J'ai commencé à écrire sur l'outil (pglupgrade) que j'ai développé pour effectuer des mises à niveau automatisées avec un temps d'arrêt proche de zéro des clusters PostgreSQL. Dans cet article, je parlerai de l'outil et discuterai de ses détails de conception.
Vous pouvez consulter la première partie de la série ici : Mises à niveau automatisées avec temps d'arrêt quasi nul des clusters PostgreSQL dans le cloud (Partie I).

L'outil est écrit en Ansible. J'ai une expérience antérieure de travail avec Ansible, et je travaille actuellement avec lui également dans 2ndQuadrant , c'est pourquoi c'était une option confortable pour moi. Cela étant dit, vous pouvez implémenter la logique de mise à niveau avec temps d'arrêt minimal, qui sera expliquée plus loin dans cet article, avec votre outil d'automatisation préféré.
Pour en savoir plus :articles de blog Ansible Loves PostgreSQL , PostgreSQL Planet in Ansible Galaxy et présentation Gestion de PostgreSQL avec Ansible.
Livret de mise à niveau de Pglupgrade
Dans Ansible, playbooks sont les principaux scripts développés pour automatiser les processus tels que le provisionnement des instances cloud et la mise à niveau des clusters de bases de données. Les playbooks peuvent contenir un ou plusieurs plays . Les playbooks peuvent également contenir des variables , rôles , et gestionnaires si défini.
L'outil se compose de deux playbooks principaux. Le premier playbook est provision.yml qui automatise le processus de création de machines Linux dans le cloud, conformément aux spécifications (Il s'agit d'un playbook facultatif écrit uniquement pour provisionner les instances cloud et non directement lié à la mise à niveau ). Le deuxième (et le principal) playbook est pglupgrade.yml qui automatise le processus de mise à niveau des clusters de bases de données.
Le playbook de Pglupgrade a huit jeux pour orchestrer la mise à niveau. Chacune des parties, utilisez un fichier de configuration (config.yml ), effectuer certaines tâches sur les hôtes ou les groupes d'hôtes qui sont définis dans le fichier d'inventaire de l'hôte (host.ini ).
Fichier d'inventaire
Un fichier d'inventaire permet à Ansible de savoir de quels serveurs il a besoin pour se connecter à l'aide de SSH, de quelles informations de connexion il a besoin et éventuellement quelles variables sont associées à ces serveurs. Ci-dessous, vous pouvez voir un exemple de fichier d'inventaire, qui a été utilisé pour exécuter des mises à niveau de cluster automatisées pour l'une des études de cas conçues pour l'outil. Nous discuterons de ces études de cas dans les prochains articles de cette série.
[old-primary] 54.171.211.188 [new-primary] 54.246.183.100 [old-standbys] 54.77.249.81 54.154.49.180 [new-standbys:children] old-standbys [pgbouncer] 54.154.49.180
Fichier d'inventaire (host.ini )
L'exemple de fichier d'inventaire contient cinq hôtes moins de cinq groupes d'accueil qui incluent old-primary , new-primary , old-standbys , new-standbys et pgbouncer . Un serveur peut appartenir à plusieurs groupes. Par exemple, les old-standbys est un groupe contenant les new-standbys groupe, c'est-à-dire les hôtes qui sont définis sous le old-standbys groupe (54.77.249.81 et 54.154.49.180) appartient également au groupe new-standbys grouper. En d'autres termes, les new-standbys le groupe est hérité des (enfants de) old-standbys grouper. Ceci est réalisé en utilisant le spécial :children suffixe.
Une fois le fichier d'inventaire prêt, Ansible playbook peut s'exécuter via ansible-playbook en pointant vers le fichier d'inventaire (si le fichier d'inventaire ne se trouve pas à l'emplacement par défaut, sinon il utilisera le fichier d'inventaire par défaut) comme indiqué ci-dessous :
$ ansible-playbook -i hosts.ini pglupgrade.yml
Exécuter un playbook Ansible
Fichier de configuration
Le playbook de Pglupgrade utilise un fichier de configuration (config.yml ) qui permet aux utilisateurs de spécifier des valeurs pour les variables de mise à niveau logique.
Comme indiqué ci-dessous, le config.yml stocke principalement des variables spécifiques à PostgreSQL qui sont nécessaires pour configurer un cluster PostgreSQL, telles que postgres_old_datadir et postgres_new_datadir pour stocker le chemin du répertoire de données PostgreSQL pour les anciennes et nouvelles versions de PostgreSQL ; postgres_new_confdir pour stocker le chemin du répertoire de configuration de PostgreSQL pour la nouvelle version de PostgreSQL ; postgres_old_dsn et postgres_new_dsn pour stocker la chaîne de connexion pour le pglupgrade_user pouvoir se connecter à la pglupgrade_database du nouveau et de l'ancien serveur principal. La chaîne de connexion elle-même est composée des variables configurables afin que l'utilisateur (pglupgrade_user ) et la base de données (pglupgrade_database ) les informations peuvent être modifiées pour les différents cas d'utilisation.
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main" Fichier de configuration (config.yml )
En tant qu'étape clé de toute mise à niveau, les informations de version de PostgreSQL peuvent être spécifiées pour la version actuelle (postgres_old_version ) et la version qui sera mise à jour (postgres_new_version ). Contrairement à la réplication physique où la réplication est une copie du système au niveau octet/bloc, la réplication logique permet la réplication sélective où la réplication peut copier les données logiques, y compris les bases de données spécifiées et les tables de ces bases de données. Pour cette raison, config.yml permet de configurer quelle base de données répliquer via pglupgrade_database variable. De plus, l'utilisateur de réplication logique doit avoir des privilèges de réplication, c'est pourquoi pglupgrade_user La variable doit être spécifiée dans le fichier de configuration. Il existe d'autres variables liées au fonctionnement interne de pglogical telles que subscription_name et replication_set qui sont utilisés dans le rôle pglogical.
Conception haute disponibilité de l'outil Pglupgrade
L'outil Pglupgrade est conçu pour donner à l'utilisateur la flexibilité en termes de propriétés de haute disponibilité (HA) pour les différentes exigences du système. Les initial_standbys variable (voir config.yml ) est la clé permettant de désigner les propriétés HA du cluster pendant l'opération de mise à niveau.
Par exemple, si initial_standbys est défini sur 1 (peut être défini sur n'importe quel nombre autorisé par la capacité du cluster), cela signifie qu'un serveur de secours sera créé dans le cluster mis à niveau avec le maître avant le démarrage de la réplication. En d'autres termes, si vous avez 4 serveurs et que vous définissez initial_standbys sur 1, vous aurez 1 serveur principal et 1 serveur de secours dans la nouvelle version mise à niveau, ainsi que 1 serveur principal et 1 serveur de secours dans l'ancienne version.
Cette option permet de réutiliser les serveurs existants pendant que la mise à niveau est toujours en cours. Dans l'exemple de 4 serveurs, les anciens serveurs principal et de secours peuvent être reconstruits en 2 nouveaux serveurs de secours une fois la réplication terminée.
Lorsque initial_standbys est définie sur 0, aucun serveur de secours initial ne sera créé dans le nouveau cluster avant le démarrage de la réplication.
Si le initial_standbys la configuration semble déroutante, ne vous inquiétez pas. Cela sera mieux expliqué dans le prochain article de blog lorsque nous discuterons de deux études de cas différentes.
Enfin, le fichier de configuration permet de spécifier les anciens et les nouveaux groupes de serveurs. Cela pourrait être fourni de deux manières. Tout d'abord, s'il existe un cluster existant, les adresses IP des serveurs (peuvent être des serveurs bare-metal ou virtuels ) doit être saisi dans hosts.ini fichier en tenant compte des propriétés HA souhaitées lors de l'opération de mise à niveau.
La deuxième façon consiste à exécuter provision.yml playbook (c'est ainsi que j'ai provisionné les instances cloud, mais vous pouvez utiliser vos propres scripts de provisionnement ou provisionner manuellement les instances ) pour provisionner des serveurs Linux vides dans le cloud (instances AWS EC2) et obtenir les adresses IP des serveurs dans le hosts.ini dossier. Dans tous les cas, config.yml obtiendra des informations sur l'hôte via hosts.ini fichier.
Flux de travail du processus de mise à niveau
Après avoir expliqué le fichier de configuration (config.yml ) qui est utilisé par pglupgrade playbook, nous pouvons expliquer le flux de travail du processus de mise à niveau.
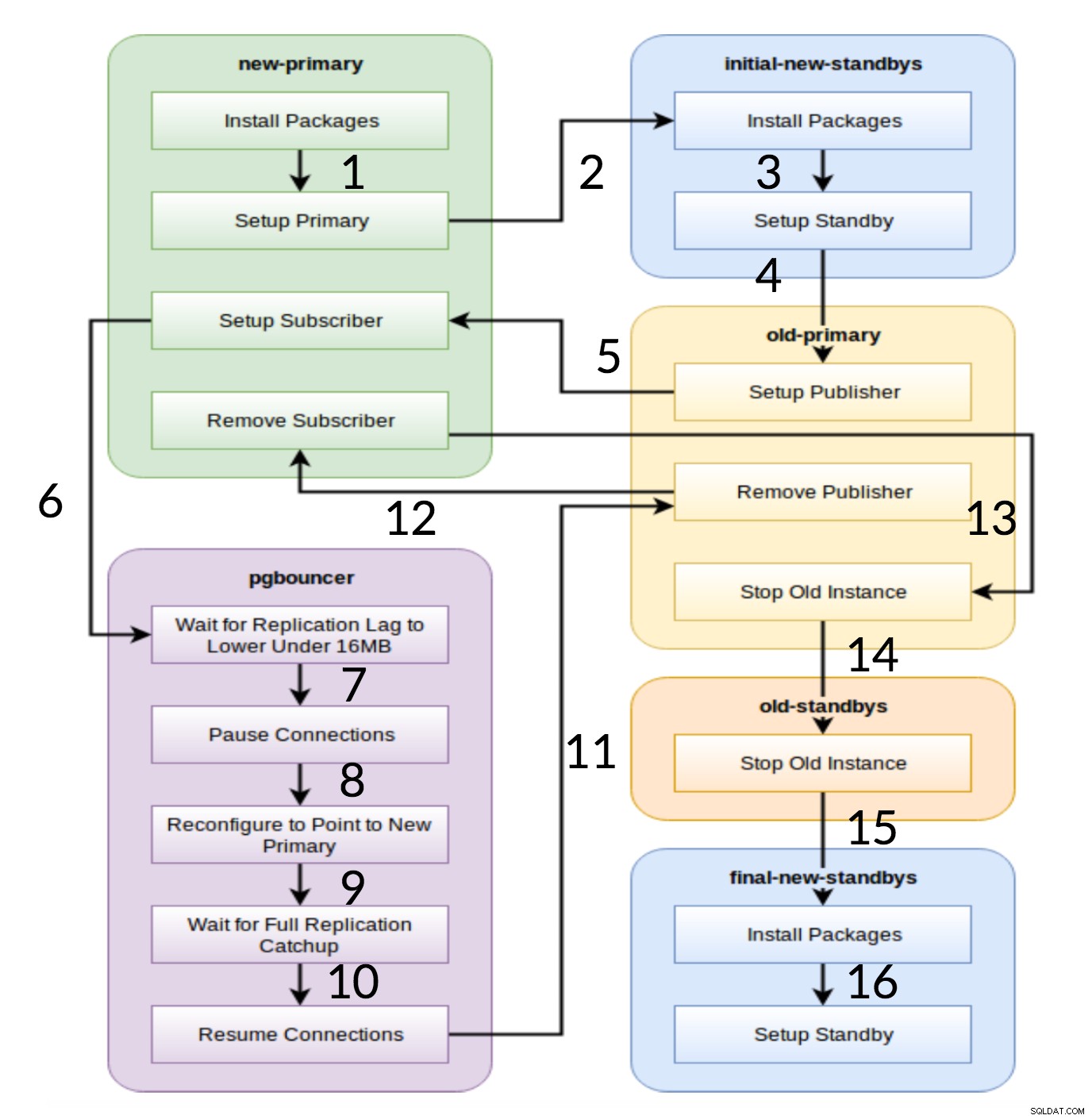
Flux de travail Pglupgrade
Comme le montre le diagramme ci-dessus, six groupes de serveurs sont générés au début en fonction de la configuration (à la fois hosts.ini et le config.yml ). Le new-primary et old-primary les groupes auront toujours un serveur, pgbouncer groupe peut avoir un ou plusieurs serveurs et tous les groupes de secours peuvent avoir zéro ou plusieurs serveurs en eux. En ce qui concerne la mise en œuvre, l'ensemble du processus est divisé en huit étapes. Chaque étape correspond à une lecture dans le playbook de pglupgrade, qui exécute les tâches requises sur les groupes d'hôtes affectés. Le processus de mise à niveau est expliqué à travers les parties suivantes :
- Créer des hôtes en fonction de la configuration : Jeu de préparation qui construit des groupes internes de serveurs en fonction de la configuration. Le résultat de cette lecture (en combinaison avec le
hosts.inicontenus) sont les six groupes de serveurs (illustrés par des couleurs différentes dans le diagramme de flux de travail) qui seront utilisés par les sept jeux suivants. - Configurer un nouveau cluster avec une/des veille(s) initiale(s) : Configure un cluster PostgreSQL vide avec le(s) nouveau(x) serveur(s) primaire(s) et initial(aux) (s'il y en a de définis). Il garantit qu'il ne reste aucune installation PostgreSQL de l'utilisation précédente.
- Modifiez l'ancien primaire pour prendre en charge la réplication logique : Installe l'extension pglogical. Définit ensuite l'éditeur en ajoutant toutes les tables et séquences à la réplication.
- Répliquer vers le nouveau primaire : Configure l'abonné sur le nouveau maître qui agit comme un déclencheur pour démarrer la réplication logique. Cette lecture termine la réplication des données existantes et commence à rattraper ce qui a changé depuis le début de la réplication.
- Basculez le pgbouncer (et les applications) vers le nouveau primaire : Lorsque le décalage de réplication converge vers zéro, met le pgbouncer en pause pour changer progressivement d'application. Ensuite, il pointe la configuration de pgbouncer vers le nouveau primaire et attend que la différence de réplication atteigne zéro. Enfin, pgbouncer est repris et toutes les transactions en attente sont propagées au nouveau primaire et y commencent le traitement. Les veilles initiales sont déjà utilisées et répondent aux demandes de lecture.
- Nettoyez la configuration de la réplication entre l'ancien principal et le nouveau principal : Met fin à la connexion entre l'ancien et le nouveau serveur principal. Étant donné que toutes les applications sont déplacées vers le nouveau serveur principal et que la mise à niveau est effectuée, la réplication logique n'est plus nécessaire. La réplication entre les serveurs principal et de secours se poursuit avec la réplication physique.
- Arrêtez l'ancien cluster : Le service Postgres est arrêté sur les anciens hôtes pour s'assurer qu'aucune application ne peut plus s'y connecter.
- Reconfigurez le reste des veilles pour le nouveau primaire : Reconstruit d'autres standbys s'il reste des hôtes autres que les standbys initiaux. Dans la deuxième étude de cas, il ne reste plus de serveurs de secours à reconstruire. Cette étape donne la possibilité de reconstruire l'ancien serveur principal en tant que nouveau serveur de secours s'il est pointé dans le groupe new-standbys sur hosts.ini. La réutilisabilité des serveurs existants (même l'ancien serveur principal) est obtenue en utilisant la conception de configuration de secours en deux étapes de l'outil pglupgrade. L'utilisateur peut spécifier quels serveurs doivent devenir des serveurs de secours du nouveau cluster avant la mise à niveau et lesquels doivent devenir des serveurs de secours après la mise à niveau.
Conclusion
Dans cet article, nous avons discuté des détails d'implémentation et de la conception à haute disponibilité de l'outil pglupgrade. Ce faisant, nous avons également mentionné quelques concepts clés du développement Ansible (c'est-à-dire le playbook, l'inventaire et les fichiers de configuration) en utilisant l'outil comme exemple. Nous avons illustré le flux de travail du processus de mise à niveau et résumé le fonctionnement de chaque étape avec un jeu correspondant. Nous continuerons à expliquer pglupgrade en montrant des études de cas dans les prochains posts de cette série.
Merci d'avoir lu !



