- Oui,
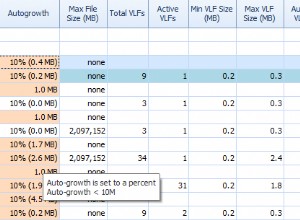
@BatchSizeest destiné à être utilisé avec des associations paresseuses. - Hibernate exécutera de toute façon plusieurs instructions dans la plupart des situations, même si le nombre de proxys/collections non initialisés est inférieur à la taille de lot spécifiée. Voir cette réponse pour plus de détails. En outre, des requêtes plus légères par rapport à des requêtes moins volumineuses peuvent contribuer positivement au débit global du système.
@BatchSizeau niveau de la classe signifie que la taille de lot spécifiée pour l'entité sera appliquée pour tous les@*ToOneassociations paresseuses avec cette entité. Voir l'exemple avec laPersonentité dans la documentation.
Les questions/réponses liées que vous avez fournies sont plus préoccupées par le besoin d'optimisation et de chargement paresseux en général. Ils s'appliquent ici aussi bien sûr, mais ils ne concernent pas uniquement le chargement par lots, qui n'est qu'une des approches possibles.
Une autre chose importante concerne le chargement hâtif qui est mentionné dans les réponses liées et qui suggère que si une propriété est toujours utilisée, vous pouvez obtenir de meilleures performances en utilisant le chargement hâtif. Ce n'est généralement pas vrai pour les collections et dans de nombreuses situations pour les associations à un non plus.
Par exemple, supposons que vous ayez l'entité suivante pour laquelle bs et cs sont toujours utilisé lorsque A est utilisé.
public class A {
@OneToMany
private Collection<B> bs;
@OneToMany
private Collection<C> cs;
}
Chargement bs avec impatience et cs souffre évidemment du problème de sélection N + 1 si vous ne les rejoignez pas dans une seule requête. Mais si vous les joignez dans une seule requête, par exemple :
select a from A
left join fetch a.bs
left join fetch a.cs
puis vous créez un produit cartésien complet entre bs et cs et retour count(a.bs) x count(a.cs) lignes dans le jeu de résultats pour chaque a qui sont lus un par un et assemblés dans les entités de A et leurs collections de bs et cs .
La récupération par lots serait très optimale dans cette situation, car vous devriez d'abord lire A s, puis bs puis cs , ce qui entraîne davantage de requêtes, mais avec beaucoup moins de données transférées depuis la base de données. De plus, les requêtes séparées sont beaucoup plus simples qu'une grande avec des jointures et sont plus faciles à exécuter et à optimiser pour la base de données.