Comme vous l'avez peut-être remarqué dans mon blog précédent, les derniers mois ont été consacrés à la mise à jour de Postgres-XL avec la dernière version 9.5 de PostgreSQL. Une fois que nous avons eu une version raisonnablement stable de Postgres-XL 9.5, nous avons porté notre attention sur la mesure des performances de cette toute nouvelle version de Postgres-XL. Notre choix de la référence est largement influencé par les travaux en cours sur le projet AXLE, financé par l'Union européenne dans le cadre de la convention de subvention 318633. Étant donné que nous utilisons TPC BENCHMARK™ H pour mesurer les performances de tous les autres travaux effectués dans le cadre de ce projet, nous avons décidé de utilisez le même benchmark pour évaluer Postgres-XL. Cela convient également à Postgres-XL car TPC-H essaie de mesurer les charges de travail OLAP, ce que Postgres-XL devrait bien faire.
1. Configuration du cluster Postgres-XL
Une fois le benchmark décidé, un autre grand défi consistait à trouver les bonnes ressources pour les tests. Nous n'avions pas accès à un grand groupe de machines physiques. Nous avons donc fait ce que la plupart feraient. Nous avons décidé d'utiliser Amazon AWS pour configurer le cluster Postgres-XL. AWS propose une large gamme d'instances, chaque type d'instance offrant une puissance de calcul ou d'E/S différente.
Cette page sur AWS présente les différents types d'instances disponibles, les ressources disponibles et leur tarification pour différentes régions. Il convient de noter que les prix et la disponibilité peuvent varier d'une région à l'autre, il est donc important que vous vérifiiez toutes les régions. Étant donné que Postgres-XL nécessite une faible latence et un débit élevé entre ses composants, il est également important d'instancier toutes les instances dans la même région. Pour notre TPC-H de 3 To, nous avons décidé d'opter pour un cluster de 16 nœuds de données d'instances AWS i2.xlarge. Ces instances ont 4 vCPU, 30 Go de RAM et 800 Go de SSD chacune, un stockage suffisant pour conserver toutes les tables distribuées, les tables répliquées (qui prennent plus d'espace avec l'augmentation de la taille du cluster), les index sur celles-ci tout en laissant suffisamment d'espace libre dans un tablespace temporaire pour CREATE INDEX et d'autres requêtes.
2. Configuration de l'analyse comparative
2.1 TPC Benchmark™ H
Le benchmark contient 22 requêtes dans le but d'examiner de grands volumes de données, d'exécuter des requêtes avec un degré élevé de complexité et de donner des réponses aux questions critiques de l'entreprise. Nous tenons à souligner que la spécification complète TPC Benchmark™ H traite d'une variété de tests tels que la charge, la puissance et le débit essais. Pour nos tests, nous n'avons exécuté que des requêtes individuelles et non la suite de tests complète. TPC Benchmark™ H est composé d'un ensemble de requêtes métier conçues pour exercer les fonctionnalités du système d'une manière représentative des applications d'analyse métier complexes. Ces requêtes ont été placées dans un contexte réaliste, décrivant l'activité d'un fournisseur grossiste pour aider le lecteur à se rapporter intuitivement aux composants du benchmark.
2.2 Entités, relations et caractéristiques de la base de données
Les composants de la base de données TPC-H sont définis comme étant constitués de huit tables distinctes et individuelles (les tables de base). Les relations entre les colonnes de ces tableaux sont illustrées dans le schéma suivant. 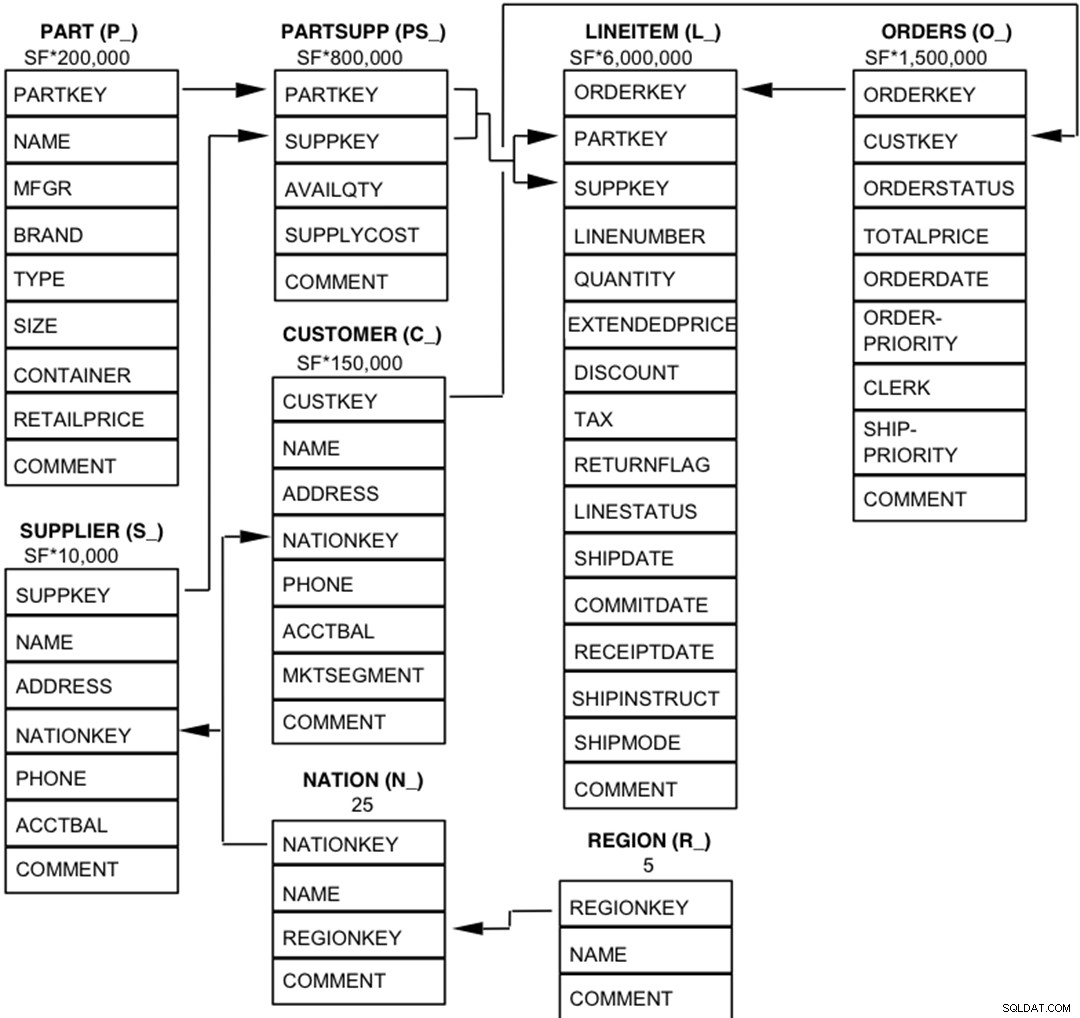 Légende :
Légende :
- Les parenthèses suivant chaque nom de table contiennent le préfixe des noms de colonne pour cette table ;
- Les flèches pointent dans la direction des relations un-à-plusieurs entre les tables
- Le nombre/la formule sous chaque nom de table représente la cardinalité (nombre de lignes) de la table. Certains sont factorisés par SF, le facteur d'échelle, pour obtenir la taille de base de données choisie. La cardinalité de la table LINEITEM est approximative
2.3 Distribution des données pour Postgres-XL
Nous avons analysé les 22 requêtes du benchmark et avons proposé la stratégie de distribution de données suivante pour différentes tables du benchmark.
| Nom de la table | Stratégie de distribution |
| ÉLÉMENT DE LIGNE | HAS (l_orderkey) |
| COMMANDES | HAS (o_orderkey) |
| PARTIE | HAS (p_partkey) |
| PARTSUPP | HAS (ps_partkey) |
| CLIENT | REPLICATE |
| FOURNISSEUR | REPLICATE |
| NATION | REPLICATE |
| RÉGION | REPLICATE |
Notez que LINEITEM et ORDERS qui sont les plus grandes tables du benchmark sont souvent jointes sur ORDERKEY. Il est donc très logique de colocaliser ces tables sur ORDERKEY. De même, PART et PARTSUPP sont fréquemment joints sur PARTKEY et sont donc colocalisés sur la colonne PARTKEY. Le reste des tables est répliqué pour s'assurer qu'elles peuvent être jointes localement, si nécessaire.
3. Résultats de référence
3.1 Test de charge
Nous avons comparé les résultats obtenus en exécutant un test de charge TPC-H de 3 To sur PostgreSQL 9.6 avec le cluster Postgres-XL à 16 nœuds. Les tableaux suivants illustrent les caractéristiques de performance de Postgres-XL.
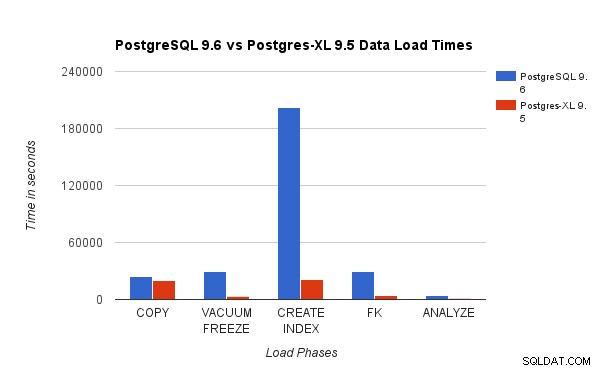 Le graphique ci-dessus montre le temps nécessaire pour terminer les différentes phases d'un test de charge avec PostgreSQL et Postgres-XL. Comme on le voit, Postgres-XL fonctionne légèrement mieux pour COPY et fait beaucoup mieux pour tous les autres cas. Remarque :Nous avons observé que le coordinateur nécessite beaucoup de puissance de calcul pendant la phase COPY, en particulier lorsque plusieurs flux COPY s'exécutent simultanément. Pour résoudre ce problème, le coordinateur a été exécuté sur une instance AWS optimisée pour le calcul avec 16 vCPU. Alternativement, nous aurions pu également exécuter plusieurs coordinateurs et répartir la charge de calcul entre eux.
Le graphique ci-dessus montre le temps nécessaire pour terminer les différentes phases d'un test de charge avec PostgreSQL et Postgres-XL. Comme on le voit, Postgres-XL fonctionne légèrement mieux pour COPY et fait beaucoup mieux pour tous les autres cas. Remarque :Nous avons observé que le coordinateur nécessite beaucoup de puissance de calcul pendant la phase COPY, en particulier lorsque plusieurs flux COPY s'exécutent simultanément. Pour résoudre ce problème, le coordinateur a été exécuté sur une instance AWS optimisée pour le calcul avec 16 vCPU. Alternativement, nous aurions pu également exécuter plusieurs coordinateurs et répartir la charge de calcul entre eux.
3.2 Test de puissance
Nous avons également comparé les temps d'exécution des requêtes pour le benchmark 3 To sur PostgreSQL 9.6 et Postgres-XL 9.5. Le graphique suivant montre les caractéristiques de performance de l'exécution de la requête sur les deux configurations.
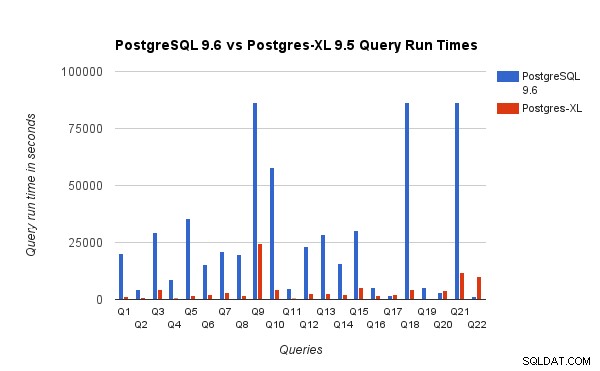 Nous avons observé qu'en moyenne, les requêtes s'exécutaient environ 6,4 fois plus rapidement sur Postgres-XL et qu'au moins 25 % des requêtes ont montré une amélioration presque linéaire des performances, en d'autres termes, ils ont fonctionné près de 16 fois plus vite sur ce cluster Postgres-XL à 16 nœuds. De plus, au moins 50 % des requêtes ont montré une amélioration de 10 fois des performances. Nous avons ensuite analysé les performances des requêtes et conclu que les requêtes qui sont bien partitionnées sur tous les nœuds de données disponibles, de sorte qu'il y a un échange minimal de données entre les nœuds et sans appels d'exécution à distance répétés, évoluent très bien dans Postgres-XL. De telles requêtes ont généralement un nœud Remote Subquery Scan en haut et la sous-arborescence sous le nœud est exécutée sur un ou plusieurs nœuds en parallèle. Il est également courant d'avoir d'autres nœuds tels qu'un nœud Limit ou un nœud Aggregate au-dessus du nœud Remote Subquery Scan. Même de telles requêtes fonctionnent très bien sur Postgres-XL. La requête Q1 est un exemple de requête qui devrait très bien évoluer avec Postgres-XL. D'autre part, les requêtes qui nécessitent de nombreux échanges de tuples entre datanode-datanode et/ou coordinateur-datanode peuvent ne pas fonctionner correctement dans Postgres-XL. De même, les requêtes qui nécessitent de nombreuses connexions inter-nœuds peuvent également afficher des performances médiocres. Par exemple, vous remarquerez que les performances de Q22 sont mauvaises par rapport à un serveur PostgreSQL à nœud unique. Lorsque nous avons analysé le plan de requête pour Q22, nous avons observé qu'il existe trois niveaux de nœuds Remote Subquery Scan imbriqués dans le plan de requête, où chaque nœud ouvre un nombre égal de connexions aux nœuds de données. De plus, Nest Loop Anti Join a une relation interne avec un nœud Remote Subquery Scan de niveau supérieur et, par conséquent, pour chaque tuple de la relation externe, il doit exécuter une sous-requête distante. Cela se traduit par de mauvaises performances d'exécution de la requête.
Nous avons observé qu'en moyenne, les requêtes s'exécutaient environ 6,4 fois plus rapidement sur Postgres-XL et qu'au moins 25 % des requêtes ont montré une amélioration presque linéaire des performances, en d'autres termes, ils ont fonctionné près de 16 fois plus vite sur ce cluster Postgres-XL à 16 nœuds. De plus, au moins 50 % des requêtes ont montré une amélioration de 10 fois des performances. Nous avons ensuite analysé les performances des requêtes et conclu que les requêtes qui sont bien partitionnées sur tous les nœuds de données disponibles, de sorte qu'il y a un échange minimal de données entre les nœuds et sans appels d'exécution à distance répétés, évoluent très bien dans Postgres-XL. De telles requêtes ont généralement un nœud Remote Subquery Scan en haut et la sous-arborescence sous le nœud est exécutée sur un ou plusieurs nœuds en parallèle. Il est également courant d'avoir d'autres nœuds tels qu'un nœud Limit ou un nœud Aggregate au-dessus du nœud Remote Subquery Scan. Même de telles requêtes fonctionnent très bien sur Postgres-XL. La requête Q1 est un exemple de requête qui devrait très bien évoluer avec Postgres-XL. D'autre part, les requêtes qui nécessitent de nombreux échanges de tuples entre datanode-datanode et/ou coordinateur-datanode peuvent ne pas fonctionner correctement dans Postgres-XL. De même, les requêtes qui nécessitent de nombreuses connexions inter-nœuds peuvent également afficher des performances médiocres. Par exemple, vous remarquerez que les performances de Q22 sont mauvaises par rapport à un serveur PostgreSQL à nœud unique. Lorsque nous avons analysé le plan de requête pour Q22, nous avons observé qu'il existe trois niveaux de nœuds Remote Subquery Scan imbriqués dans le plan de requête, où chaque nœud ouvre un nombre égal de connexions aux nœuds de données. De plus, Nest Loop Anti Join a une relation interne avec un nœud Remote Subquery Scan de niveau supérieur et, par conséquent, pour chaque tuple de la relation externe, il doit exécuter une sous-requête distante. Cela se traduit par de mauvaises performances d'exécution de la requête.
4. Quelques leçons AWS
Lors de l'analyse comparative de Postgres-XL, nous avons appris quelques leçons sur l'utilisation d'AWS. Nous avons pensé qu'ils seraient utiles à tous ceux qui cherchent à utiliser/tester Postgres-XL sur AWS.
- AWS propose plusieurs types d'instances différents. Vous devez évaluer soigneusement votre charge de travail et la quantité de stockage requise avant de choisir un type d'instance spécifique.
- La plupart des instances à stockage optimisé sont associées à des disques éphémères. Vous n'avez rien à payer de plus pour ces disques, ils sont attachés à l'instance et fonctionnent souvent mieux qu'EBS. Mais vous devez les monter explicitement pour pouvoir les utiliser. Gardez cependant à l'esprit que les données stockées sur ces disques ne sont pas permanentes et seront effacées si l'instance est arrêtée. Assurez-vous donc que vous êtes prêt à gérer cette situation. Comme nous utilisions AWS principalement pour l'analyse comparative, nous avons décidé d'utiliser ces disques éphémères.
- Si vous utilisez EBS, assurez-vous de choisir les IOPS provisionnées appropriées. Une valeur trop faible entraînera des E/S très lentes, mais une valeur très élevée peut augmenter considérablement votre facture AWS, en particulier lorsqu'il s'agit d'un grand nombre de nœuds.
- Assurez-vous de démarrer les instances dans la même zone pour réduire la latence et améliorer le débit des connexions entre elles.
- Assurez-vous de configurer les instances afin qu'elles utilisent un réseau privé pour communiquer entre elles.
- Regardez les instances ponctuelles. Ils sont relativement moins chers. Étant donné qu'AWS peut résilier des instances ponctuelles à volonté, par exemple, si le prix ponctuel devient supérieur à votre prix d'enchère maximum, préparez-vous à cela. Postgres-XL peut devenir partiellement ou complètement inutilisable selon les nœuds terminés. AWS prend en charge un concept de launch_group. Si plusieurs instances sont regroupées dans le même launch_group, si AWS décide de résilier une instance, toutes les instances seront résiliées.
5. Conclusion
Nous sommes en mesure de montrer, à travers divers benchmarks, que Postgres-XL peut très bien évoluer pour un large éventail de requêtes complexes du monde réel. Ces benchmarks nous aident à démontrer la capacité de Postgres-XL en tant que solution efficace pour les charges de travail OLAP. Nos expériences montrent également qu'il existe des problèmes de performances avec Postgres-XL, en particulier pour les très grands clusters et lorsque le planificateur fait un mauvais choix de plan. Nous avons également observé que lorsqu'il y a un très grand nombre de connexions simultanées à un datanode, les performances se dégradent. Nous continuerons à travailler sur ces problèmes de performances. Nous aimerions également tester la capacité de Postgres-XL en tant que solution OLTP en utilisant des charges de travail appropriées.