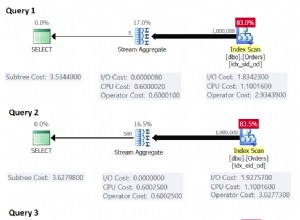
J'ai également rencontré ce problème. Cela revient essentiellement à avoir un nombre variable de valeurs dans votre clause IN et Hibernate essayant de mettre en cache ces plans de requête.
Il existe deux excellents articles de blog sur ce sujet. Le premier :
Utiliser Hibernate 4.2 et MySQL dans un projet avec une requête in-clause comme :
select t from Thing t where t.id in (?)Hibernate met en cache ces requêtes HQL analysées. Spécifiquement Hibernate
SessionFactoryImplaQueryPlanCacheavecqueryPlanCacheetparameterMetadataCache. Mais cela s'est avéré être un problème lorsque le nombre de paramètres pour l'in-clause est important et varie.Ces caches augmentent pour chaque requête distincte. Donc cette requête avec 6000paramètres n'est pas la même que 6001.
La requête dans la clause est étendue au nombre de paramètres dans la collection. Les métadonnées sont incluses dans le plan de requête pour chaque paramètre de la requête, y compris un nom généré comme x10_, x11_ , etc.
Imaginez 4 000 variations différentes du nombre de paramètres dans la clause, chacun d'eux avec une moyenne de 4 000 paramètres. Les métadonnées de requête pour chaque paramètre s'additionnent rapidement en mémoire, remplissant le tas, car elles ne peuvent pas être ramassées.
Cela continue jusqu'à ce que toutes les différentes variations du nombre de paramètres de requête soient mises en cache ou que la JVM manque de mémoire de tas et commence à lancerjava.lang.OutOfMemoryError :Java heap space.
Éviter les in-clauses est une option, ainsi que l'utilisation d'une taille de collection fixe pour le paramètre (ou au moins une taille plus petite).
Pour configurer la taille maximale du cache du plan de requête, consultez la propriété
hibernate.query.plan_cache_max_size, par défaut à2048(facilement trop volumineux pour les requêtes avec de nombreux paramètres).
Et deuxième (également référencé depuis le premier) :
Hibernate utilise en interne un cache qui mappe les instructions HQL (asstrings) aux plans de requête. Le cache est constitué d'une carte délimitée limitée par défaut à 2048 éléments (configurable). Toutes les requêtes HQL sont chargées via ce cache. En cas d'échec, l'entrée est automatiquement ajoutée au cache. Cela le rend très sensible au thrashing - scénario dans lequel nous mettons constamment de nouvelles entrées dans le cache sans jamais les réutiliser et empêchant ainsi le cache d'apporter des gains de performances (cela ajoute même une surcharge de gestion du cache). Pour aggraver les choses, il est difficile de détecter cette situation par hasard - vous devez explicitement profiler le cache afin de remarquer que vous avez un problème à cet endroit. Je dirai quelques mots sur la façon dont cela pourrait être fait plus tard.
Ainsi, la suppression du cache résulte de la génération de nouvelles requêtes à des taux élevés. Cela peut être causé par une multitude de problèmes. Les deux plus courants que j'ai vus sont - les bogues dans hibernate qui provoquent le rendu des paramètres dans l'instruction JPQL au lieu d'être passés en tant que paramètres et l'utilisation d'une clause "in".
En raison de quelques bogues obscurs dans hibernate, il existe des situations où les paramètres ne sont pas gérés correctement et sont rendus dans la requête JPQL (par exemple, consultez HHH-6280). Si vous avez une requête qui est affectée par de tels défauts et qu'elle est exécutée à des cadences élevées, cela va vider le cache de votre plan de requête car chaque requête JPQL générée est presque unique (contenant les ID de vos entités par exemple).
Le deuxième problème réside dans la manière dont hibernate traite les requêtes avec une clause "in" (par exemple, donnez-moi toutes les entités de personne dont l'identifiant de société est l'un des 1, 2, 10, 18). Pour chaque nombre distinct de paramètres dans la clause "in", hibernate produira une requête différente - par exemple,
select x from Person x where x.company.id in (:id0_)pour 1 paramètre,select x from Person x where x.company.id in (:id0_, :id1_)pour 2 paramètres et ainsi de suite. Toutes ces requêtes sont considérées comme différentes, en ce qui concerne le cache du plan de requête, ce qui entraîne à nouveau un cachethrashing. Vous pourriez probablement contourner ce problème en écrivant une classe d'utilité pour ne produire qu'un certain nombre de paramètres - par ex. 1,10, 100, 200, 500, 1000. Si, par exemple, vous passez 22 paramètres, il renverra une liste de 100 éléments avec les 22 paramètres inclus init et les 78 paramètres restants réglés sur une valeur impossible (par exemple -1 pour les ID utilisé pour les clés étrangères). Je suis d'accord qu'il s'agit d'un vilain hack, mais il pourrait faire le travail. Par conséquent, vous n'aurez au maximum que 6 requêtes uniques dans votre cache, ce qui réduira le thrashing.Alors, comment savez-vous que vous avez le problème? Vous pouvez écrire du code supplémentaire et exposer des métriques avec le nombre d'entrées dans le cache, par exemple. sur JMX, régler la journalisation et analyser les journaux, etc. Si vous ne voulez pas (ou ne pouvez pas) modifier l'application, vous pouvez simplement vider le tas et exécuter cette requête OQL dessus (par exemple en utilisant mat) :
SELECT l.query.toString() FROM INSTANCEOF org.hibernate.engine.query.spi.QueryPlanCache$HQLQueryPlanKey l. Il affichera toutes les requêtes actuellement situées dans n'importe quel cache de plan de requête sur votre tas. Il devrait être assez facile de déterminer si vous êtes affecté par l'un des problèmes susmentionnés.En ce qui concerne l'impact sur les performances, il est difficile de dire car cela dépend de trop de facteurs. J'ai vu une requête très triviale entraînant une surcharge de 10 à 20 msof pour la création d'un nouveau plan de requête HQL. En général, s'il y a une cache quelque part, il doit y avoir une bonne raison à cela - un raté coûte probablement cher, vous devriez donc essayer d'éviter les ratés autant que possible. Enfin, votre base de données devra également gérer de grandes quantités d'instructions SQL uniques, ce qui l'obligera à les analyser et peut-être à créer différents plans d'exécution pour chacune d'entre elles.