ClusterControl est programmé avec un certain nombre d'algorithmes de récupération pour répondre automatiquement aux différents types de pannes courantes affectant vos systèmes de base de données. Il comprend différents types de topologies de base de données et de gestion des processus liés à la base de données pour vous aider à déterminer la meilleure façon de récupérer le cluster. D'une certaine manière, ClusterControl améliore la disponibilité de votre base de données.
Certains gestionnaires de topologie ne couvrent que la récupération de cluster comme MHA, Orchestrator et mysqlfailover mais vous devez gérer vous-même la récupération de nœud. ClusterControl prend en charge la récupération au niveau du cluster et du nœud.
Options de configuration
Il existe deux composants de récupération pris en charge par ClusterControl, à savoir :
- Cluster - Tentative de restauration d'un cluster à un état opérationnel
- Nœud - Tentative de restauration d'un nœud à un état opérationnel
Ces deux composants sont les éléments les plus importants pour s'assurer que la disponibilité du service est aussi élevée que possible. Si vous avez déjà un gestionnaire de topologie au-dessus de ClusterControl, vous pouvez désactiver la fonction de récupération automatique et laisser un autre gestionnaire de topologie le gérer pour vous. Vous avez toutes les possibilités avec ClusterControl.
La fonction de récupération automatique peut être activée et désactivée avec une simple bascule ON/OFF, et elle fonctionne pour la récupération de cluster ou de nœud. Les icônes vertes signifient activées et les icônes rouges signifient désactivées. La capture d'écran suivante montre où vous pouvez le trouver dans la liste des clusters de bases de données :
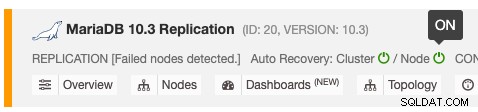
Il existe 3 paramètres ClusterControl qui peuvent être utilisés pour contrôler le comportement de récupération. Tous les paramètres sont par défaut sur true (définis avec un entier booléen 0 ou 1) :
- enable_autorecovery - Active la récupération du cluster et du nœud. Ce paramètre est le sur-ensemble de enable_cluster_recovery et enable_node_recovery. S'il est défini sur 0, les paramètres de sous-ensemble seront désactivés.
- enable_cluster_recovery - ClusterControl effectuera la récupération du cluster s'il est activé.
- enable_node_recovery - ClusterControl effectuera la récupération du nœud s'il est activé.
La récupération de cluster couvre la tentative de récupération pour faire apparaître la topologie complète du cluster. Par exemple, une réplication maître-esclave doit avoir au moins un maître actif à tout moment, quel que soit le nombre d'esclave(s) disponible(s). ClusterControl tente de corriger la topologie au moins une fois pour les clusters de réplication, mais à l'infini pour la réplication multi-maître comme NDB Cluster et Galera Cluster.
La récupération de nœud couvre le problème de récupération de nœud comme si un nœud était arrêté à l'insu de ClusterControl, par exemple, via la commande d'arrêt du système à partir de la console SSH ou tué par le processus OOM.
Récupération de nœud
ClusterControl est capable de récupérer un nœud de base de données en cas de panne intermittente en surveillant le processus et la connectivité aux nœuds de la base de données. Pour le processus, cela fonctionne de la même manière que systemd, où il s'assurera que le service MySQL est démarré et en cours d'exécution, sauf si vous l'avez intentionnellement arrêté via l'interface utilisateur de ClusterControl.
Si le nœud revient en ligne, ClusterControl établira une connexion avec le nœud de la base de données et effectuera les actions nécessaires. Voici ce que ferait ClusterControl pour récupérer un nœud :
- Il attendra que systemd/chkconfig/init démarre les services/processus surveillés pendant 30 secondes
- Si les services/processus surveillés sont toujours en panne, ClusterControl essaiera de démarrer automatiquement le service de base de données.
- Si ClusterControl est incapable de récupérer les services/processus surveillés, une alarme sera déclenchée.
Notez que si un arrêt de la base de données est initié par l'utilisateur, ClusterControl ne tentera pas de récupérer le nœud particulier. Il s'attend à ce que l'utilisateur le redémarre via l'interface utilisateur de ClusterControl en accédant à Node -> Node Actions -> Start Node ou en utilisant explicitement la commande du système d'exploitation.
La récupération inclut tous les services liés à la base de données tels que ProxySQL, HAProxy, MaxScale, Keepalived, les exportateurs Prometheus et garbd. Une attention particulière aux exportateurs Prometheus où ClusterControl utilise un programme appelé "daemon" pour démoniser le processus d'exportation. ClusterControl essaiera de se connecter au port d'écoute de l'exportateur pour un contrôle de santé et une vérification. Ainsi, il est recommandé d'ouvrir les ports d'exportation de ClusterControl et du serveur Prometheus pour s'assurer qu'il n'y a pas de fausse alarme lors de la récupération.
Récupération de cluster
ClusterControl comprend la topologie de la base de données et suit les meilleures pratiques pour effectuer la restauration. Pour un cluster de base de données doté d'une tolérance aux pannes intégrée comme Galera Cluster, NDB Cluster et MongoDB Replicaset, le processus de basculement sera effectué automatiquement par le serveur de base de données via le calcul du quorum, la pulsation et le changement de rôle (le cas échéant). ClusterControl surveille le processus et apporte les ajustements nécessaires à la visualisation, comme refléter les modifications sous la vue Topologie et ajuster le composant de surveillance et de gestion pour le nouveau rôle, par exemple, le nouveau nœud principal dans un jeu de répliques.
Pour les technologies de base de données qui n'ont pas de tolérance aux pannes intégrée avec récupération automatique comme la réplication MySQL/MariaDB et la réplication en continu PostgreSQL/TimescaleDB, ClusterControl effectuera les procédures de récupération en suivant les meilleures pratiques fournies par le fournisseur de bases de données. Si la récupération échoue, l'intervention de l'utilisateur est requise et, bien sûr, vous recevrez une notification d'alarme à ce sujet.
Dans une topologie mixte/hybride, par exemple un esclave asynchrone qui est attaché à un cluster Galera ou un cluster NDB, le nœud sera récupéré par ClusterControl si la récupération du cluster est activée.
La récupération de cluster ne s'applique pas au serveur MySQL autonome. Cependant, il est recommandé d'activer les récupérations de nœud et de cluster pour ce type de cluster dans l'interface utilisateur de ClusterControl.
Réplication MySQL/MariaDB
ClusterControl prend en charge la récupération de la configuration de réplication MySQL/MariaDB suivante :
- Maître-esclave avec MySQL GTID
- Maître-esclave avec MariaDB GTID
- Maître-esclave avec sans GTID (à la fois MySQL et MariaDB)
- Maître-maître avec MySQL GTID
- Maître-maître avec MariaDB GTID
- Esclave asynchrone attaché à un cluster Galera
ClusterControl respectera les paramètres suivants lors de la récupération du cluster :
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Pour plus de détails sur chacun des paramètres, reportez-vous à la page de documentation.
ClusterControl obéira aux règles suivantes lors de la surveillance et de la gestion d'une réplication maître-esclave :
- Tous les nœuds seront démarrés avec read_only=ON et super_read_only=ON (quel que soit son rôle).
- Un seul maître (read_only=OFF) est autorisé à fonctionner à un moment donné.
- Appuyez-vous sur la variable MySQL report_host pour mapper la topologie.
- S'il y a deux nœuds ou plus qui ont read_only=OFF à la fois, ClusterControl définira automatiquement read_only=ON sur les deux maîtres, pour les protéger contre les écritures accidentelles. L'intervention de l'utilisateur est nécessaire pour sélectionner le maître réel en désactivant la lecture seule. Accédez à Nœuds -> Actions de nœud -> Désactiver la lecture seule.
Si le maître actif tombe en panne, ClusterControl tentera d'effectuer le basculement du maître dans l'ordre suivant :
- Après 3 secondes d'inaccessibilité du maître, ClusterControl déclenchera une alarme.
- Vérifier la disponibilité des esclaves, au moins un des esclaves doit être accessible par ClusterControl.
- Choisissez l'esclave comme candidat pour devenir maître.
- ClusterControl calculera la probabilité de transactions errantes si GTID est activé.
- Si aucune transaction errante n'est détectée, le choix sera promu comme nouveau maître.
- Créer et accorder un utilisateur de réplication à utiliser par les esclaves.
- Changer le maître pour tous les esclaves qui pointaient vers l'ancien maître vers le maître nouvellement promu.
- Démarrer l'esclave et activer la lecture seule.
- Vider les journaux sur tous les nœuds.
- Si la promotion de l'esclave échoue, ClusterControl abandonnera la tâche de récupération. Une intervention de l'utilisateur ou un redémarrage du service cmon est nécessaire pour déclencher à nouveau la tâche de récupération.
- Lorsque l'ancien maître est à nouveau disponible, il sera démarré en lecture seule et ne fera pas partie de la réplication. L'intervention de l'utilisateur est requise.
En même temps, les alarmes suivantes seront déclenchées :
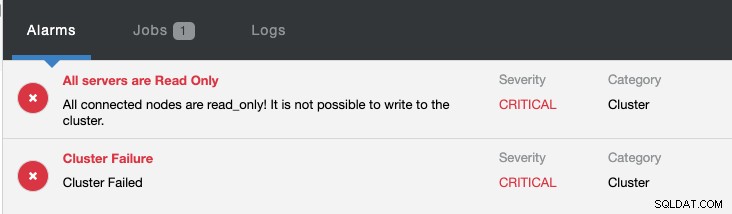
Consultez Introduction au basculement pour la réplication MySQL - le blog 101 et le basculement automatique de la réplication MySQL - Nouveau dans ClusterControl 1.4 pour obtenir plus d'informations sur la configuration et la gestion du basculement de la réplication MySQL avec ClusterControl.
Réplication en continu PostgreSQL/TimescaleDB
ClusterControl prend en charge la récupération de la configuration de réplication PostgreSQL suivante :
- Réplication en continu PostgreSQL
- Réplication en continu TimescaleDB
ClusterControl respectera les paramètres suivants lors de la récupération du cluster :
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Pour plus de détails sur chacun des paramètres, reportez-vous à la page de documentation.
ClusterControl obéira aux règles suivantes pour gérer et surveiller une configuration de réplication en continu PostgreSQL :
- wal_level est défini sur "replica" (ou "hot_standby" selon la version de PostgreSQL).
- La variable archive_mode est définie sur ON sur le maître.
- Définissez le fichier recovery.conf sur les nœuds esclaves, ce qui transforme le nœud en un serveur de secours avec la lecture seule activée.
En cas de panne du maître actif, ClusterControl tentera d'effectuer la récupération du cluster dans l'ordre suivant :
- Après 10 secondes d'inaccessibilité du maître, ClusterControl déclenchera une alarme.
- Après 10 secondes de délai d'attente normal, ClusterControl lancera la tâche de basculement maître.
- Échantillonnez replayLocation et receiveLocation sur tous les nœuds disponibles pour déterminer le nœud le plus avancé.
- Promouvoir le nœud le plus avancé en tant que nouveau maître.
- Arrêtez les esclaves.
- Vérifiez l'état de la synchronisation avec pg_rewind.
- Redémarrage des esclaves avec le nouveau maître.
- Si la promotion de l'esclave échoue, ClusterControl abandonnera la tâche de récupération. Une intervention de l'utilisateur ou un redémarrage du service cmon est nécessaire pour déclencher à nouveau la tâche de récupération.
- Lorsque l'ancien maître sera à nouveau disponible, il sera forcé de s'arrêter et ne fera pas partie de la réplication. L'intervention de l'utilisateur est requise. Voir plus bas.
Lorsque l'ancien maître revient en ligne, si le service PostgreSQL est en cours d'exécution, ClusterControl forcera l'arrêt du service PostgreSQL. Il s'agit de protéger le serveur contre les écritures accidentelles, car il serait démarré sans fichier de récupération (recovery.conf), ce qui signifie qu'il serait accessible en écriture. Vous devez vous attendre à ce que les lignes suivantes apparaissent dans postgresql-{day}.log :
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downLe PostgreSQL a été démarré après la remise en ligne du serveur vers 05:06:10 mais ClusterControl effectue un arrêt rapide 17 secondes plus tard vers 05:06:27. Si c'est quelque chose que vous ne voudriez pas que ce soit, vous pouvez désactiver momentanément la récupération de nœud pour ce cluster.
Consultez Basculement automatique de la réplication Postgres et Basculement pour la réplication PostgreSQL 101 pour obtenir plus d'informations sur la configuration et la gestion du basculement de la réplication PostgreSQL avec ClusterControl.
Conclusion
La récupération automatique de ClusterControl comprend la topologie du cluster de base de données et est capable de restaurer un cluster en panne ou dégradé vers un cluster entièrement opérationnel, ce qui améliorera considérablement la disponibilité du service de base de données. Essayez ClusterControl maintenant et atteignez vos neuf en matière de SLA et de disponibilité de la base de données. Vous ne connaissez pas vos neuf ? Découvrez ce super calculateur de neuf.



