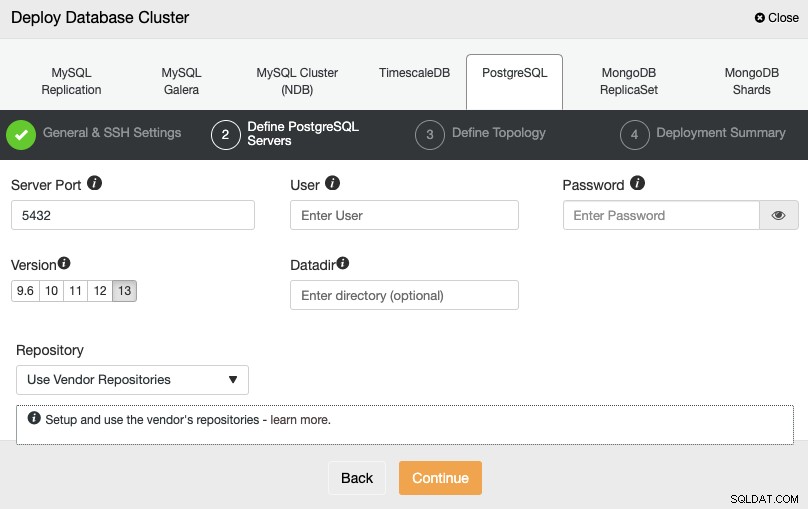
Après avoir configuré les informations d'accès SSH, vous devez définir les informations d'identification de la base de données , version et datadir (facultatif). Vous pouvez également spécifier le référentiel à utiliser.
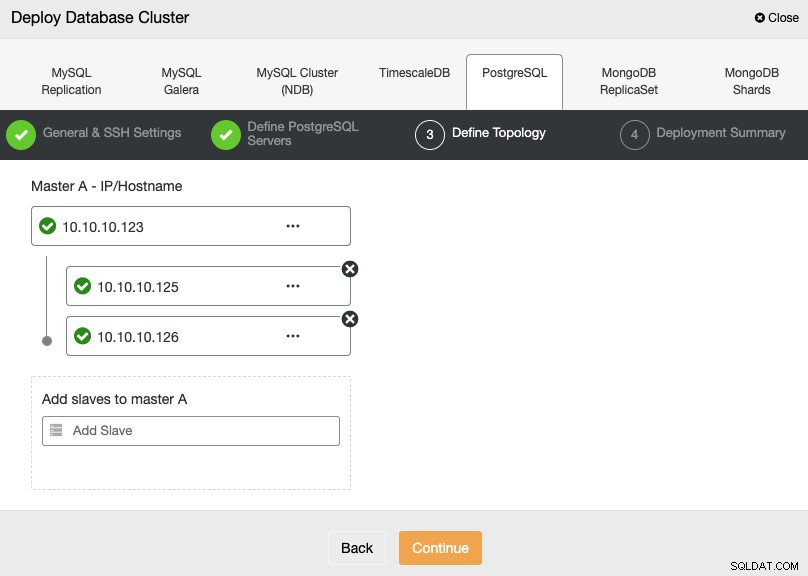
À l'étape suivante, vous devez ajouter vos serveurs au cluster que vous allez créer à l'aide de l'adresse IP ou du nom d'hôte.
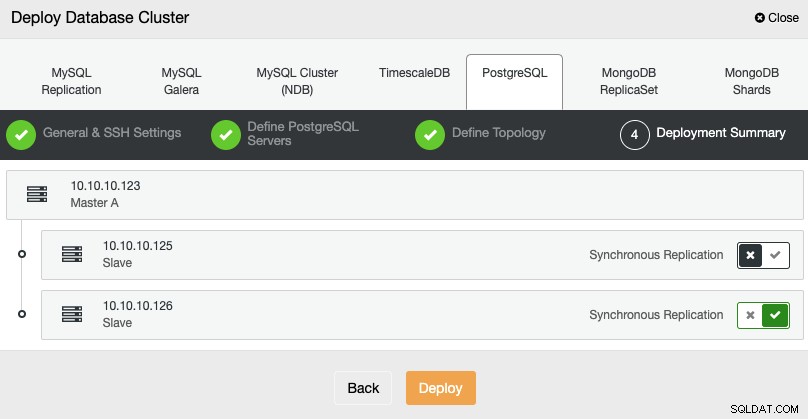
Dans la dernière étape, vous pouvez choisir si votre réplication sera synchrone ou Asynchrone, puis appuyez simplement sur Déployer.
Une fois la tâche terminée, vous pouvez voir votre nouveau cluster PostgreSQL dans le l'écran principal de ClusterControl.

Maintenant que votre cluster est créé, vous pouvez effectuer plusieurs tâches dessus, comme l'ajout d'un équilibreur de charge (HAProxy), d'un pool de connexions (PgBouncer) ou d'un nouvel esclave de réplication synchrone ou asynchrone.
Ajout d'esclaves de réplication synchrone et asynchrone
Allez dans ClusterControl -> Actions du cluster -> Ajouter un esclave de réplication.
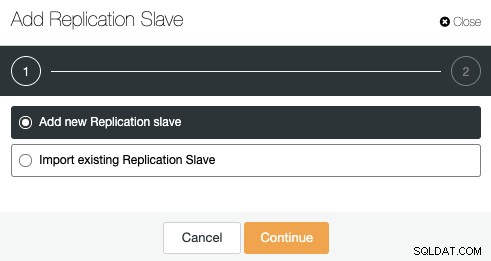
Vous pouvez ajouter un nouvel esclave de réplication, ou même en importer un existant. Choisissons la première option et continuons.
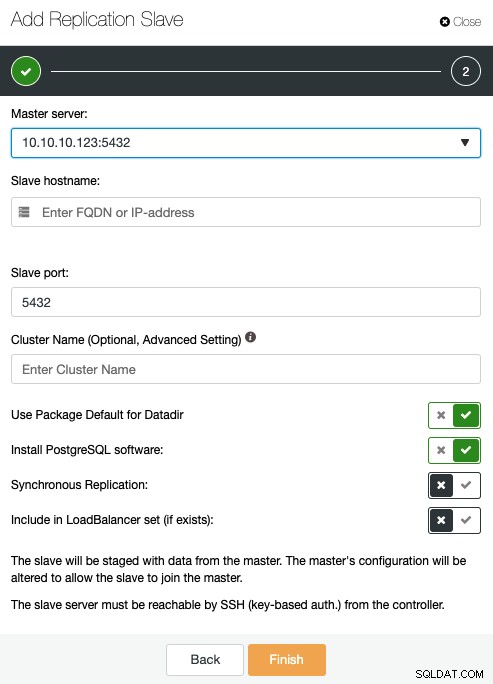
Ici, vous devez spécifier le serveur maître, l'adresse IP ou le nom d'hôte de le nouvel esclave de réplication, le port, et si vous voulez que ClusterControl installe le logiciel, ou incluez ce nœud dans un équilibreur de charge existant. Vous pouvez également configurer la réplication pour qu'elle soit synchrone ou asynchrone.
Maintenant que vous avez votre cluster PostgreSQL en place avec les réplicas correspondants, voyons comment améliorer les performances en ajoutant un pooler de connexions.
Déploiement de PgBouncer
Allez dans ClusterControl -> Sélectionnez PostgreSQL Cluster -> Actions de cluster -> Ajouter un équilibreur de charge -> PgBouncer. Ici, vous pouvez déployer un nouveau nœud PgBouncer qui sera déployé dans le nœud de base de données sélectionné, ou même importer un PgBouncer existant.
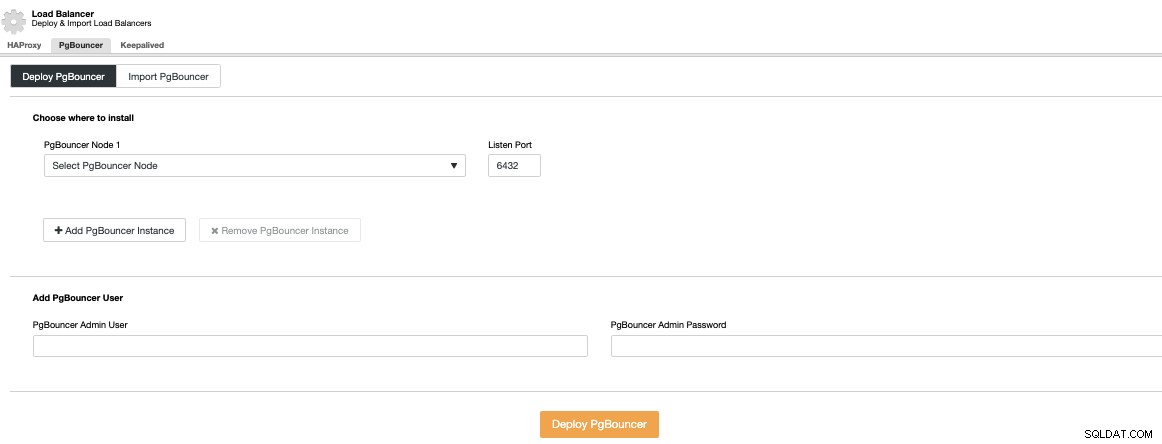
Vous devrez spécifier une adresse IP ou un nom d'hôte, le port d'écoute et Identifiants PgBouncer. Lorsque vous appuyez sur Deploy PgBouncer, ClusterControl accède au nœud, installe et configure tout sans aucune intervention manuelle.
Vous pouvez surveiller la progression dans la section d'activité ClusterControl. Une fois terminé, vous devez créer le nouveau pool. Pour cela, allez dans ClusterControl -> Sélectionnez le cluster PostgreSQL -> Nœuds -> nœud PgBouncer.
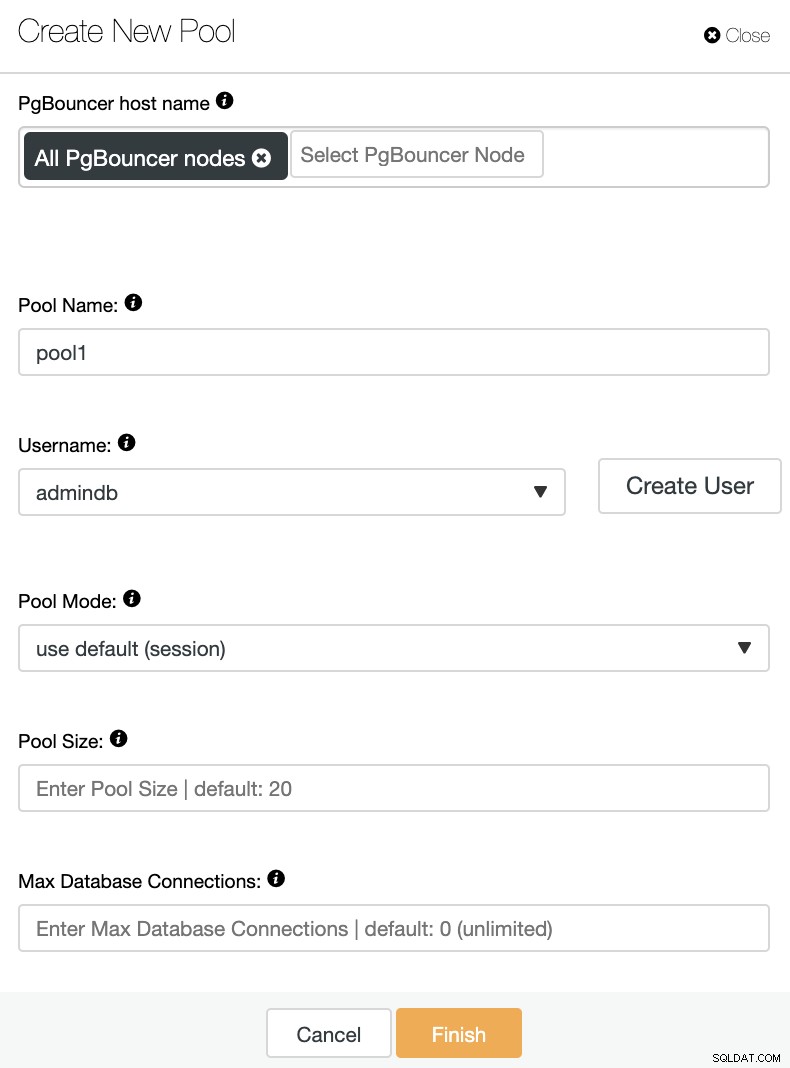
Vous devrez ajouter les informations suivantes :
-
Nom d'hôte PgBouncer :sélectionnez les hôtes de nœud pour créer le pool de connexion.
-
Nom du pool :les noms du pool et de la base de données doivent être identiques.
-
Nom d'utilisateur : Sélectionnez un utilisateur dans le nœud principal PostgreSQL ou créez-en un nouveau.
-
Mode pool :il peut s'agir :d'une session (par défaut), d'une transaction ou d'un pool d'instructions.
-
Taille du pool :taille maximale des pools pour cette base de données. La valeur par défaut est 20.
-
Nombre maximal de connexions à la base de données :configurez un maximum à l'échelle de la base de données. La valeur par défaut est 0, ce qui signifie illimité.
Maintenant, vous devriez pouvoir voir le Pool dans la section Node.
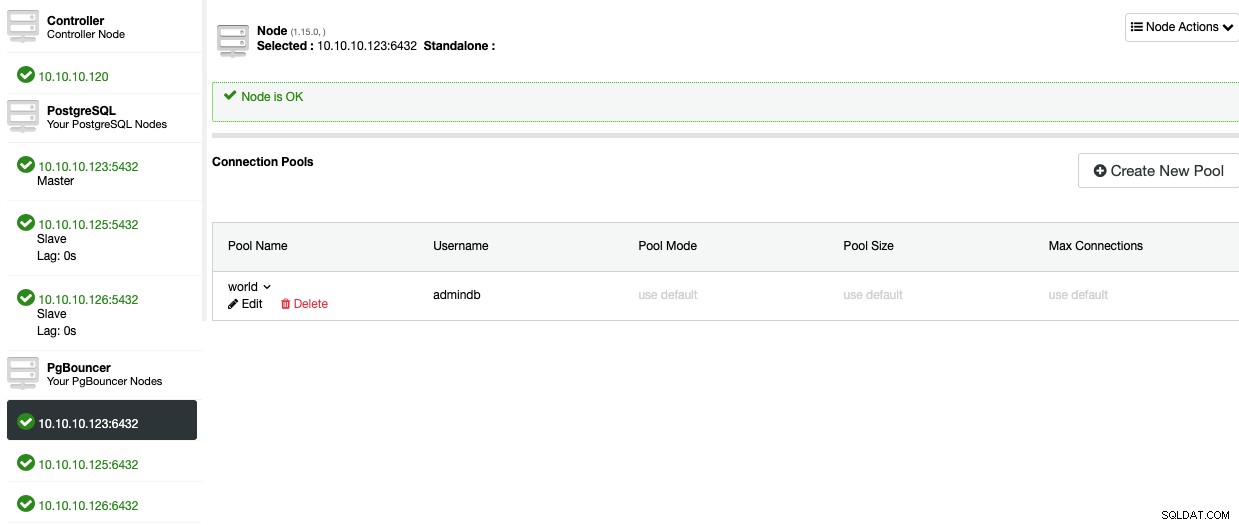
Pour ajouter la haute disponibilité à votre base de données PostgreSQL, voyons comment déployer un équilibreur de charge.
Déploiement de l'équilibreur de charge
Pour effectuer un déploiement d'équilibreur de charge, sélectionnez l'option Ajouter un équilibreur de charge dans le menu Actions du cluster et complétez les informations demandées.
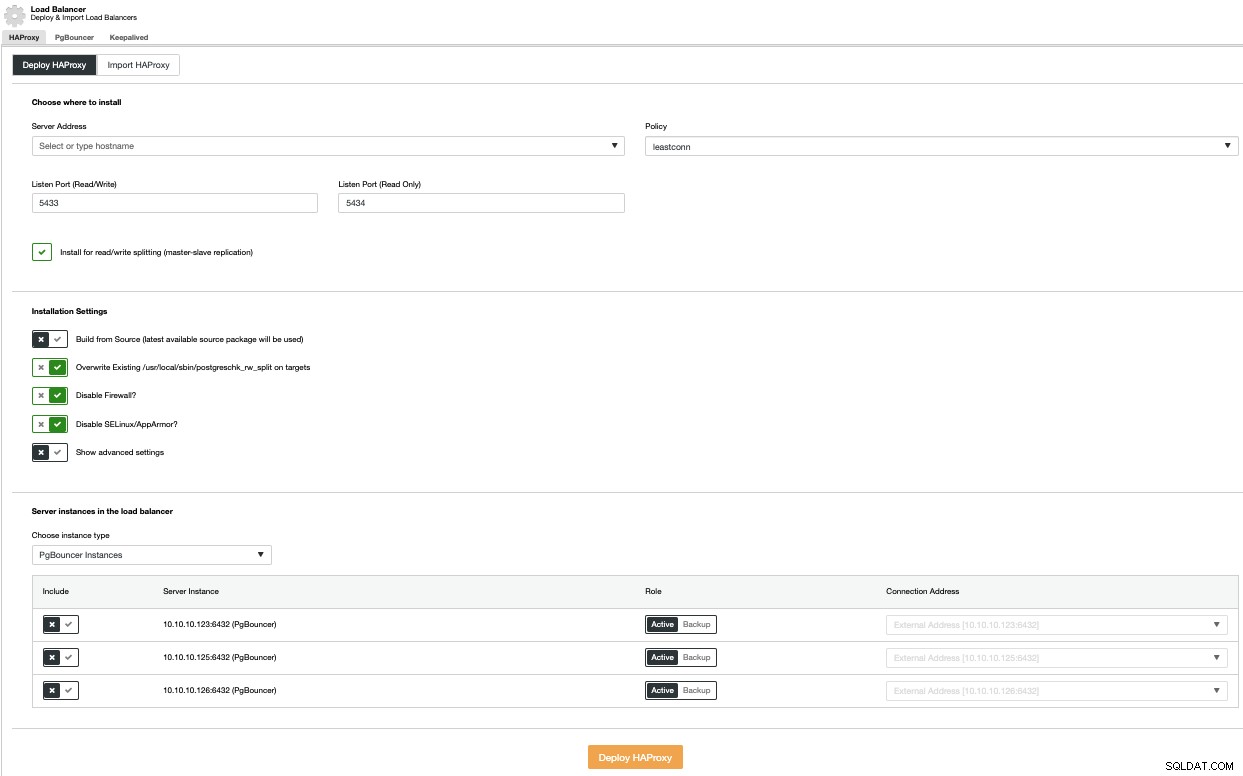
Vous devez ajouter une adresse IP ou un nom d'hôte, un port, une stratégie et les nœuds vous allez utiliser. Si vous utilisez PgBouncer, vous pouvez le choisir dans la liste déroulante des types d'instances.
Pour éviter un point de défaillance unique, vous devez déployer au moins deux nœuds HAProxy et utiliser Keepalived qui vous permet d'utiliser une adresse IP virtuelle dans votre application qui est attribuée au nœud HAProxy actif. Si ce nœud échoue, l'adresse IP virtuelle sera migrée vers l'équilibreur de charge secondaire, afin que votre application puisse toujours fonctionner comme d'habitude.
Déploiement Keepalive
Pour effectuer un déploiement Keepalived, sélectionnez l'option Add Load Balancer dans le menu Cluster Actions, puis accédez à l'onglet Keepalived.
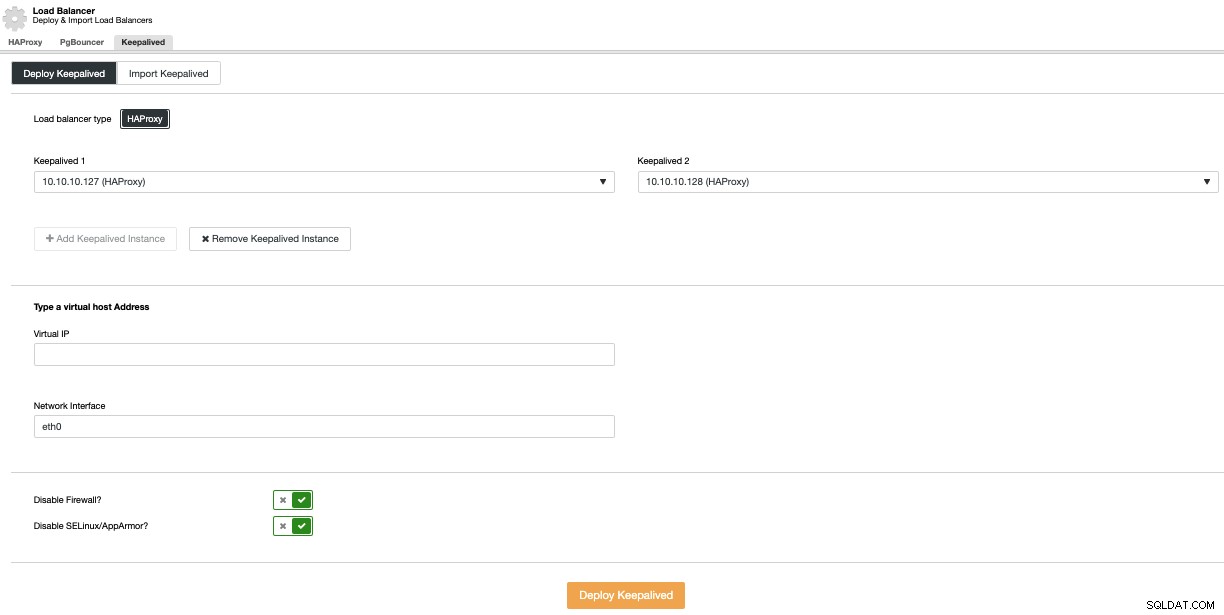
Ici, sélectionnez les nœuds HAProxy et spécifiez l'adresse IP virtuelle qui être utilisé pour accéder à la base de données (ou pooler de connexion).
À ce moment, vous devriez avoir la topologie suivante :
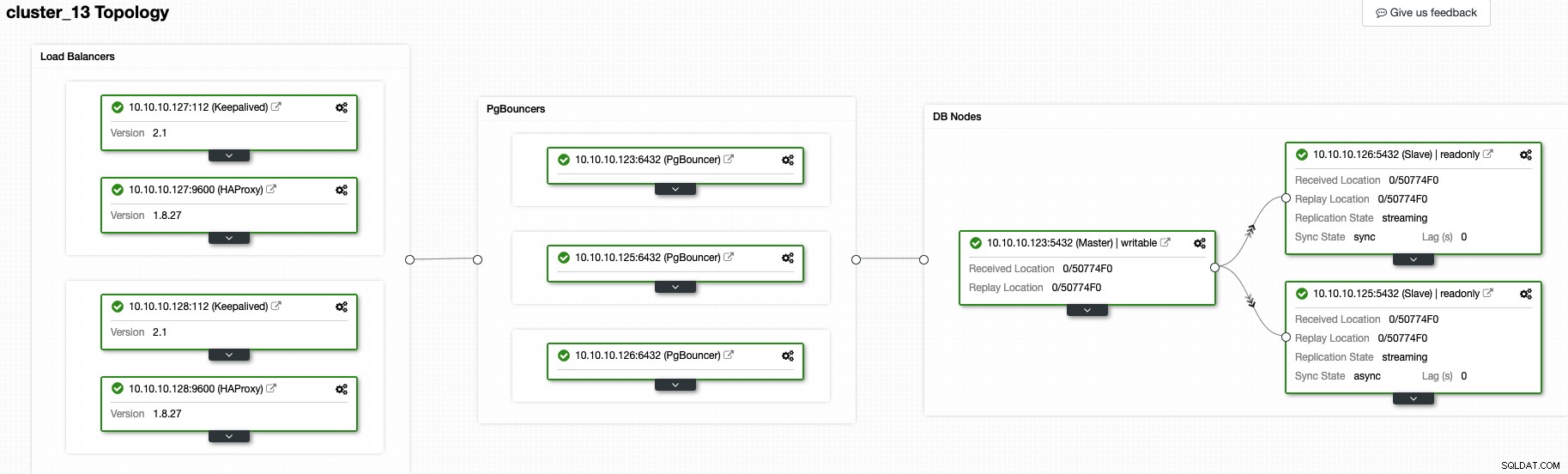
Et cela signifie :HAProxy + Keepalived -> PgBouncer -> nœuds de base de données PostgreSQL , c'est une bonne topologie pour votre cluster PostgreSQL.
Fonctionnalité de récupération automatique de ClusterControl
En cas d'échec, ClusterControl promouvra le nœud de secours le plus avancé en nœud principal et vous informera du problème. Il bascule également sur le reste du nœud de secours pour répliquer à partir du nouveau serveur principal.
Par défaut, HAProxy est configuré avec deux ports différents :lecture-écriture et lecture seule. Dans le port en lecture-écriture, vous avez votre nœud de base de données principal (ou PgBouncer) en ligne et le reste des nœuds en mode hors connexion, et dans le port en lecture seule, vous avez à la fois le nœud principal et le nœud de secours en ligne.
Lorsque HAProxy détecte qu'un de vos nœuds n'est pas accessible, il le marque automatiquement comme étant hors ligne et ne le prend pas en compte pour lui envoyer du trafic. La détection est effectuée par des scripts de vérification de l'état configurés par ClusterControl au moment du déploiement. Ceux-ci vérifient si les instances sont actives, si elles sont en cours de récupération ou sont en lecture seule.
Lorsque ClusterControl promeut un nœud de secours, HAProxy marque l'ancien nœud principal comme étant hors ligne pour les deux ports et met le nœud promu en ligne dans le port en lecture-écriture.
Si votre HAProxy actif, auquel est attribuée une adresse IP virtuelle à laquelle vos systèmes se connectent, échoue, Keepalived migre automatiquement cette adresse IP vers votre HAProxy passif. Cela signifie que vos systèmes peuvent alors continuer à fonctionner normalement.
Conclusion
Comme vous pouvez le constater, il est facile d'avoir une bonne topologie PostgreSQL si vous utilisez ClusterControl et si vous suivez les concepts de base des meilleures pratiques pour la réplication PostgreSQL. Bien sûr, le meilleur environnement dépend de la charge de travail, du matériel, de l'application, etc., mais vous pouvez l'utiliser comme exemple et déplacer les éléments selon vos besoins.



