Dans les deux articles de blog précédents, nous avons couvert à la fois le déploiement des quatre types de clustering/réplication (MySQL/Galera, MySQL Replication, MongoDB &PostgreSQL) et la gestion/surveillance de vos bases de données et clusters existants. Ainsi, après avoir lu ces deux premiers articles de blog, vous avez pu ajouter vos 20 configurations de réplication existantes à ClusterControl, les étendre et déployer en plus deux nouveaux clusters Galera tout en faisant une tonne d'autres choses. Ou peut-être avez-vous déployé des systèmes MongoDB et/ou PostgreSQL. Alors maintenant, comment les gardez-vous en bonne santé ?
C'est exactement le sujet de cet article de blog :comment tirer parti de la surveillance des performances de ClusterControl et de la fonctionnalité de conseil pour maintenir vos bases de données et clusters MySQL, MongoDB et/ou PostgreSQL en bonne santé. Alors, comment cela se fait-il dans ClusterControl ?
Liste des clusters de bases de données
Les informations les plus importantes se trouvent déjà dans la liste des clusters :tant qu'il n'y a pas d'alarmes et qu'aucun hôte n'est en panne, tout fonctionne correctement. Une alarme est déclenchée si une certaine condition est remplie, par ex. l'hôte échange et attire votre attention sur le problème que vous devez étudier. Cela signifie que les alarmes sont non seulement déclenchées lors d'une panne, mais aussi pour vous permettre de gérer de manière proactive vos bases de données.
Supposons que vous vous connectiez à ClusterControl et voyiez une liste de clusters comme celle-ci, vous aurez certainement quelque chose à étudier :un nœud est en panne dans le cluster Galera par exemple et chaque cluster a diverses alarmes :
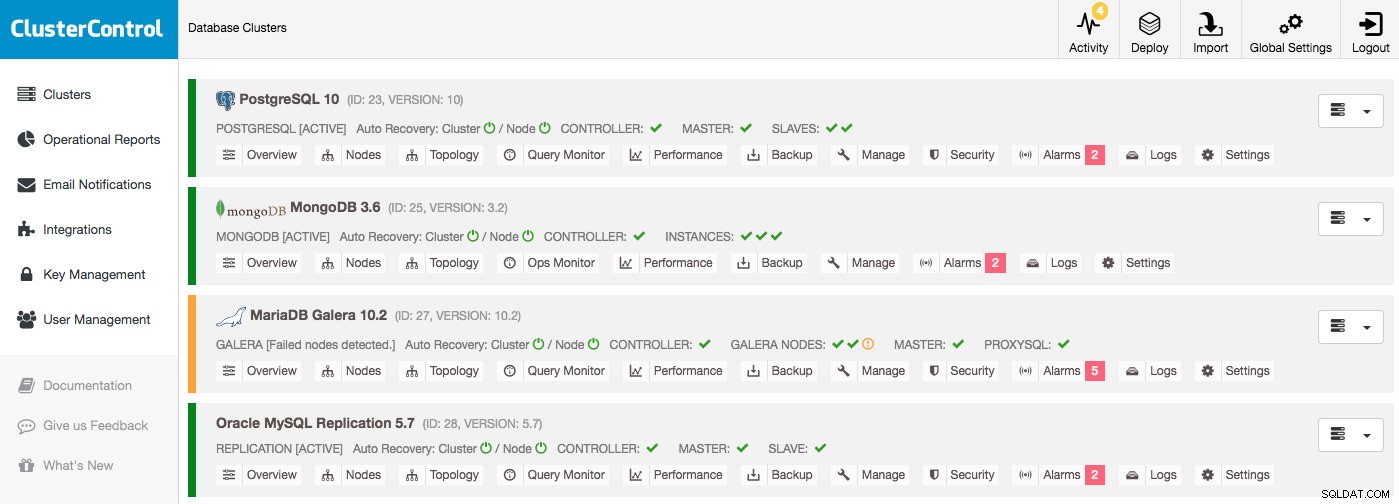
Une fois que vous avez cliqué sur l'une des alarmes, vous accédez à une page détaillée sur toutes les alarmes du cluster. Les détails de l'alarme expliquent le problème et, dans la plupart des cas, conseillent également l'action pour résoudre le problème.
Vous pouvez configurer vos propres alarmes en créant des expressions personnalisées, mais cela a été abandonné au profit de notre nouveau Developer Studio qui vous permet d'écrire des Javascripts personnalisés et de les exécuter en tant que conseillers. Nous reviendrons sur ce sujet plus tard dans cet article.
Présentation du cluster - Tableaux de bord
Lors de l'ouverture de la vue d'ensemble du cluster, nous pouvons immédiatement voir les métriques de performance les plus importantes pour le cluster dans les onglets. Cet aperçu peut différer selon le type de cluster car, par exemple, Galera a des métriques de performances différentes à surveiller que MySQL, PostgreSQL ou MongoDB traditionnels.
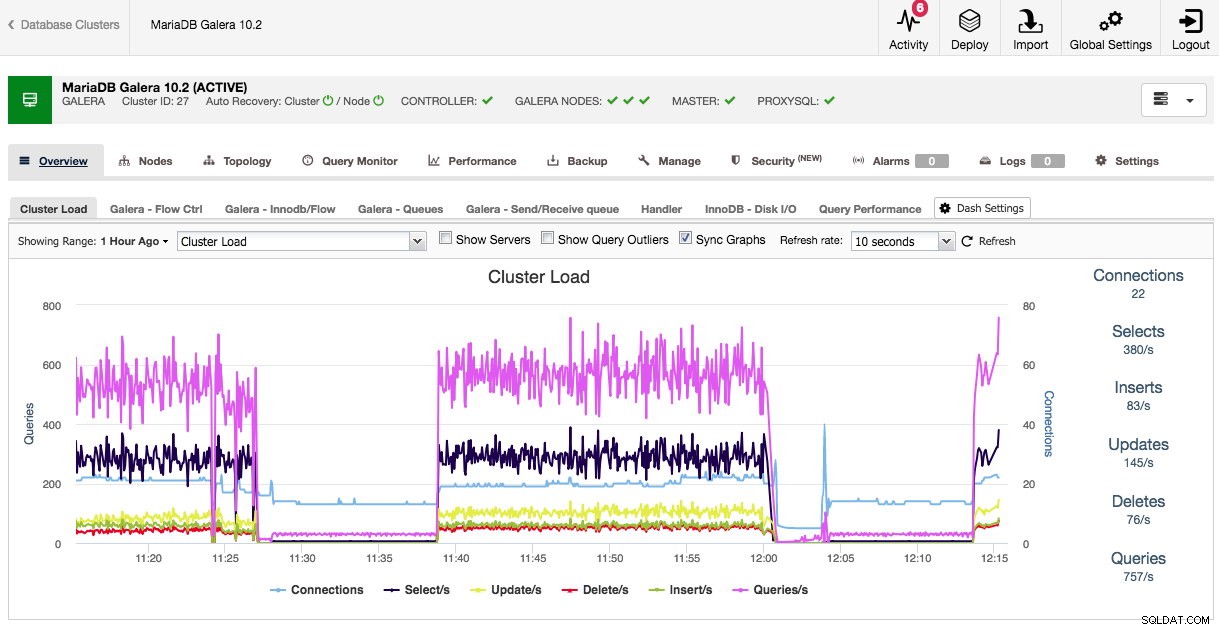
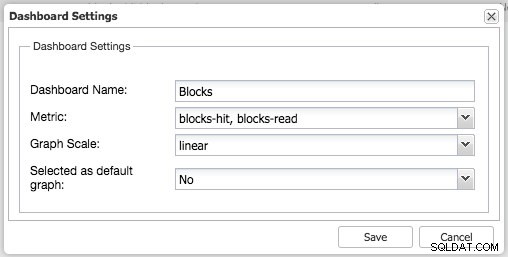
La vue d'ensemble par défaut et les onglets présélectionnés sont personnalisables. En cliquant sur Aperçu -> Paramètres du tableau de bord une boîte de dialogue vous permet de définir le tableau de bord :
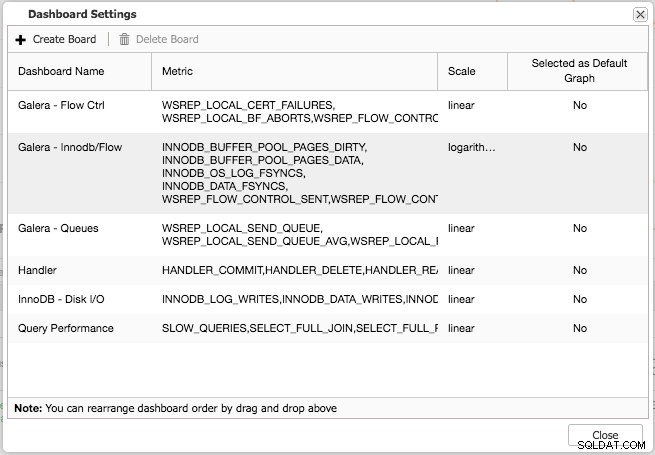
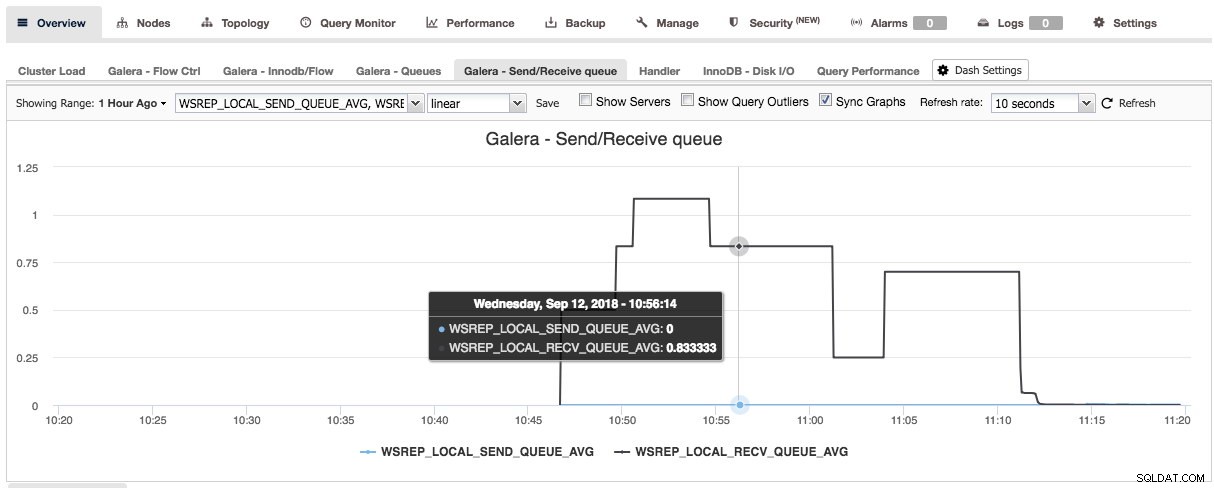
En appuyant sur le signe plus, vous pouvez ajouter et définir vos propres mesures pour représenter graphiquement le tableau de bord. Dans notre cas, nous allons définir un nouveau tableau de bord présentant la moyenne des files d'attente d'envoi et de réception spécifiques à Galera :
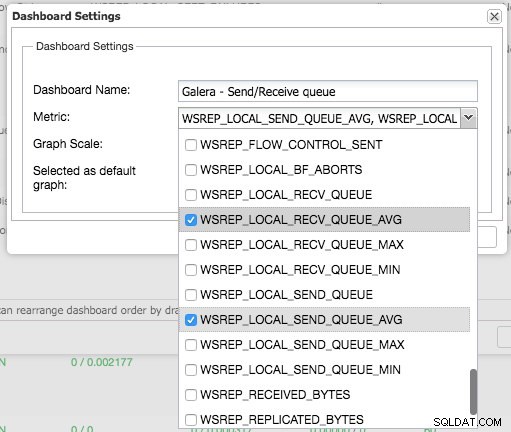
Ce nouveau tableau de bord devrait nous donner un bon aperçu de la longueur moyenne de la file d'attente de notre cluster Galera.
Une fois que vous aurez cliqué sur Enregistrer, le nouveau tableau de bord deviendra disponible pour ce cluster :
De même, vous pouvez également le faire pour PostgreSQL, par exemple, nous pouvons surveiller les blocs partagés touchés par rapport aux blocs lus :
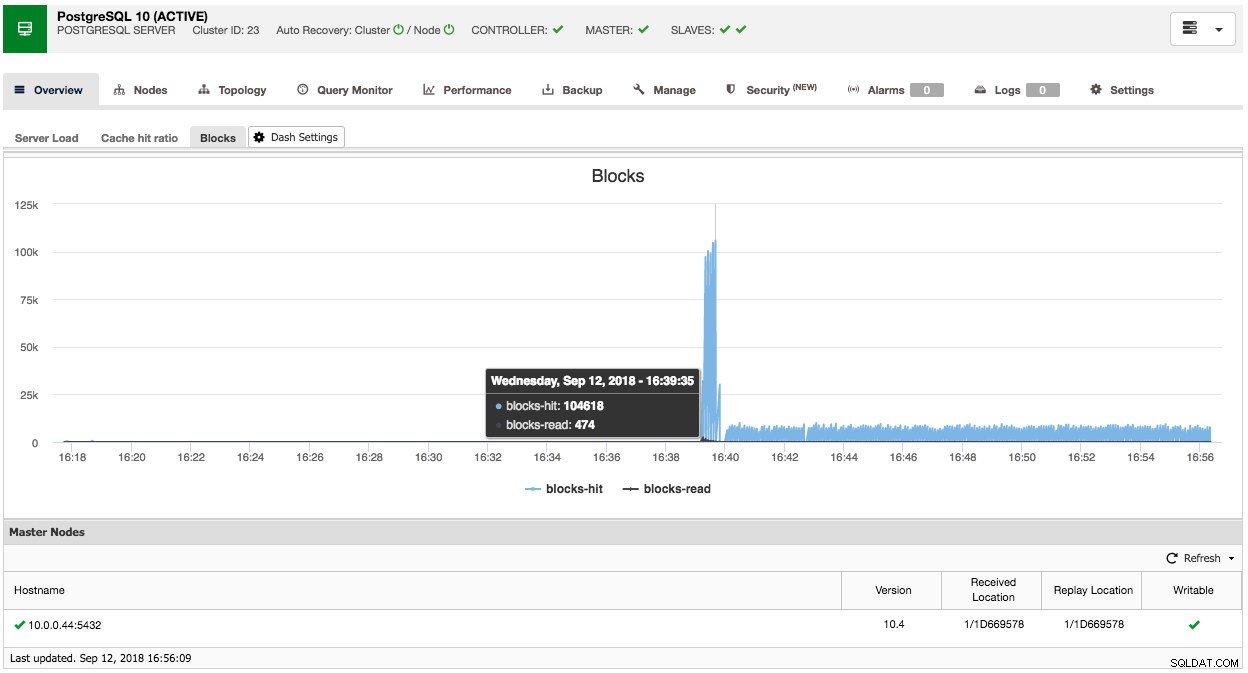
Comme vous pouvez le constater, il est relativement facile de personnaliser votre propre tableau de bord (par défaut).
Présentation du cluster – Moniteur de requêtes
L'onglet Query Monitor est disponible pour les configurations basées sur MySQL et PostgreSQL et se compose de trois tableaux de bord :Top Requêtes, Requêtes en cours d'exécution et Requêtes aberrantes.
Dans le tableau de bord des requêtes en cours d'exécution, vous trouverez toutes les requêtes en cours d'exécution. C'est essentiellement l'équivalent de l'instruction SHOW FULL PROCESSLIST dans la base de données MySQL.
Les requêtes principales et les valeurs aberrantes de requête reposent toutes deux sur l'entrée du journal des requêtes lentes ou du schéma de performances. L'utilisation du schéma de performances est toujours recommandée et sera utilisée automatiquement si elle est activée. Sinon, ClusterControl utilisera le journal des requêtes lentes MySQL pour capturer les requêtes en cours d'exécution. Pour éviter que ClusterControl ne soit trop intrusif et que le journal des requêtes lentes ne devienne trop volumineux, ClusterControl échantillonne le journal des requêtes lentes en l'activant et en le désactivant. Cette boucle est définie par défaut sur 1 seconde de capture et le long_query_time est réglé sur 0,5 seconde. Si vous souhaitez modifier ces paramètres pour votre cluster, vous pouvez le faire via Paramètres -> Query Monitor .
Les principales requêtes afficheront, comme leur nom l'indique, les principales requêtes qui ont été échantillonnées. Vous pouvez les trier sur différentes colonnes :par exemple la fréquence, le temps d'exécution moyen, le temps d'exécution total ou le temps d'écart-type :
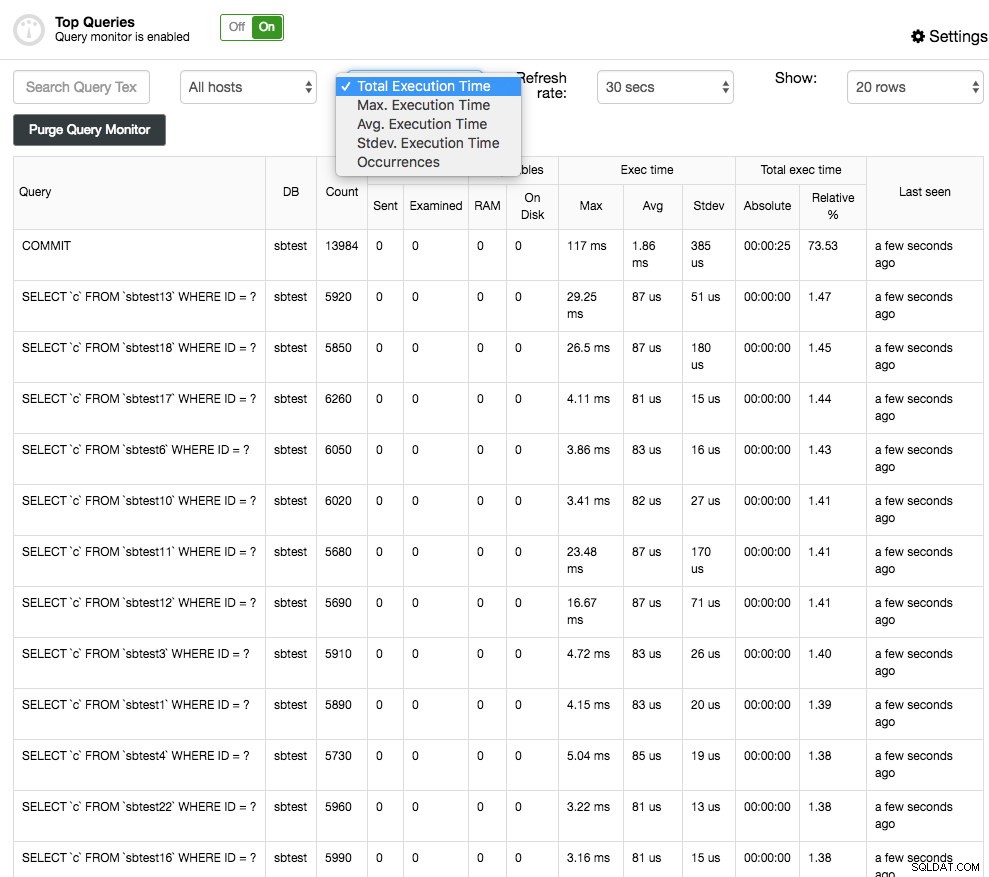
Vous pouvez obtenir plus de détails sur la requête en la sélectionnant et cela présentera le plan d'exécution de la requête (si disponible) et des conseils/conseils d'optimisation. Les valeurs aberrantes de la requête sont similaires aux requêtes principales, mais vous permettent ensuite de filtrer les requêtes par hôte et de les comparer dans le temps.
Présentation du cluster - Opérations
Semblables aux systèmes PostgreSQL et MySQL, les clusters MongoDB ont la vue d'ensemble des opérations et sont similaires aux requêtes en cours d'exécution de MySQL. Cette vue d'ensemble est similaire à l'émission de la commande db.currentOp() dans MongoDB.
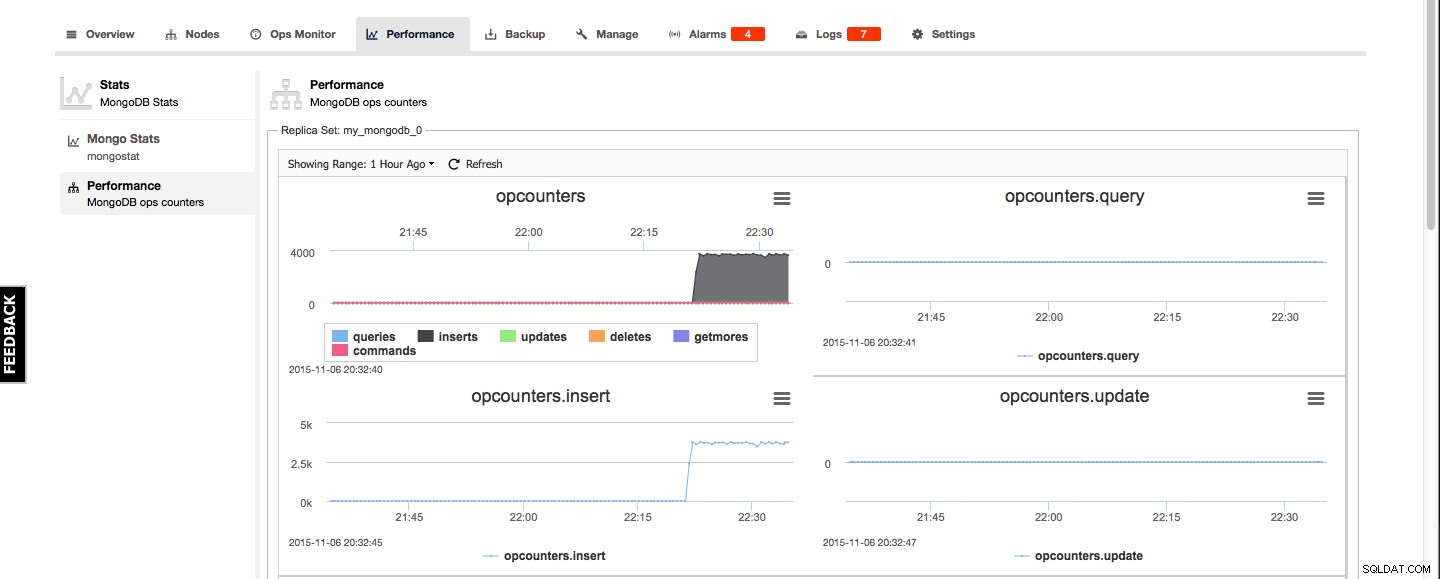
Présentation du cluster - Performances
MySQL/Galera
L'onglet Performances est probablement le meilleur endroit pour trouver les performances et la santé globales de vos clusters. Pour MySQL et Galera, il se compose d'une page d'aperçu, des conseillers, des aperçus d'état/variables, de l'analyseur de schéma et du journal des transactions.
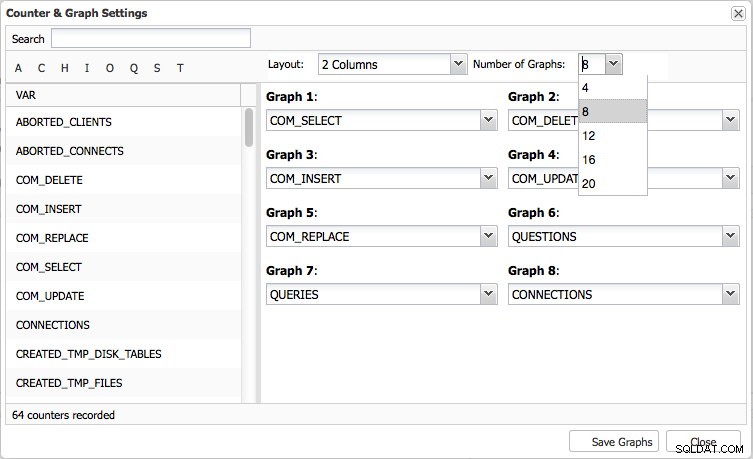
La page Vue d'ensemble vous donnera un aperçu graphique des métriques les plus importantes de votre cluster. Ceci est évidemment différent selon le type de cluster. Huit statistiques ont été définies par défaut, mais vous pouvez facilement définir les vôtres (jusqu'à 20 graphiques si nécessaire) :
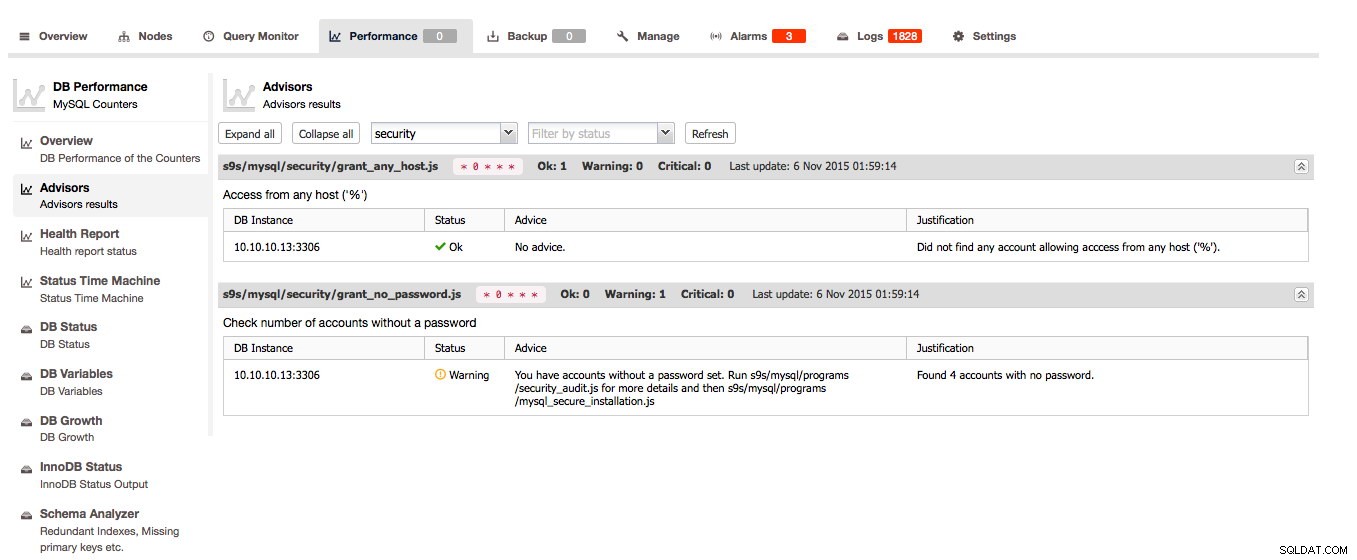
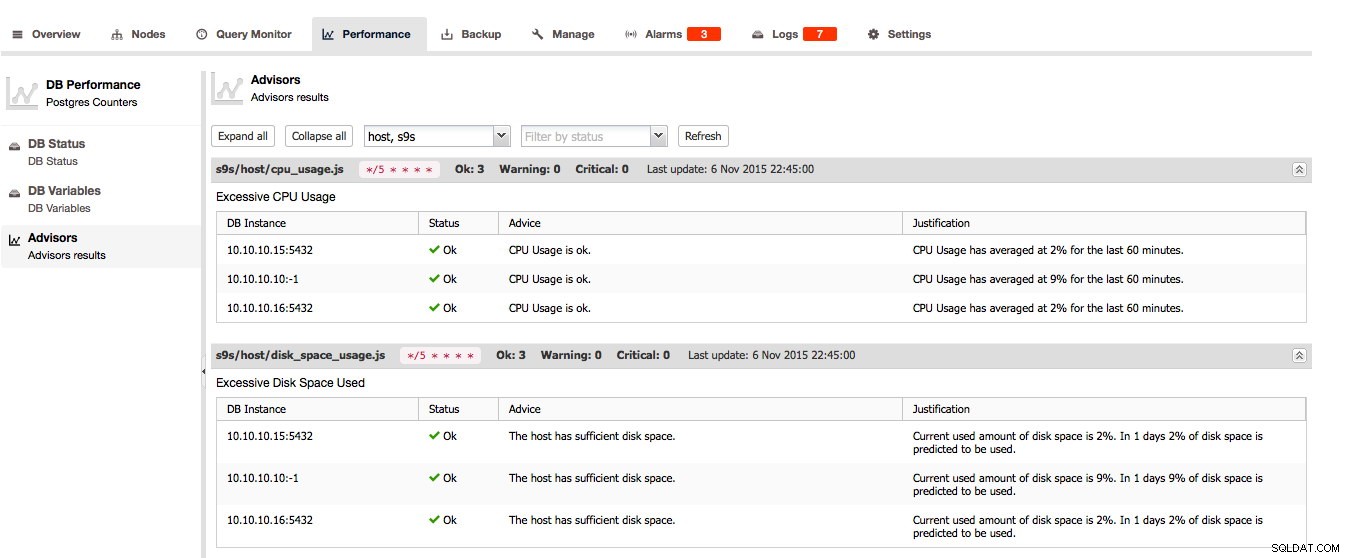
Les Advisors sont l'une des fonctionnalités clés de ClusterControl :les Advisors sont des vérifications par script qui peuvent être exécutées à la demande. Les conseillers peuvent évaluer presque tous les faits connus sur l'hôte et/ou le cluster et donner leur avis sur la santé de l'hôte et/ou du cluster et peuvent même donner des conseils sur la façon de résoudre les problèmes ou d'améliorer vos hôtes !
La meilleure partie reste à venir :vous pouvez créer vos propres vérifications dans Developer Studio (ClusterControl -> Gérer -> Developer Studio ), exécutez-les à intervalles réguliers et réutilisez-les dans la section Conseillers. Nous avons blogué sur cette nouvelle fonctionnalité plus tôt cette année.
Nous allons ignorer l'aperçu des statuts/variables de MySQL et de Galera, car cela est utile à titre de référence, mais pas pour cet article de blog :il suffit que vous sachiez qu'il est ici.
Supposons maintenant que votre base de données se développe mais que vous souhaitiez savoir à quelle vitesse elle s'est développée au cours de la semaine dernière. Vous pouvez en fait suivre la croissance des tailles de données et d'index directement dans ClusterControl :
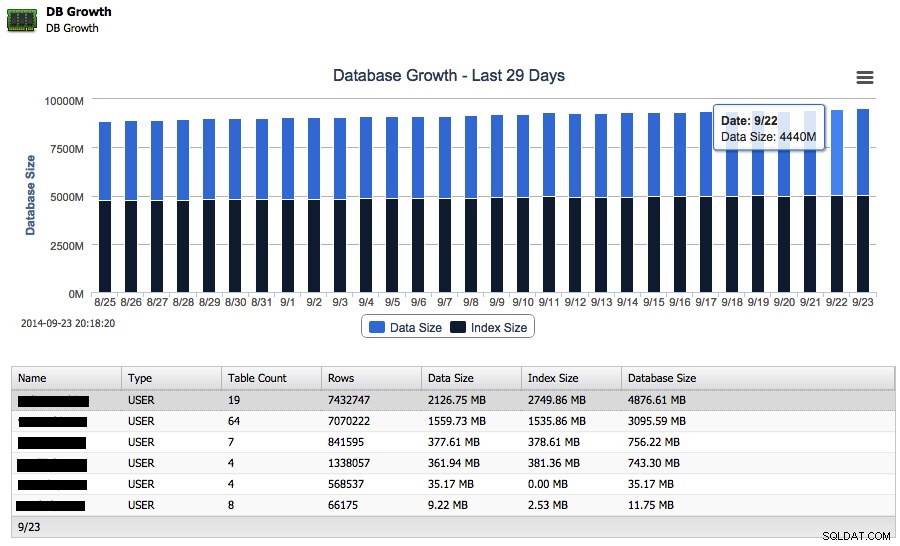
Et à côté de la croissance totale sur disque, il peut également signaler les 25 schémas les plus importants.
Une autre fonctionnalité importante est l'analyseur de schéma dans ClusterControl :
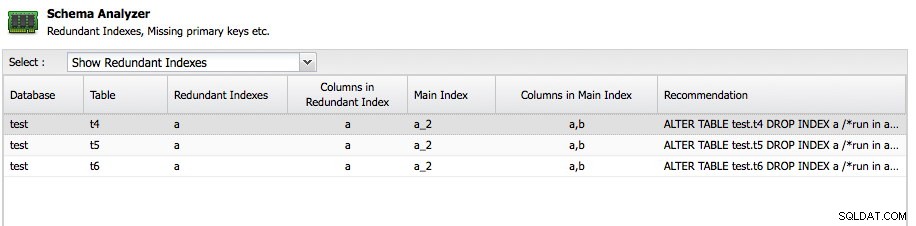
ClusterControl analysera vos schémas et recherchera des index redondants, des tables MyISAM et des tables sans clé primaire. Bien sûr, il vous appartient entièrement de conserver une table sans clé primaire, car certaines applications pourraient l'avoir créée de cette façon, mais au moins, il est bon d'obtenir les conseils ici gratuitement. L'analyseur de schéma recommande même l'instruction ALTER nécessaire pour résoudre le problème.
PostgreSQL
Pour PostgreSQL, les conseillers, l'état de la base de données et les variables de la base de données peuvent être trouvés ici :
MongoDB
Pour MongoDB, les statistiques Mongo et l'aperçu des performances se trouvent sous l'onglet Performances. Mongo Stats est un aperçu de la sortie de mongostat et l'aperçu des performances donne un bon aperçu graphique des opcounters MongoDB :
Réflexions finales
Nous vous avons montré comment garder vos yeux sur les fonctionnalités de surveillance et de contrôle de santé les plus importantes de ClusterControl. Évidemment, ce n'est que le début du voyage car nous allons bientôt commencer une autre série de blogs sur les capacités de Developer Studio et sur la façon dont vous pouvez tirer le meilleur parti de vos propres vérifications. Gardez également à l'esprit que notre support pour MongoDB et PostgreSQL n'est pas aussi étendu que notre ensemble d'outils MySQL, mais nous nous améliorons continuellement à ce sujet.
Vous vous demandez peut-être pourquoi nous avons ignoré la surveillance des performances et les vérifications de l'état de HAProxy, ProxySQL et MaxScale. Nous l'avons fait délibérément car la série de blogs ne couvrait jusqu'à présent que les déploiements de clusters et non le déploiement de composants HA. C'est donc le sujet que nous aborderons la prochaine fois.



