Évaluer quel modèle d'architecture de streaming correspond le mieux à votre cas d'utilisation est une condition préalable à un déploiement de production réussi.
L'écosystème Apache Hadoop est devenu une plate-forme privilégiée pour les entreprises qui cherchent à traiter et à comprendre des données à grande échelle en temps réel. Des technologies comme Apache Kafka, Apache Flume, Apache Spark, Apache Storm et Apache Samza repoussent de plus en plus les limites de ce qui est possible. Il est souvent tentant de regrouper les cas d'utilisation de streaming à grande échelle, mais en réalité, ils ont tendance à se décomposer en quelques modèles architecturaux différents, avec différents composants de l'écosystème mieux adaptés à différents problèmes.
Dans cet article, je vais décrire les quatre principaux modèles de streaming que nous avons rencontrés avec des clients exécutant des hubs de données d'entreprise en production, et expliquer comment implémenter ces modèles de manière architecturale sur Hadoop.
Modèles de diffusion
Les quatre modèles de flux de base (souvent utilisés en tandem) sont :
- Ingestion de flux : Implique la persistance à faible latence des événements sur HDFS, Apache HBase et Apache Solr.
- Traitement des événements en temps quasi réel (NRT) avec contexte externe : Prend des mesures telles que l'alerte, le signalement, la transformation et le filtrage des événements à mesure qu'ils arrivent. Des actions peuvent être prises sur la base de critères sophistiqués, tels que des modèles de détection d'anomalies. Les cas d'utilisation courants, tels que la détection et la recommandation de fraudes NRT, exigent souvent des latences faibles inférieures à 100 millisecondes.
- Traitement partitionné des événements NRT : Semblable au traitement des événements NRT, mais tirant des avantages du partitionnement des données, comme le stockage d'informations externes plus pertinentes en mémoire. Ce modèle nécessite également des latences de traitement inférieures à 100 millisecondes.
- Topologie complexe pour les agrégations ou le ML : Le Saint Graal du traitement de flux :obtenir des réponses en temps réel à partir des données avec un ensemble d'opérations complexes et flexibles. Ici, étant donné que les résultats dépendent souvent de calculs fenêtrés et nécessitent davantage de données actives, l'accent passe d'une latence ultra-faible à la fonctionnalité et à la précision.
Dans les sections suivantes, nous aborderons les méthodes recommandées pour mettre en œuvre de tels modèles de manière testée, éprouvée et maintenable.
Ingestion de flux
Traditionnellement, Flume a été le système recommandé pour l'ingestion de flux. Sa grande bibliothèque de sources et de puits couvre toutes les bases de ce qu'il faut consommer et où écrire. (Pour plus de détails sur la configuration et la gestion de Flume, Utiliser Flume , le livre O'Reilly Media de Hari Shreedharan, ingénieur logiciel Cloudera/membre de Flume PMC, est une excellente ressource.)
Au cours de la dernière année, Kafka est également devenu populaire en raison de fonctionnalités puissantes telles que la lecture et la réplication. En raison du chevauchement entre les objectifs de Flume et de Kafka, leur relation est souvent confuse. Comment s'emboîtent-ils ? La réponse est simple :Kafka est un tube similaire à l'abstraction de Canal de Flume, bien qu'un meilleur tube en raison de sa prise en charge des fonctionnalités mentionnées ci-dessus. Une approche courante consiste à utiliser Flume pour la source et le puits, et Kafka pour le tuyau entre eux.
Le schéma ci-dessous illustre comment Kafka peut servir de source de données en amont vers Flume, de destination en aval de Flume ou de canal Flume.
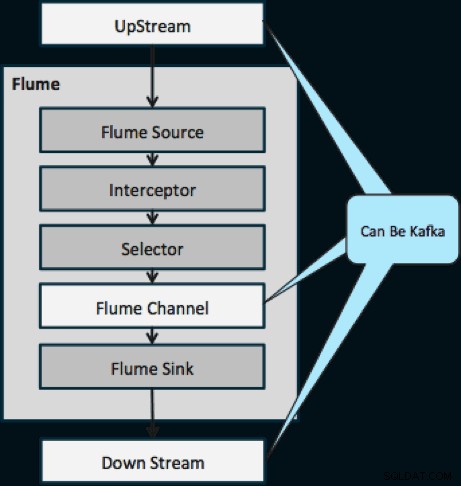
La conception illustrée ci-dessous est massivement évolutive, renforcée au combat, surveillée de manière centralisée via Cloudera Manager, tolérante aux pannes et prenant en charge la relecture.
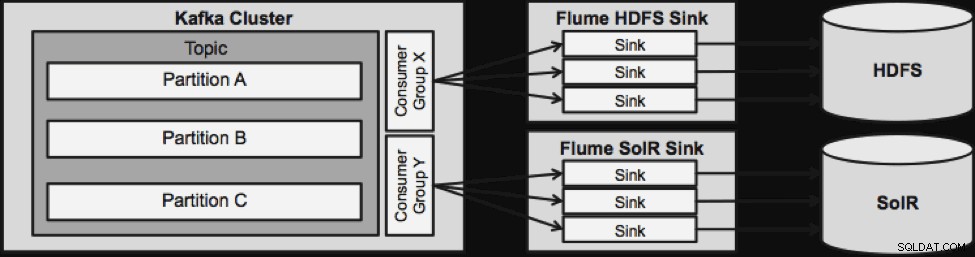
Une chose à noter avant de passer à la prochaine architecture de streaming est la manière dont cette conception gère gracieusement les échecs. Les éviers Flume proviennent d'un groupe de consommateurs Kafka. Le groupe Consumer suit le décalage du sujet avec l'aide d'Apache ZooKeeper. Si un Flume Sink est perdu, le consommateur Kafka redistribuera la charge aux éviers restants. Lorsque le Flume Sink revient, le groupe de consommateurs redistribue à nouveau.
Traitement des événements NRT avec contexte externe
Pour réitérer, un cas d'utilisation courant pour ce modèle consiste à examiner les événements en continu et à prendre des décisions immédiates, soit pour transformer les données, soit pour prendre une sorte d'action externe. La logique de décision dépend souvent de profils externes ou de métadonnées. Un moyen simple et évolutif de mettre en œuvre cette approche consiste à ajouter un intercepteur Source ou Sink Flume à votre architecture Kafka/Flume. Avec un réglage modeste, il n'est pas difficile d'obtenir des latences en quelques millisecondes.
Les Flume Interceptors prennent des événements ou des lots d'événements et permettent au code utilisateur de les modifier ou de prendre des mesures en fonction de ceux-ci. Le code utilisateur peut interagir avec la mémoire locale ou un système de stockage externe comme HBase pour obtenir les informations de profil nécessaires aux décisions. HBase peut généralement nous fournir nos informations en 4 à 25 millisecondes environ, en fonction du réseau, de la conception du schéma et de la configuration. Vous pouvez également configurer HBase de manière à ce qu'il ne soit jamais arrêté ou interrompu, même en cas de panne.
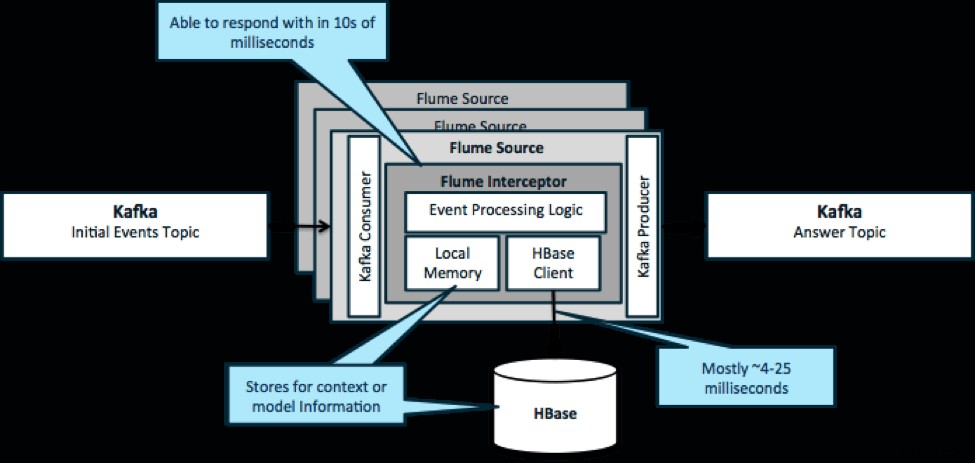
La mise en œuvre ne nécessite pratiquement aucun codage au-delà de la logique spécifique à l'application dans l'intercepteur. Cloudera Manager offre une interface utilisateur intuitive pour déployer cette logique via des colis ainsi que pour connecter, configurer et surveiller les services.
Traitement des événements partitionnés NRT avec contexte externe
Dans l'architecture illustrée ci-dessous (solution non partitionnée), vous auriez besoin d'appeler fréquemment HBase car le contexte externe pertinent pour des événements particuliers ne tient pas dans la mémoire locale des intercepteurs Flume.
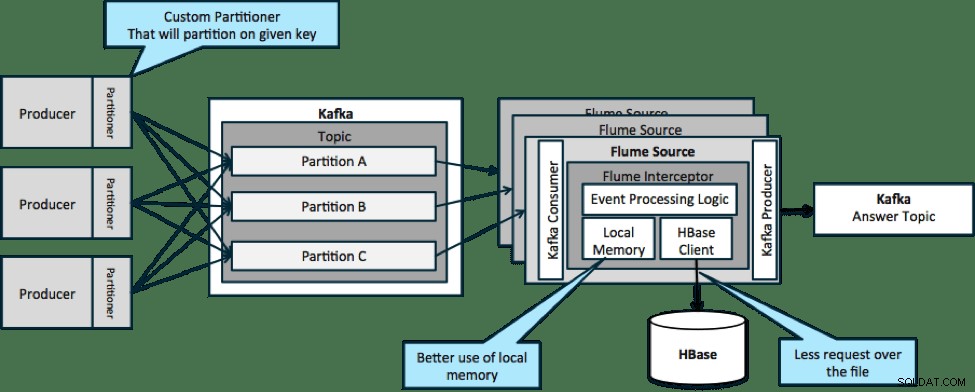
Toutefois, si vous définissez une clé pour partitionner vos données, vous pouvez faire correspondre les données entrantes au sous-ensemble des données contextuelles qui leur sont pertinentes. Si vous partitionnez les données 10 fois, vous n'avez besoin de conserver que 1/10e des profils en mémoire. HBase est rapide, mais la mémoire locale est plus rapide. Kafka vous permet de définir un partitionneur personnalisé qu'il utilise pour diviser vos données.
Notez que Flume n'est pas strictement nécessaire ici; la solution racine ici juste un consommateur Kafka. Ainsi, vous pouvez utiliser uniquement un consommateur dans YARN ou une application MapReduce Map uniquement.
Topologie complexe pour les agrégations ou ML
Jusqu'à présent, nous avons exploré les opérations au niveau des événements. Cependant, vous avez parfois besoin d'opérations plus complexes telles que les comptages, les moyennes, la mise en session ou la création de modèles d'apprentissage automatique qui fonctionnent sur des lots de données. Dans ce cas, Spark Streaming est l'outil idéal pour plusieurs raisons :
- Il est facile à développer par rapport à d'autres outils. Les API riches et concises de Spark facilitent la création de topologies complexes.
- Code similaire pour le traitement par flux et par lots. Avec quelques modifications, le code pour les petits lots en temps réel peut être utilisé pour d'énormes lots hors ligne. En plus de réduire la taille du code, cette approche réduit le temps nécessaire aux tests et à l'intégration.
- Il y a un moteur à connaître. Il y a un coût qui va dans la formation du personnel sur les bizarreries et les internes des moteurs de traitement distribués. La standardisation sur Spark consolide ce coût pour le streaming et le lot.
- Le micro-traitement par lots vous aide à évoluer de manière fiable. L'accusé de réception au niveau du lot permet d'augmenter le débit et de trouver des solutions sans craindre un double envoi. Le micro-batching permet également d'envoyer des modifications à HDFS ou HBase en termes de performances à grande échelle.
- L'intégration de l'écosystème Hadoop est intégrée. Spark a une intégration profonde avec HDFS, HBase et Kafka.
- Aucun risque de perte de données. Grâce au WAL et à Kafka, Spark Streaming évite la perte de données en cas de panne.
- Il est facile à déboguer et à exécuter. Vous pouvez déboguer et parcourir votre code Spark Streaming dans un IDE local sans cluster. De plus, le code ressemble à un code de programmation fonctionnel normal, il ne faut donc pas beaucoup de temps à un développeur Java ou Scala pour faire le saut. (Python est également pris en charge.)
- Le streaming est nativement avec état. Dans Spark Streaming, l'état est un citoyen de première classe, ce qui signifie qu'il est facile d'écrire des applications de streaming avec état qui résistent aux défaillances de nœuds.
- En tant que norme de facto, Spark bénéficie d'investissements à long terme de l'ensemble de l'écosystème.
Au moment d'écrire ces lignes, il y avait environ 700 validations sur Spark dans son ensemble au cours des 30 derniers jours, par rapport à d'autres frameworks de streaming tels que Storm, avec 15 validations au cours de la même période. - Vous avez accès aux bibliothèques de ML.
MLlib de Spark devient extrêmement populaire et ses fonctionnalités ne feront qu'augmenter. - Vous pouvez utiliser SQL si nécessaire.
Avec Spark SQL, vous pouvez ajouter une logique SQL à votre application de streaming pour réduire la complexité du code.
Conclusion
Il y a beaucoup de puissance dans le streaming et plusieurs modèles possibles, mais comme vous l'avez appris dans cet article, vous pouvez faire des choses vraiment puissantes avec un minimum de codage si vous savez quel modèle correspond le mieux à votre cas d'utilisation.
Ted Malaska est architecte de solutions chez Cloudera, contributeur à Spark, Flume et HBase, et co-auteur du livre O'Reilly, Architecture des applications Hadoop.



