JOINS multiples dans une seule requête
Plusieurs JOINS sont normalement associés à plusieurs collections, mais vous devez avoir une compréhension de base du fonctionnement de INNER JOIN (voir mes précédents articles sur ce sujet). En plus de nos deux collections que nous avions auparavant; unités et étudiants, ajoutons une troisième collection et étiquetons-la sports. Remplir la collection sports avec les données ci-dessous :
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Nous aimerions, par exemple, renvoyer toutes les données d'un étudiant avec une valeur de champ _id égale à 1. Normalement, nous écrirons une requête pour extraire la valeur du champ _id de la collection des étudiants, puis utiliserons la valeur renvoyée pour rechercher données des deux autres collections. Par conséquent, ce ne sera pas la meilleure option, surtout si un grand nombre de documents est impliqué. Une meilleure approche serait d'utiliser la fonction SQL du programme Studio3T. Nous pouvons interroger notre MongoDB avec le concept SQL normal, puis essayer d'ajuster grossièrement le code shell Mongo résultant en fonction de nos spécifications. Par exemple, récupérons toutes les données avec _id égal à 1 de toutes les collections :
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Le document résultant sera :
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Depuis l'onglet Query code, le code MongoDB correspondant sera :
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);En regardant dans le document renvoyé, personnellement, je ne suis pas trop satisfait de la structure des données, en particulier avec les documents intégrés. Comme vous pouvez le voir, des champs _id sont renvoyés et pour les unités, nous n'avons peut-être pas besoin que le champ des notes soit intégré dans les unités.
Nous voudrions avoir un champ d'unités avec des unités intégrées et pas d'autres champs. Cela nous amène à la partie de mélodie grossière. Comme dans les articles précédents, copiez le code à l'aide de l'icône de copie fournie et accédez au volet d'agrégation, collez le contenu à l'aide de l'icône de collage.
Tout d'abord, l'opérateur $match devrait être la première étape, alors déplacez-le en première position et obtenez quelque chose comme ceci :
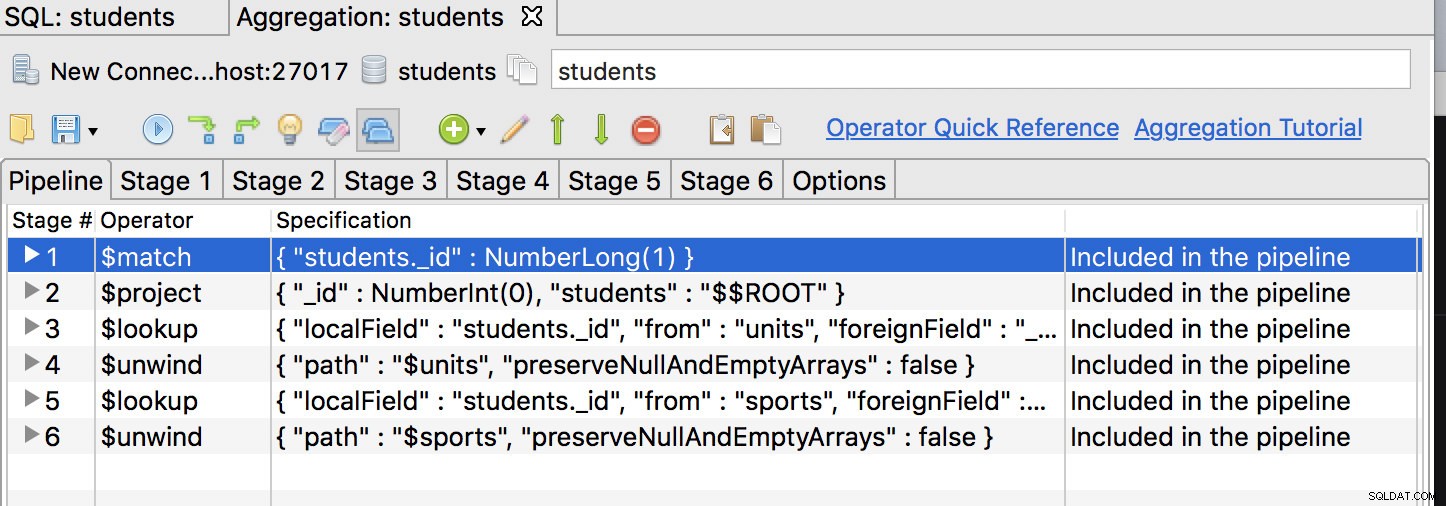
Cliquez sur l'onglet de la première étape et modifiez la requête pour :
{
"_id" : NumberLong(1)
}Nous devons ensuite modifier davantage la requête pour supprimer de nombreuses étapes d'intégration de nos données. Pour ce faire, nous ajoutons de nouveaux champs pour capturer les données des champs que nous voulons éliminer, c'est-à-dire :
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Comme vous pouvez le voir, dans le processus de réglage fin, nous avons introduit de nouvelles unités de champ qui écraseront le contenu du pipeline d'agrégation précédent avec des notes en tant que champ intégré. De plus, nous avons créé un champ _id pour indiquer que les données étaient en relation avec tous les documents des collections ayant la même valeur. La dernière étape de $project consiste à supprimer le champ _id dans le document sportif afin que nous puissions avoir des données présentées avec soin comme ci-dessous.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Nous pouvons également restreindre les champs à renvoyer du point de vue SQL. Par exemple, nous pouvons renvoyer le nom de l'étudiant, les unités que cet étudiant fait et le nombre de tournois joués en utilisant plusieurs JOINS avec le code ci-dessous :
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Cela ne nous donne pas le résultat le plus approprié. Donc, comme d'habitude, copiez-le et collez-le dans le volet d'agrégation. Nous peaufinons le code ci-dessous pour obtenir le résultat approprié.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Ce résultat d'agrégation du concept SQL JOIN nous donne une structure de données soignée et présentable illustrée ci-dessous.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Assez simple, non? Les données sont tout à fait présentables comme si elles étaient stockées dans une seule collection en tant que document unique.
JOINTURE EXTERNE GAUCHE
Le LEFT OUTER JOIN est normalement utilisé pour afficher des documents qui ne sont pas conformes à la relation la plus représentée. L'ensemble résultant d'une jointure LEFT OUTER contient toutes les lignes des deux collections qui répondent aux critères de la clause WHERE, comme un ensemble de résultats INNER JOIN. En outre, tous les documents de la collection de gauche qui n'ont pas de documents correspondants dans la collection de droite seront également inclus dans le jeu de résultats. Les champs sélectionnés dans le tableau de droite renverront des valeurs NULL. Cependant, tous les documents de la collection de droite, qui n'ont pas de critères correspondants de la collection de gauche, ne sont pas renvoyés.
Jetez un œil à ces deux collections :
étudiants
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Unités
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}Dans la collection des étudiants, nous n'avons pas la valeur du champ _id définie sur 3, mais dans la collection des unités, nous en avons. De même, il n'y a pas de valeur de champ _id 4 dans la collection d'unités. Si nous utilisons la collection d'étudiants comme option de gauche dans l'approche JOIN avec la requête ci-dessous :
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idAvec ce code, nous obtiendrons le résultat suivant :
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}Le deuxième document n'a pas de champ d'unités car il n'y avait pas de document correspondant dans la collection d'unités. Pour cette requête SQL, le code Mongo correspondant sera
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);Bien sûr, nous avons appris les ajustements, vous pouvez donc continuer et restructurer le pipeline d'agrégation pour obtenir le résultat final que vous souhaitez. SQL est un outil très puissant en matière de gestion de base de données. C'est un vaste sujet en soi, vous pouvez également essayer d'utiliser les clauses IN et GROUP BY pour obtenir le code correspondant à MongoDB et voir comment cela fonctionne.
Conclusion
S'habituer à une nouvelle technologie (de base de données) en plus de celle avec laquelle vous avez l'habitude de travailler peut prendre beaucoup de temps. Les bases de données relationnelles sont encore plus courantes que les bases de données non relationnelles. Néanmoins, avec l'introduction de MongoDB, les choses ont changé et les gens aimeraient l'apprendre le plus rapidement possible en raison de ses puissantes performances associées.
Apprendre MongoDB à partir de zéro peut être un peu fastidieux, mais nous pouvons utiliser la connaissance de SQL pour manipuler les données dans MongoDB, obtenir le code MongoDB relatif et l'affiner pour obtenir les résultats les plus appropriés. L'un des outils disponibles pour améliorer cela est Studio 3T. Il offre deux fonctionnalités importantes qui facilitent l'exploitation de données complexes, à savoir :la fonctionnalité de requête SQL et l'éditeur d'agrégation. Les requêtes de réglage fin vous permettront non seulement d'obtenir le meilleur résultat, mais également d'améliorer les performances en termes de gain de temps.



