
Qu'est-ce que Couchbase
Couchbase Server est une base de données de documents JSON open source et distribuée. Il expose un magasin clé-valeur évolutif avec un cache géré pour les opérations de données inférieures à la milliseconde, des indexeurs spécialement conçus pour des requêtes efficaces et un moteur de requête puissant pour l'exécution de requêtes de type SQL. Pour les environnements mobiles et Internet des objets, Couchbase s'exécute également de manière native sur l'appareil et gère la synchronisation avec le serveur.
Pourquoi Couchbase ?
Couchbase Server est une base de données de documents JSON open source et distribuée. Il expose un magasin clé-valeur évolutif avec un cache géré pour les opérations de données inférieures à la milliseconde, des indexeurs spécialement conçus pour des requêtes efficaces et un moteur de requête puissant pour l'exécution de requêtes de type SQL. Pour les environnements mobiles et Internet des objets, Couchbase s'exécute également de manière native sur l'appareil et gère la synchronisation avec le serveur.
Couchbase Server est spécialisé dans la gestion des données à faible latence pour les applications Web, mobiles et IoT interactives à grande échelle. Les exigences courantes auxquelles Couchbase Server a été conçu pour satisfaire incluent :
- Interface de programmation unifiée
- Requête
- Rechercher
- Mobile et IdO
- Analytique
- Moteur de base de données principal
- Architecture évolutive
- Architecture axée sur la mémoire
- Intégrations Big Data et SQL
- Sécurité complète
- Déploiements de conteneurs et de cloud
- Haute disponibilité
De nombreuses bases de données sont capables de satisfaire une ou plusieurs de ces exigences, mais nécessitent des compromis lors de l'exécution en production avec des applications critiques à l'échelle d'Internet. Par exemple, une solution peut offrir la flexibilité du modèle de données, mais peut ne pas avoir la capacité d'ajouter ou de supprimer des nœuds sans impact sur la disponibilité ou les performances. Une autre solution pourrait démontrer une bonne évolutivité en écriture sans pouvoir indexer ou modifier le modèle de données à la volée. Couchbase Server est conçu pour offrir une expérience de développement et d'administration productive tout en offrant des performances à grande échelle, que ce soit dans le cloud, dans un conteneur, sur site ou sur un appareil périphérique.
Indice de référence des performances Nosql
Une nouvelle référence comparant MongoDB, DataStax et Couchbase Server démontre que Couchbase est la base de données NoSQL la plus évolutive et la plus performante.
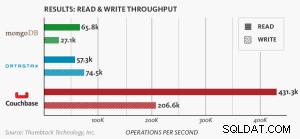
Besoin de référence basé sur les nœuds .
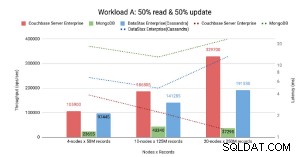
Selon le théorème CAP Couchbase .
Théorème de Cap

Couchbase est sur le schéma CP et AP.
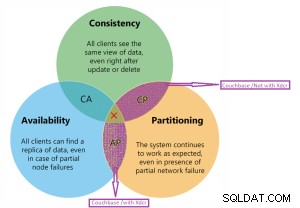
Détail du schéma Couchbase CP et AP.
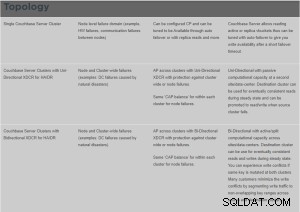
Qu'est-ce que XDCR ?
Cross Data Center Replication (XDCR) réplique les données entre les clusters :cela offre une protection contre les défaillances du centre de données et fournit également un accès aux données hautes performances pour les applications critiques distribuées dans le monde entier.
XDCR réplique les données d'un compartiment spécifique sur le cluster source vers un compartiment spécifique sur le cluster cible. Les données du compartiment source sont poussées vers le compartiment cible au moyen d'un agent XDCR, exécuté sur le cluster source, à l'aide du protocole de changement de base de données. N'importe quel bucket (Couchbase ou Ephemeral) sur n'importe quel cluster peut être spécifié comme source ou cible pour une ou plusieurs définitions XDCR.
Une description complète de l'architecture de XDCR est fournie dans Cross Data Center Replication (XDCR). Vous souhaiterez peut-être vous familiariser avec les informations qui y sont fournies avant d'effectuer les routines fournies dans cette section.
Structure de base Xdcr ;
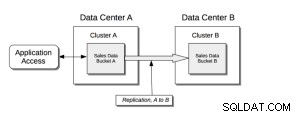
Pré-requis;
- Confirmez que votre cluster est correctement dimensionné et qu'il est capable de gérer de nouveaux flux XDCR. Par exemple, XDCR a besoin de 1 à 2 cœurs de processeur supplémentaires par flux et, dans certains cas, il nécessitera également plus de RAM et de ressources réseau. Si un cluster n'est pas correctement dimensionné pour la charge de travail existante plus les nouveaux flux XDCR, XDCR peut entrer en concurrence pour les ressources du serveur et avoir un impact négatif sur les performances globales.
- Couchbase Server utilise le port TCP/IP 8091 pour échanger les informations de configuration du cluster. Si vous communiquez avec un cluster de destination via une connexion dédiée ou Internet, vous devez vous assurer que tous les nœuds des clusters de destination et source peuvent communiquer entre eux via les ports 8091 et 8092.
Ports répertoriés par chemin de communication
| XDCR (cluster à cluster) |
|
Couchbase stocke les données à la fois sur disque et dans la RAM. Le comportement par défaut consiste à écrire le document sur le disque à un moment arbitraire (généralement rapidement) après l'avoir stocké dans la RAM. Cela laisse une courte fenêtre où la défaillance du nœud peut entraîner une perte de données.
Dans tous les cas, après avoir écrit dans la RAM, le document sera éventuellement écrit sur le disque. Couchbase conserve une file d'attente d'écriture sur disque que vous pouvez vérifier sur la page du rapport de métriques dans la console de gestion. Maintenant, CB synchronise les écritures sur le cluster, et je pense qu'une écriture sera synchronisée sur un cluster avant que Couchbase ne reconnaisse que l'écriture s'est produite (par exemple, avant que la méthode d'écriture ne revienne à l'appelant).
Si vous avez plus de documents que de RAM disponible, seuls les documents les plus fréquemment consultés seront stockés dans la RAM pour une récupération rapide, tous les autres étant "expulsés" sur le disque.
Conseil ;
Lorsque la taille du bucket est passée de 200 Go à 10 Go dans la source, la réplication est devenue suffisamment rapide. En d'autres termes, si la taille du bucket est élevée et que toutes les données sont dans la RAM, j'ai constaté que la réplication avait un intervalle de 10 secondes.
La source et la cible doivent avoir le même paramètre Linux et les mêmes ressources. Ce n'est qu'un conseil.
Le résident du compartiment de production doit être %100. Parce que la vitesse de réplication est importante.
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
Conseil ;
Je recommande que la source et la cible aient le même paramètre et disposent des mêmes ressources.
Il s'agit du paramètre de compartiment, du paramètre de cluster, du processeur, de la mémoire, de la qualité du disque, etc.
La réplication Xdcr n'est qu'une réplication de données. Avant la réplication, vous devez créer des métadonnées de compartiment.
Si vous le souhaitez, vous créez un utilisateur, un index, une vue, un événement, etc.
À titre d'information supplémentaire ;
Vous pouvez faire une réplication xdcr sur la version communautaire.
Vous pouvez effectuer une réplication xdcr sur la version entreprise. Cela nécessite une licence supplémentaire. Si vous n'utilisez pas la veille comme prod, ce n'est pas un frais élevé.
Les autres connecteurs de Couchbase pour XDCR ; Elasticsearch, Hadoop, Kafka, Spark, Talend, SQL (ODBC/JDBC)
La gestion de Couchbase peut être effectuée via l'interface utilisateur WEB, l'API REST et la CLI. En particulier, l'interface utilisateur Web est très simple et facile à utiliser. Vous pouvez effectuer de nombreuses transactions et requêtes opérationnelles via l'interface utilisateur.
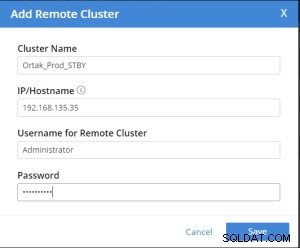
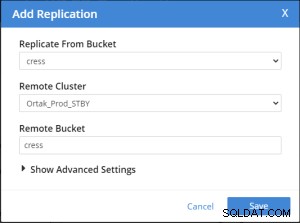
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Les paramètres de mémoire pour les paramètres de cluster Xdcr sont donnés en fonction de la valeur de la mémoire du serveur.
Doit être de taille libre pour la mémoire du serveur.
Xdcr a besoin de mémoire supplémentaire dans le cluster de production.
La réplication de buckets multiples couchbase est possible.
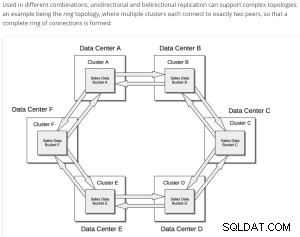
Exemple d'opération simple de réplication XDCR ;
Onglet Xdcr sélectionné sur la page d'accueil de couchbase.

L'onglet Ajouter un cluster distant est sélectionné sur l'onglet xdcr sélectionné.

L'opération d'ajout de cluster distant est effectuée après .
Ajouter un onglet de réplication est sélectionné sur l'onglet xdcr sélectionné.
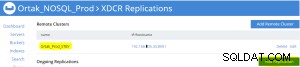
L'opération d'ajout de réplication de bucket est effectuée après .
Meilleurs paramètres pour les performances xdcr . Mais il peut être redéfini pour votre système.

Statut de réplication sur l'onglet xdcr de la source (prod)
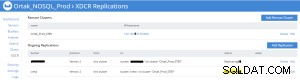
Statistiques de réplication de bucket
Performance de réplication conforme ;

Performances de réplication sur la source ;

Références ;
1-) https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-) https://docs.couchbase.com/
3-) https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-) https://www.quora.com/What-is-the-relation-between-SQL-NoSQL-the-CAP-theorem-and-ACID
Fatih Gençali – Certifications Couchbase





