Les systèmes de base de données sont des composants cruciaux dans le cycle de toute application en cours d'exécution. Chaque organisation qui les implique a donc pour mandat d'assurer le bon fonctionnement de ces DBM grâce à une surveillance cohérente et à la gestion des revers mineurs avant qu'ils ne dégénèrent en énormes complications pouvant entraîner un temps d'arrêt de l'application ou un ralentissement des performances.
Vous pouvez vous demander comment savoir si la base de données va vraiment avoir un problème alors qu'elle fonctionne normalement ? Eh bien, c'est ce dont nous allons discuter dans cet article et nous l'appelons benchmarking. L'analyse comparative consiste essentiellement à exécuter un ensemble de requêtes avec des données de test ainsi que des ressources pour déterminer si ces paramètres répondent au niveau de performance attendu.
MongoDB n'a pas de méthodologie d'analyse comparative standard, nous devons donc résoudre les requêtes de test sur notre propre matériel. Bien que vous puissiez également obtenir des chiffres impressionnants à partir du processus de référence, vous devez être prudent car cela peut être un cas différent lors de l'exécution de votre base de données avec de vraies requêtes.
L'idée derrière l'analyse comparative est d'avoir une idée générale de la façon dont les différentes options de configuration affectent les performances, comment vous pouvez modifier certaines de ces configurations pour obtenir des performances maximales et estimer le coût de l'amélioration de cette implémentation. En outre, les applications se développent avec le temps en termes d'utilisateurs et probablement de quantité de données à servir, il est donc nécessaire de planifier la capacité avant cette date. Après avoir réalisé une tendance à la hausse des données, vous devez effectuer des analyses comparatives sur la façon dont vous répondrez aux exigences de ces vastes données croissantes.
Considérations sur l'analyse comparative MongoDB
- Sélectionnez des charges de travail représentatives des applications modernes d'aujourd'hui. Les applications modernes deviennent chaque jour plus complexes et cela se répercute sur les structures de données. C'est-à-dire que la présentation des données a également changé avec le temps, par exemple en stockant des champs simples dans des objets et des tableaux. Il n'est pas assez facile de travailler avec ces données avec des configurations de base de données par défaut ou plutôt inférieures aux normes, car cela peut dégénérer en problèmes tels qu'une faible latence et des opérations à faible débit impliquant des données complexes. Lors de l'exécution d'un benchmark, vous devez donc utiliser des données qui sont une présentation claire de votre application.
- Vérifiez les écritures. Assurez-vous toujours que toutes les écritures de données ont été effectuées de manière à ne permettre aucune perte de données. Il s'agit d'améliorer l'intégrité des données en s'assurant que les données sont cohérentes et qu'elles sont plus applicables, en particulier dans l'environnement de production.
- Utilisez des volumes de données qui sont une représentation d'ensembles de données "big data" qui dépasseront certainement la capacité de RAM d'un nœud individuel. Lorsque la charge de travail de test est importante, cela vous aidera à prévoir les attentes futures en matière de performances de votre base de données, donc commencez à planifier la capacité suffisamment tôt.
Méthodologie
Notre test de référence impliquera de grandes données de localisation qui peuvent être téléchargées à partir d'ici et nous utiliserons le logiciel Robo3t pour manipuler nos données et collecter les informations dont nous avons besoin. Le dossier contient plus de 500 documents, ce qui est bien suffisant pour notre test. Nous utilisons MongoDB version 4.0 sur un serveur dédié Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore 3,4 GHz avec 32 Go de RAM, un disque rotatif Western Digital WD Caviar RE4 1 To et un SSD Smart XceedIOPS 256 Go. Nous avons inséré les 500 premiers documents.
Nous avons exécuté les commandes d'insertion ci-dessous
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:0})
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:1})Écrivez votre préoccupation
Write concern décrit le niveau d'accusé de réception demandé à MongoDB pour les opérations d'écriture dans ce cas sur une MongoDB autonome. Pour une opération à haut débit, si cette valeur est définie sur faible, les appels d'écriture seront si rapides que cela réduira la latence de la requête. D'autre part, si la valeur est élevée, les appels d'écriture sont lents et augmentent par conséquent la latence de la requête. Une explication simple à cela est que lorsque la valeur est faible, vous n'êtes pas préoccupé par la possibilité de perdre certaines écritures en cas de plantage mongod, d'erreur réseau ou de défaillance système anonyme. Une limitation dans ce cas sera que vous ne saurez pas si ces écritures ont réussi. D'un autre côté, si le problème d'écriture est élevé, il y a une invite de gestion d'erreur et donc les écritures seront acquittées. Un accusé de réception est simplement un accusé de réception indiquant que le serveur a accepté l'écriture à traiter.
 Lorsque le problème d'écriture est défini sur élevé
Lorsque le problème d'écriture est défini sur élevé  Lorsque le problème d'écriture est défini sur faible
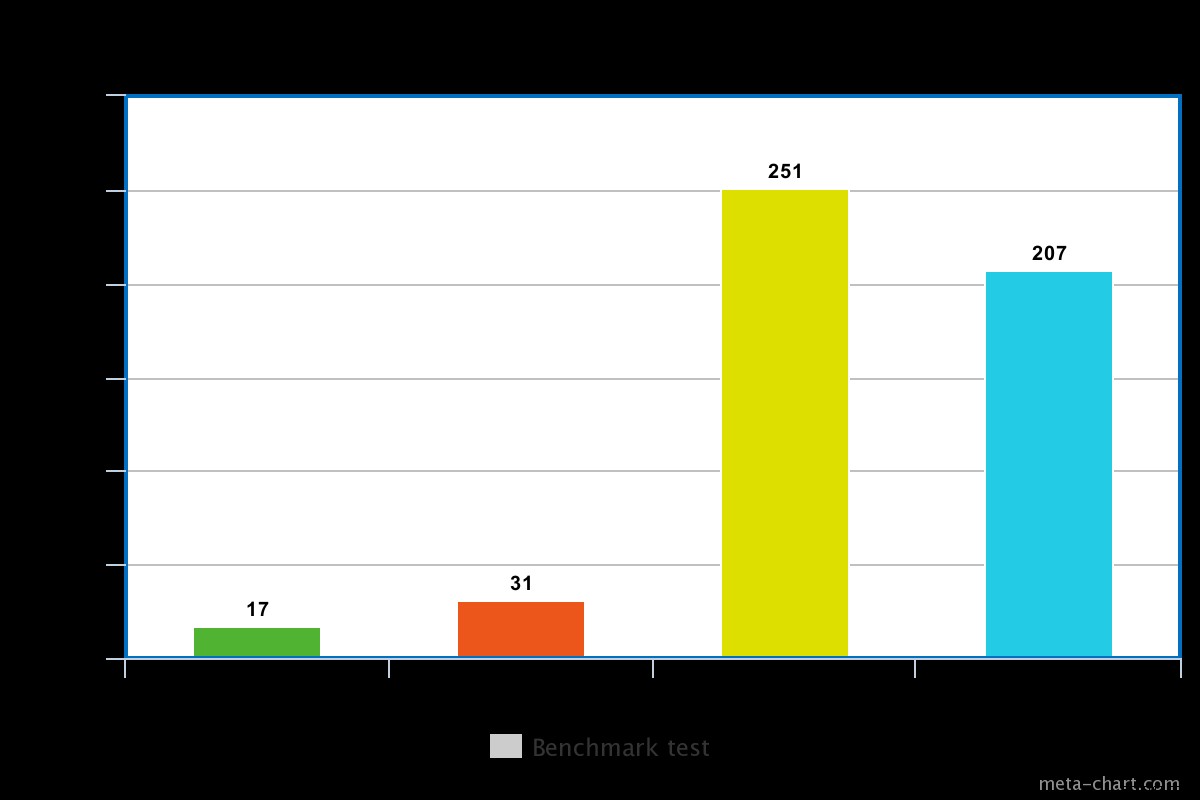
Lorsque le problème d'écriture est défini sur faible Dans notre test, la préoccupation d'écriture définie sur faible a entraîné l'exécution de la requête en min de 0,013 ms et max de 0,017 ms. Dans ce cas, l'acquittement de base de l'écriture est désactivé mais on peut toujours obtenir des informations concernant les exceptions de socket et toute erreur réseau qui aurait pu être déclenchée.
Lorsque le problème d'écriture est élevé, il faut presque le double de temps pour revenir, le temps d'exécution étant de 0,027 ms min et 0,031 ms max. L'accusé de réception dans ce cas est garanti mais pas à 100%, il a atteint le journal du disque. Dans ce cas, les risques de perte en écriture sont donc de 50 % en raison de la fenêtre de 100 ms pendant laquelle le journal peut ne pas être vidé sur le disque.
Journalisation
Il s'agit d'une technique qui garantit l'absence de perte de données en assurant la durabilité en cas de panne. Ceci est réalisé grâce à une journalisation en écriture anticipée dans des fichiers journaux sur disque. Il est plus efficace lorsque la préoccupation d'écriture est élevée.
Pour un disque en rotation, le temps d'exécution avec la journalisation activée est un peu élevé, par exemple dans notre test, il était d'environ 0,251 ms pour la même opération ci-dessus.

Le temps d'exécution pour un SSD est cependant un peu inférieur pour la même commande. Lors de notre test, il était d'environ 0,207 ms, mais selon la nature des données, cela pouvait parfois être 3 fois plus rapide qu'un disque en rotation.

Lorsque la journalisation est activée, elle confirme que des écritures ont été effectuées dans le journal et garantit ainsi la durabilité des données. Par conséquent, l'opération d'écriture survivra à un arrêt de mongod et garantit que l'opération d'écriture est durable.
Pour une opération à haut débit, vous pouvez réduire de moitié les temps de requête en définissant w=0. Sinon, si vous avez besoin d'être sûr que les données ont été enregistrées ou qu'elles le seront en cas de retour à la vie après un échec, vous devez définir le w=1.
 Severalnines Devenir un administrateur de base de données MongoDB – Mettre MongoDB en productionDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et échelle MongoDBDélécharger gratuitement
Severalnines Devenir un administrateur de base de données MongoDB – Mettre MongoDB en productionDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et échelle MongoDBDélécharger gratuitement Réplication
L'accusé de réception d'un problème d'écriture peut être activé pour plusieurs nœuds qui sont le nœud principal et certains nœuds secondaires au sein d'un jeu de réplicas. Cela sera caractérisé par quel entier est évalué au paramètre d'écriture. Par exemple, si w =3, Mongod doit s'assurer que la requête reçoit un acquittement du nœud principal et des 2 esclaves. Si vous essayez de définir une valeur supérieure à un et que le nœud n'est pas encore répliqué, une erreur s'affichera indiquant que l'hôte doit être répliqué.
La réplication s'accompagne d'un recul de latence tel que le temps d'exécution sera augmenté. Pour la requête simple ci-dessus, si w=3, le temps d'exécution moyen passe à 270 ms. Un facteur déterminant pour cela est la plage de temps de réponse entre les nœuds affectés par la latence du réseau, la surcharge de communication entre les 3 nœuds et la congestion. De plus, les trois nœuds attendent que l'autre se termine avant de renvoyer le résultat. Dans un déploiement en production, vous n'aurez donc pas besoin d'impliquer autant de nœuds si vous souhaitez améliorer les performances. MongoDB est responsable de la sélection des nœuds à reconnaître, sauf s'il existe une spécification dans le fichier de configuration à l'aide de balises.
Disque rotatif vs disque à semi-conducteurs
Comme mentionné ci-dessus, le disque SSD est assez rapide que le disque en rotation en fonction des données impliquées. Parfois, cela peut être 3 fois plus rapide, ce qui vaut la peine d'être payé si nécessaire. Cependant, il sera plus coûteux d'utiliser un SSD, en particulier lorsqu'il s'agit de données volumineuses. MongoDB a le mérite de prendre en charge le stockage des bases de données dans des répertoires qui peuvent être montés, d'où une chance d'utiliser un SSD. L'utilisation d'un SSD et l'activation de la journalisation constituent une excellente optimisation.
Conclusion
L'expérience était certaine que les problèmes d'écriture désactivés réduisaient le temps d'exécution d'une requête au détriment des risques de perte de données. D'autre part, lorsque le problème d'écriture est activé, le temps d'exécution est presque 2 fois plus long lorsqu'il est désactivé, mais il est certain que les données ne seront pas perdues. De plus, nous sommes en mesure de justifier que le SSD est plus rapide qu'un disque Spinning. Cependant, pour assurer la pérennité des données en cas de panne du système, il est conseillé d'activer le souci d'écriture. Lorsque vous activez le problème d'écriture pour un jeu de réplicas, ne définissez pas un nombre trop élevé, car cela pourrait entraîner une dégradation des performances du côté de l'application.



