L'équilibrage de charge de la base de données distribue les requêtes client simultanées à plusieurs serveurs de base de données afin de réduire la quantité de charge sur un seul serveur. Cela peut améliorer considérablement les performances de votre base de données. Heureusement, MongoDB peut gérer les demandes de plusieurs clients pour lire et écrire les mêmes données simultanément par défaut. Il utilise des mécanismes de contrôle de la concurrence et des protocoles de verrouillage pour assurer la cohérence des données à tout moment.
De cette manière, MongoDB garantit également que tous les clients obtiennent une vue cohérente des données à tout moment. Grâce à cette fonctionnalité intégrée de traitement des demandes de plusieurs clients, vous n'avez pas à vous soucier d'ajouter un équilibreur de charge externe au-dessus de vos serveurs MongoDB. Cependant, si vous souhaitez toujours améliorer les performances de votre base de données à l'aide de l'équilibrage de charge, voici quelques moyens d'y parvenir.
Mise à l'échelle verticale de MongoDB
En termes simples, la mise à l'échelle verticale signifie ajouter plus de ressources à votre serveur pour gérer le chargement. Comme tous les systèmes de base de données, MongoDB préfère plus de RAM et de capacité d'E/S. C'est le moyen le plus simple d'augmenter les performances de MongoDB sans répartir la charge sur plusieurs serveurs. La mise à l'échelle verticale de la base de données MongoDB comprend généralement l'augmentation de la capacité du processeur ou de la capacité du disque et l'augmentation du débit (opérations d'E/S). En ajoutant plus de ressources, votre serveur mongo devient plus capable de gérer les demandes de plusieurs clients. Ainsi, un meilleur équilibrage de charge pour votre base de données.
L'inconvénient de l'utilisation de cette approche est la limitation technique de l'ajout de ressources à un seul système. De plus, tous les fournisseurs de cloud ont des limitations sur l'ajout de nouvelles configurations matérielles. L'autre inconvénient de cette approche est un point de défaillance unique. Dans cette approche, toutes vos données sont stockées dans un seul système, ce qui peut entraîner une perte permanente de vos données.
Mise à l'échelle horizontale de MongoDB
La mise à l'échelle horizontale consiste à diviser votre base de données en morceaux et à les stocker sur plusieurs serveurs. Le principal avantage de cette approche est que vous pouvez ajouter des serveurs supplémentaires à la volée pour augmenter les performances de votre base de données sans aucun temps d'arrêt. MongoDB fournit une mise à l'échelle horizontale via le sharding. Le partitionnement MongoDB offre une capacité supplémentaire pour répartir la charge d'écriture sur plusieurs serveurs (fragments). Ici, chaque fragment peut être considéré comme une base de données indépendante et la collection de tous les fragments peut être considérée comme une grande base de données logique. Le sharding permet à votre MongoDB de distribuer les données sur plusieurs serveurs pour gérer efficacement les demandes simultanées des clients. Par conséquent, cela augmente le débit de lecture et d'écriture de votre base de données.
Partage MongoDB
Une partition peut être une seule instance mongod ou un jeu de réplicas contenant le sous-ensemble de la base de données fragmentée mongo. Vous pouvez convertir un fragment en jeu de réplicas pour garantir une haute disponibilité des données et la redondance.
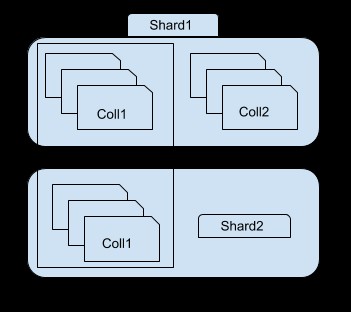
Comme vous pouvez le voir dans l'image ci-dessus, le fragment 1 contient un sous-ensemble de collection 1 et ensemble collection2, tandis que le fragment 2 ne contient qu'un autre sous-ensemble de collection1. Vous pouvez accéder à chaque fragment à l'aide de l'instance mongos. Par exemple, si vous vous connectez à l'instance shard1, vous ne pourrez voir/accéder qu'à un sous-ensemble de collection1.
Mongos
Mongos est le routeur de requête qui fournit l'accès au cluster partitionné pour les applications clientes. Vous pouvez avoir plusieurs instances mongos pour un meilleur équilibrage de charge. Par exemple, dans votre cluster de production, vous pouvez avoir une instance mongos pour chaque serveur d'applications. Maintenant, ici, vous pouvez utiliser un équilibreur de charge externe, qui redirigera la demande de votre serveur d'application vers l'instance mongos appropriée. Lors de l'ajout de telles configurations à votre serveur de production, assurez-vous que la connexion de n'importe quel client se connecte toujours à la même instance mongos à chaque fois, car certaines ressources mongo telles que les curseurs sont spécifiques à l'instance mongos.
Serveurs de configuration
Les serveurs de configuration stockent les paramètres de configuration et les métadonnées de votre cluster. À partir de la version 3.4 de MongoDB, vous devez déployer des serveurs de configuration en tant que jeu de répliques. Si vous activez le partitionnement dans un environnement de production, il est obligatoire d'utiliser trois serveurs de configuration distincts, chacun sur des machines différentes.
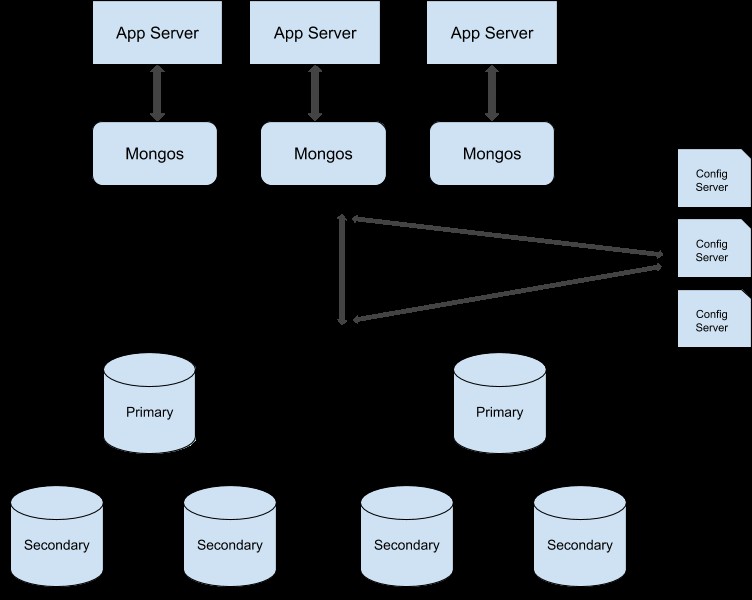
Vous pouvez suivre ce guide pour convertir votre cluster de jeu de réplicas en cluster fragmenté. Voici l'exemple d'illustration d'un cluster de production partagé :
Équilibrage de charge MongoDB à l'aide de la réplication
Parfois, la réplication MongoDB peut être utilisée pour gérer plus de trafic des clients et pour réduire la charge sur le serveur principal. Pour ce faire, vous pouvez demander aux clients de lire à partir des serveurs secondaires au lieu du serveur principal. Cela peut réduire la charge sur le serveur principal, car toutes les demandes de lecture provenant des clients seront traitées par des serveurs secondaires, et le serveur principal ne s'occupera que des demandes d'écriture.
Ce qui suit est la commande pour définir la préférence de lecture sur secondaire :
db.getMongo().setReadPref('secondary')Vous pouvez également spécifier des balises pour cibler des secondaires spécifiques lors du traitement des requêtes de lecture.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Ici, MongoDB essaiera de trouver le nœud secondaire avec la valeur de balise de centre de données comme APAC. S'il est trouvé, Mongo servira les demandes de lecture de tous les secondaires avec la balise datacenter :"APAC". S'il n'est pas trouvé, Mongo essaiera de trouver des secondaires avec la région de balise :"Est". Si toujours aucun secondaire n'est trouvé, alors {} fonctionnera comme cas par défaut, et Mongo servira les demandes de tous les secondaires éligibles.
Cependant, cette approche d'équilibrage de charge n'est pas recommandée pour augmenter le débit de lecture. Parce que tout mode de préférence de lecture autre que principal peut renvoyer d'anciennes données en cas de mises à jour d'écriture récentes sur le serveur principal. Habituellement, le serveur principal prend un certain temps pour gérer les demandes d'écriture et propager les modifications aux serveurs secondaires. Pendant ce temps, si quelqu'un demande une opération de lecture sur les mêmes données, le serveur secondaire renverra des données obsolètes car elles ne sont pas synchronisées avec le serveur principal. Vous pouvez utiliser cette approche si votre application nécessite beaucoup d'opérations de lecture par rapport aux opérations d'écriture.
Conclusion
Comme MongoDB peut gérer les requêtes simultanées par lui-même, il n'est pas nécessaire d'ajouter un équilibreur de charge dans votre cluster MongoDB. Pour équilibrer la charge des demandes du client, vous pouvez choisir une mise à l'échelle verticale ou une mise à l'échelle horizontale car il n'est pas conseillé d'utiliser des secondaires pour faire évoluer vos opérations de lecture et d'écriture. La mise à l'échelle verticale peut atteindre les limites techniques, comme indiqué ci-dessus. Par conséquent, il convient aux applications à petite échelle. Pour les grandes applications, la mise à l'échelle horizontale via le partitionnement est la meilleure approche pour équilibrer la charge des opérations de lecture et d'écriture.



