Conserver des sauvegardes de votre base de données est l'une des tâches les plus importantes dans tout environnement de production. C'est le processus de copie de vos données vers un autre endroit pour les garder en sécurité. Cela peut être utile dans la récupération de situations d'urgence comme la corruption de la base de données ou une base de données qui plante au-delà de toute réparation.
Outre la récupération, une sauvegarde peut également être utilisée pour imiter une base de données de production pour tester une application dans un environnement différent, ou même pour déboguer quelque chose qui ne peut pas être fait sur la base de données de production.
Il existe différentes méthodes de sauvegarde de base de données que vous pouvez mettre en œuvre, de la sauvegarde logique à l'aide d'outils intégrés à la base de données (par exemple, mysqldump, mongodump, pg_dump) à la sauvegarde physique à l'aide d'outils tiers (par exemple. xtrabackup, barman, pgbackrest, sauvegarde cohérente mongodb).
La méthode à utiliser dépend souvent de la façon dont vous souhaitez restaurer. Par exemple, supposons que vous avez supprimé une table ou une collection par erreur. Aussi improbable que cela puisse paraître, cela arrive. Ainsi, le moyen le plus rapide de récupérer serait de restaurer uniquement cette table ou cette collection, au lieu d'avoir à restaurer une base de données entière.
Sauvegarde et restauration dans Mongodb
Mongodump et mongorestore est l'outil de sauvegarde logique utilisé dans MongoDB, c'est un peu mysqldump dans MySQL, ou pg_dump dans PostgreSQL. L'utilitaire mongodump et mongorestore sera inclus lorsque vous installerez MongoDB et il videra les données au format BSON. Mongodump est utilisé pour sauvegarder logiquement la base de données dans des fichiers de vidage, tandis que mongorestore est utilisé pour l'opération de restauration.
Les commandes mongodump et mongorestore sont faciles à utiliser, bien qu'il existe de nombreuses options.
Comme nous pouvons le voir ci-dessous, vous pouvez sauvegarder des bases de données ou des collections spécifiques. Vous pouvez même prendre un instantané à un instant donné en incluant l'oplog.
example@sqldat.com:~# mongodump --help
Usage:
mongodump <options>
Export the content of a running server into .bson files.
Specify a database with -d and a collection with -c to only dump that database or collection.
See https://docs.mongodb.org/manual/reference/program/mongodump/ for more information.
general options:
--help print usage
--version print the tool version and exit
verbosity options:
-v, --verbose=<level> more detailed log output (include multiple times for more verbosity, e.g. -vvvvv, or specify a numeric value, e.g. --verbose=N)
--quiet hide all log output
connection options:
-h, --host=<hostname> mongodb host to connect to (setname/host1,host2 for replica sets)
--port=<port> server port (can also use --host hostname:port)
kerberos options:
--gssapiServiceName=<service-name> service name to use when authenticating using GSSAPI/Kerberos ('mongodb' by default)
--gssapiHostName=<host-name> hostname to use when authenticating using GSSAPI/Kerberos (remote server's address by default)
ssl options:
--ssl connect to a mongod or mongos that has ssl enabled
--sslCAFile=<filename> the .pem file containing the root certificate chain from the certificate authority
--sslPEMKeyFile=<filename> the .pem file containing the certificate and key
--sslPEMKeyPassword=<password> the password to decrypt the sslPEMKeyFile, if necessary
--sslCRLFile=<filename> the .pem file containing the certificate revocation list
--sslAllowInvalidCertificates bypass the validation for server certificates
--sslAllowInvalidHostnames bypass the validation for server name
--sslFIPSMode use FIPS mode of the installed openssl library
authentication options:
-u, --username=<username> username for authentication
-p, --password=<password> password for authentication
--authenticationDatabase=<database-name> database that holds the user's credentials
--authenticationMechanism=<mechanism> authentication mechanism to use
namespace options:
-d, --db=<database-name> database to use
-c, --collection=<collection-name> collection to use
uri options:
--uri=mongodb-uri mongodb uri connection string
query options:
-q, --query= query filter, as a JSON string, e.g., '{x:{$gt:1}}'
--queryFile= path to a file containing a query filter (JSON)
--readPreference=<string>|<json> specify either a preference name or a preference json object
--forceTableScan force a table scan
output options:
-o, --out=<directory-path> output directory, or '-' for stdout (defaults to 'dump')
--gzip compress archive our collection output with Gzip
--repair try to recover documents from damaged data files (not supported by all storage engines)
--oplog use oplog for taking a point-in-time snapshot
--archive=<file-path> dump as an archive to the specified path. If flag is specified without a value, archive is written to stdout
--dumpDbUsersAndRoles dump user and role definitions for the specified database
--excludeCollection=<collection-name> collection to exclude from the dump (may be specified multiple times to exclude additional collections)
--excludeCollectionsWithPrefix=<collection-prefix> exclude all collections from the dump that have the given prefix (may be specified multiple times to exclude additional prefixes)
-j, --numParallelCollections= number of collections to dump in parallel (4 by default) (default: 4)
--viewsAsCollections dump views as normal collections with their produced data, omitting standard collectionsIl existe de nombreuses options dans la commande mongorestore, l'option obligatoire est liée aux options de connexion telles que l'hôte, le port et l'authentification. Il existe d'autres paramètres, comme -j utilisé pour restaurer des collections en parallèle, -c ou --collection est utilisé pour une collection spécifique, et -d ou --db est utilisé pour définir une base de données spécifique. La liste des options du paramètre mongorestore peut être affichée à l'aide de l'aide :
example@sqldat.com:~# mongorestore --help
Usage:
mongorestore <options> <directory or file to restore>
Restore backups generated with mongodump to a running server.
Specify a database with -d to restore a single database from the target directory,
or use -d and -c to restore a single collection from a single .bson file.
See https://docs.mongodb.org/manual/reference/program/mongorestore/ for more information.
general options:
--help print usage
--version print the tool version and exit
verbosity options:
-v, --verbose=<level> more detailed log output (include multiple times for more verbosity, e.g. -vvvvv, or specify a numeric value, e.g. --verbose=N)
--quiet hide all log output
connection options:
-h, --host=<hostname> mongodb host to connect to (setname/host1,host2 for replica sets)
--port=<port> server port (can also use --host hostname:port)
kerberos options:
--gssapiServiceName=<service-name> service name to use when authenticating using GSSAPI/Kerberos ('mongodb' by default)
--gssapiHostName=<host-name> hostname to use when authenticating using GSSAPI/Kerberos (remote server's address by default)
ssl options:
--ssl connect to a mongod or mongos that has ssl enabled
--sslCAFile=<filename> the .pem file containing the root certificate chain from the certificate authority
--sslPEMKeyFile=<filename> the .pem file containing the certificate and key
--sslPEMKeyPassword=<password> the password to decrypt the sslPEMKeyFile, if necessary
--sslCRLFile=<filename> the .pem file containing the certificate revocation list
--sslAllowInvalidCertificates bypass the validation for server certificates
--sslAllowInvalidHostnames bypass the validation for server name
--sslFIPSMode use FIPS mode of the installed openssl library
authentication options:
-u, --username=<username> username for authentication
-p, --password=<password> password for authentication
--authenticationDatabase=<database-name> database that holds the user's credentials
--authenticationMechanism=<mechanism> authentication mechanism to use
uri options:
--uri=mongodb-uri mongodb uri connection string
namespace options:
-d, --db=<database-name> database to use when restoring from a BSON file
-c, --collection=<collection-name> collection to use when restoring from a BSON file
--excludeCollection=<collection-name> DEPRECATED; collection to skip over during restore (may be specified multiple times to exclude additional collections)
--excludeCollectionsWithPrefix=<collection-prefix> DEPRECATED; collections to skip over during restore that have the given prefix (may be specified multiple times to exclude additional prefixes)
--nsExclude=<namespace-pattern> exclude matching namespaces
--nsInclude=<namespace-pattern> include matching namespaces
--nsFrom=<namespace-pattern> rename matching namespaces, must have matching nsTo
--nsTo=<namespace-pattern> rename matched namespaces, must have matching nsFrom
input options:
--objcheck validate all objects before inserting
--oplogReplay replay oplog for point-in-time restore
--oplogLimit=<seconds>[:ordinal] only include oplog entries before the provided Timestamp
--oplogFile=<filename> oplog file to use for replay of oplog
--archive=<filename> restore dump from the specified archive file. If flag is specified without a value, archive is read from stdin
--restoreDbUsersAndRoles restore user and role definitions for the given database
--dir=<directory-name> input directory, use '-' for stdin
--gzip decompress gzipped input
restore options:
--drop drop each collection before import
--dryRun view summary without importing anything. recommended with verbosity
--writeConcern=<write-concern> write concern options e.g. --writeConcern majority, --writeConcern '{w: 3, wtimeout: 500, fsync: true, j: true}'
--noIndexRestore don't restore indexes
--noOptionsRestore don't restore collection options
--keepIndexVersion don't update index version
--maintainInsertionOrder preserve order of documents during restoration
-j, --numParallelCollections= number of collections to restore in parallel (4 by default) (default: 4)
--numInsertionWorkersPerCollection= number of insert operations to run concurrently per collection (1 by default) (default: 1)
--stopOnError stop restoring if an error is encountered on insert (off by default)
--bypassDocumentValidation bypass document validation
--preserveUUID preserve original collection UUIDs (off by default, requires drop)La restauration de collections spécifiques dans MongoDB peut être effectuée à l'aide de la collection de paramètres dans mongorestore. Supposons que vous ayez une base de données de commandes, à l'intérieur de la base de données de commandes, il y a des collections comme indiqué ci-dessous :
my_mongodb_0:PRIMARY> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
orders 0.000GB
my_mongodb_0:PRIMARY> use orders;
my_mongodb_0:PRIMARY> show collections;
order_details
orders
stockNous avons déjà planifié une sauvegarde de la base de données des commandes et nous souhaitons restaurer la collection de stock dans une nouvelle base de données order_new sur le même serveur. Si vous souhaitez utiliser l'option --collection, vous devez transmettre le nom de la collection en tant que paramètre de mongorestore ou vous pouvez utiliser l'option --nsInclude={db}.{collection} si vous n'avez pas spécifié le chemin d'accès au fichier de collection .
example@sqldat.com:~/dump/orders# mongorestore -umongoadmin --authenticationDatabase admin --db order_new --collection stock /root/dump/orders/stock.bson
Enter password:
2020-03-09T04:06:29.100+0000 checking for collection data in /root/dump/orders/stock.bson
2020-03-09T04:06:29.110+0000 reading metadata for order_new.stock from /root/dump/orders/stock.metadata.json
2020-03-09T04:06:29.134+0000 restoring order_new.stock from /root/dump/orders/stock.bson
2020-03-09T04:06:29.202+0000 no indexes to restore
2020-03-09T04:06:29.203+0000 finished restoring order_new.stock (1 document)
2020-03-09T04:06:29.203+0000 doneVous pouvez vérifier la collection dans la base de données order_new comme indiqué ci-dessous :
my_mongodb_0:PRIMARY> use order_new;
switched to db order_new
my_mongodb_0:PRIMARY> show collections;
stockComment pouvons-nous restaurer à l'aide de mongodump dans ClusterControl
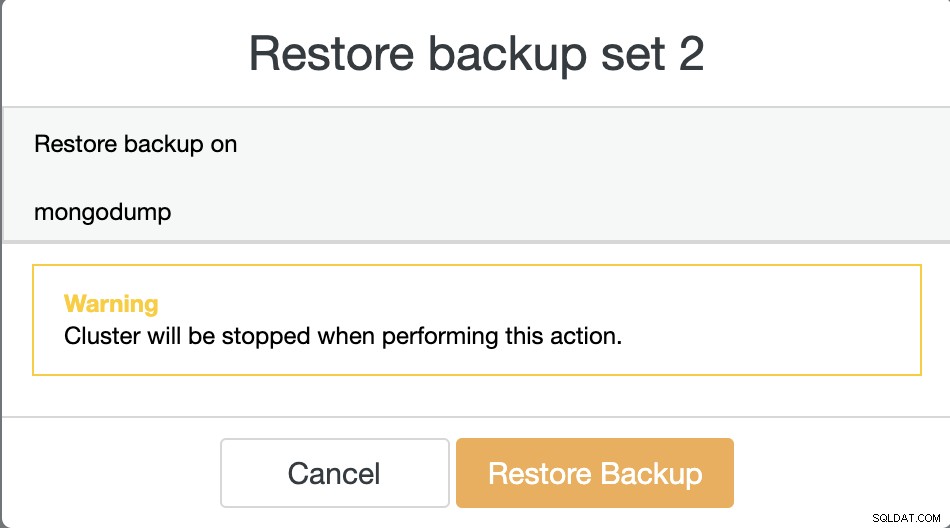
La restauration d'un vidage de sauvegarde via ClusterControl est simple, il vous suffit de 2 étapes pour restaurer la sauvegarde. Il y aura beaucoup de fichiers de sauvegarde dans la liste si vous avez activé votre planification de sauvegarde, certaines informations sur les sauvegardes peuvent être très utiles. Par exemple, l'état de la sauvegarde qui indique si la sauvegarde s'est terminée / a échoué, la méthode de sauvegarde utilisée, la liste des bases de données et la taille du vidage. Les étapes pour restaurer les données MongoDB via ClusterControl sont les suivantes :
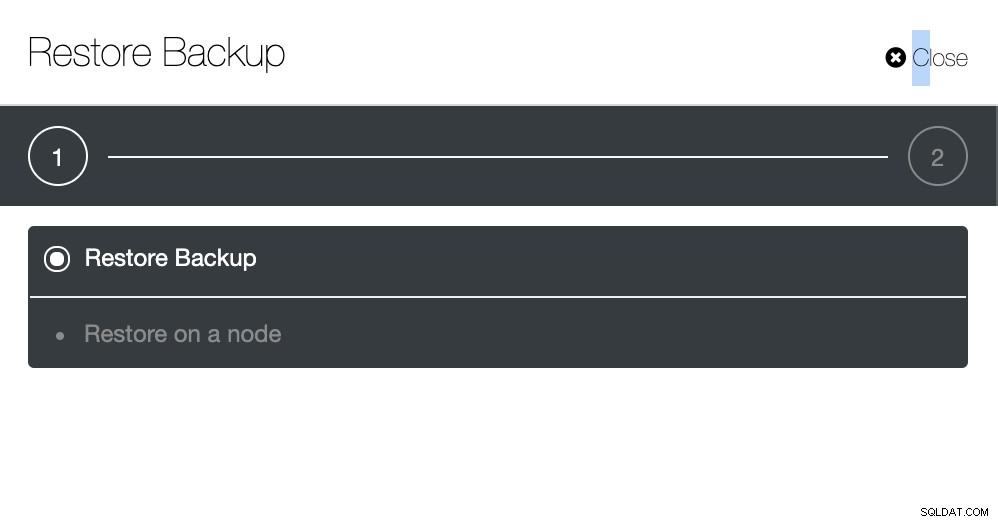
Première étape
Suivez les invites pour restaurer la sauvegarde sur un nœud comme indiqué ci-dessous...
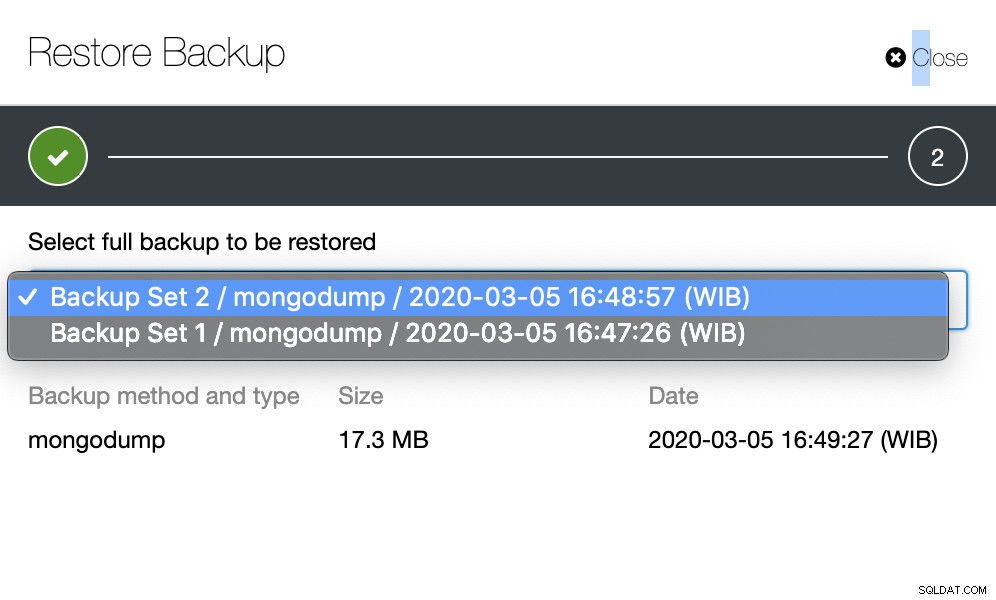
Étape 2
Vous devez choisir quelle sauvegarde doit être restaurée.
Étape 3
Revoir le résumé...