Dans notre précédent tutoriel Hadoop , nous avons étudié Hadoop Partitioner en détail. Nous allons maintenant discuter de InputSplit dans Hadoop MapReduce.
Ici, nous allons couvrir ce qu'est Hadoop InputSplit, le besoin d'InputSplit dans MapReduce. Nous discuterons également en détail de la création de ces InputSplits dans Hadoop MapReduce.
Introduction à InputSplit dans Hadoop
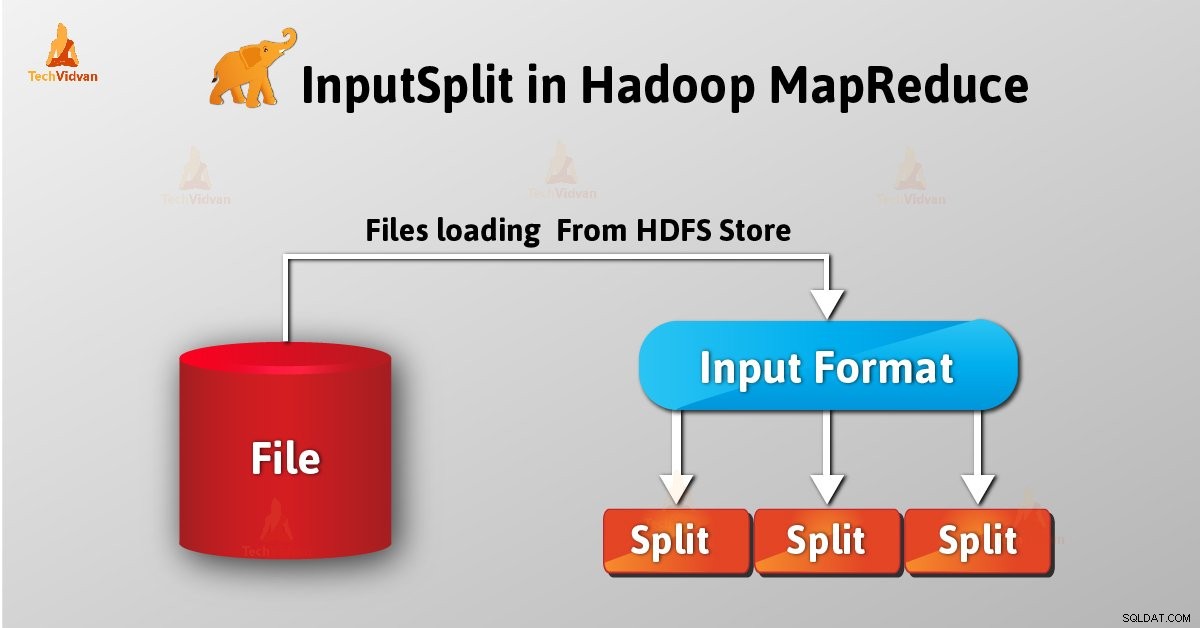
InputSplit est la représentation logique des données dans Hadoop MapReduce. Il représente les données qu'un mappeur individuel processus. Ainsi, le nombre de tâches de carte est égal au nombre d'InputSplits. Le cadre divise la division en enregistrements, que le mappeur traite.
La longueur de MapReduce InputSplit a été mesurée en octets. Chaque InputSplit a des emplacements de stockage (chaînes de nom d'hôte). Le système MapReduce place les tâches cartographiques aussi près que possible des données de la division en utilisant des emplacements de stockage.
Processus du framework Mappez les tâches dans l'ordre de la taille des fractionnements afin que le plus grand soit traité en premier (algorithme d'approximation glouton). Cela minimise le temps d'exécution du travail.
La principale chose à retenir est que Inputsplit ne contient pas les données d'entrée; c'est juste une référence aux données.
Comment les InputSplits sont-ils créés dans Hadoop MapReduce ?
En tant qu'utilisateur, nous ne traitons pas directement InputSplit dans Hadoop, car InputFormat (car InputFormat est responsable de la création du Inputsplit et de la division dans les enregistrements) le crée. FileInputFormat divise un fichier en morceaux de 128 Mo.
De plus, en définissant mapred .min .diviser .taille paramètre dans mapred-site .xml l'utilisateur peut modifier la valeur selon les besoins. De plus, nous pouvons remplacer le paramètre dans l'objet Job utilisé pour soumettre un travail MapReduce particulier.
En écrivant un InputFormat personnalisé, nous pouvons également contrôler la façon dont le fichier est divisé en fractions.
InputSplit est défini par l'utilisateur. L'utilisateur peut également contrôler la taille du fractionnement en fonction de la taille des données dans le programme MapReduce. Par conséquent, dans l'exécution d'une tâche MapReduce, le nombre de tâches de carte est égal au nombre d'InputSplits.
En appelant ‘getSplit()’ , le client calcule les fractionnements pour le travail. Ensuite, il est envoyé au maître d'application, qui utilise leurs emplacements de stockage pour planifier les tâches de carte qui les traiteront sur le cluster.
Après cette tâche de carte passe la division à createRecordReader() méthode. À partir de là, il obtient RecordReader pour la scission. Ensuite, RecordReader génère l'enregistrement (paire clé-valeur) , qu'il transmet à la fonction map.
Conclusion
En conclusion, nous pouvons dire que InputSplit représente les données traitées par un mappeur individuel. Pour chaque fractionnement, une tâche cartographique est créée. Par conséquent, InputFormat crée le InputSplit.
Si vous avez des questions sur InputSplit dans MapReduce, veuillez laisser un commentaire dans une section ci-dessous.



