Il s'agit d'une utilisation classique d'une simple expression de table commune récursive (WITH RECURSIVE ), disponible dans PostgreSQL 8.4 et versions ultérieures.
Démonstration ici :https://sqlfiddle.com/#!12/78e15/9
Étant donné les exemples de données en SQL :
CREATE TABLE Table1
("ID1" text, "ID2" text)
;
INSERT INTO Table1
("ID1", "ID2")
VALUES
('vc1', 'vc2'),
('vc2', 'vc3'),
('vc3', 'vc4'),
('vc4', 'rc7')
;
Vous pourriez écrire :
WITH RECURSIVE chain(from_id, to_id) AS (
SELECT NULL, 'vc2'
UNION
SELECT c.to_id, t."ID2"
FROM chain c
LEFT OUTER JOIN Table1 t ON (t."ID1" = to_id)
WHERE c.to_id IS NOT NULL
)
SELECT from_id FROM chain WHERE to_id IS NULL;
Ce que cela fait, c'est parcourir la chaîne de manière itérative, en ajoutant chaque ligne à la chain table sous forme de pointeurs de départ et d'arrivée. Lorsqu'il rencontre une ligne pour laquelle la référence 'to' n'existe pas, il ajoute une référence 'to' nulle pour cette ligne. La prochaine itération remarquera que la référence "à" est nulle et ne produira aucune ligne, ce qui entraînera la fin de l'itération.
La requête externe sélectionne ensuite les lignes qui ont été déterminées comme étant la fin de la chaîne en ayant un to_id inexistant.
Il faut un peu d'effort pour comprendre les CTE récursifs. Les éléments clés à comprendre sont :
-
Ils commencent par la sortie d'une requête initiale, qu'ils unissent à plusieurs reprises avec la sortie de la "partie récursive" (la requête après le
UNIONouUNION ALL) jusqu'à ce que la partie récursive n'ajoute aucune ligne. Cela arrête l'itération. -
Ils ne sont pas vraiment récursifs, plus itératifs, bien qu'ils soient bons pour le genre de choses pour lesquelles vous pourriez utiliser la récursivité.
Donc, vous construisez essentiellement une table dans une boucle. Vous ne pouvez pas supprimer de lignes ni les modifier, mais uniquement en ajouter de nouvelles. Vous avez donc généralement besoin d'une requête externe qui filtre les résultats pour obtenir les lignes de résultats souhaitées. Vous ajouterez souvent des colonnes supplémentaires contenant des données intermédiaires que vous utilisez pour suivre l'état de l'itération, contrôler les conditions d'arrêt, etc.
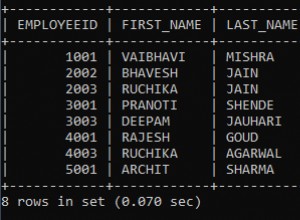
Il peut être utile de regarder le résultat non filtré. Si je remplace la requête récapitulative finale par une simple chaîne SELECT * FROM chain Je peux voir le tableau qui a été généré :
from_id | to_id
---------+-------
| vc2
vc2 | vc3
vc3 | vc4
vc4 | rc7
rc7 |
(5 rows)
La première ligne est la ligne de point de départ ajoutée manuellement, où vous spécifiez ce que vous voulez rechercher - dans ce cas, c'était vc2 . Chaque ligne suivante a été ajoutée par l'UNION ed terme récursif, qui fait un LEFT OUTER JOIN sur le résultat précédent et renvoie un nouvel ensemble de lignes qui associent le précédent to_id (maintenant dans le from_id colonne) au prochain to_id . Si le LEFT OUTER JOIN ne correspond pas alors au to_id sera nul, ce qui obligera la prochaine invocation à renvoyer maintenant des lignes et à terminer l'itération.
Parce que cette requête ne tente pas d'ajouter uniquement le dernier rangée à chaque fois, cela répète en fait pas mal de travail à chaque itération. Pour éviter cela, vous auriez besoin d'utiliser une approche plus proche de celle de Gordon, mais en plus de filtrer sur le champ de profondeur précédent lorsque vous avez scanné la table d'entrée, de sorte que vous n'ayez joint que la ligne la plus récente. En pratique, cela n'est généralement pas nécessaire, mais cela peut être un problème pour les très grands ensembles de données ou lorsque vous ne pouvez pas créer d'index appropriés.
Pour en savoir plus, consultez la documentation PostgreSQL sur les CTE.