Zones MongoDB
Pour comprendre les zones MongoDB, nous devons d'abord comprendre ce qu'est une zone :un groupe de partitions basé sur un ensemble spécifique de balises.
Les zones MongoDB aident à la distribution de morceaux basés sur des balises, entre les fragments. Tout le travail (lectures et écritures) lié aux documents d'une zone est effectué sur des partitions correspondant à cette zone.
Il peut y avoir différents scénarios dans lesquels les clusters partitionnés (basés sur des zones) peuvent s'avérer très utiles. Disons :
- Une application distribuée géographiquement peut nécessiter l'interface, ainsi que le magasin de données
- Une application possède une architecture à plusieurs niveaux, de sorte que certains enregistrements sont récupérés à partir d'un matériel de niveau supérieur (faible latence), tandis que d'autres peuvent être récupérés à partir d'un matériel de niveau inférieur (induisant une latence élevée)
Avantages de l'utilisation des zones MongoDB
Avec l'aide de MongoDB Zones, les DBA peuvent créer des solutions de stockage hiérarchisées qui prennent en charge le cycle de vie des données, avec des données fréquemment utilisées stockées en mémoire, des données moins utilisées stockées sur le serveur et, au moment opportun, des données archivées mises hors ligne.
Comment configurer des zones
Dans les clusters partitionnés, vous pouvez créer des zones qui représentent un groupe de partitions et associer une ou plusieurs plages de valeurs de clé de partition à cette zone. MongoDB achemine toutes les lectures et toutes les écritures qui entrent dans une plage de zone uniquement vers les fragments à l'intérieur de la zone. Vous pouvez associer chaque zone à une ou plusieurs partitions du cluster et une partition peut être associée à n'importe quel nombre de zones.
Certains des modèles de déploiement les plus courants où les zones peuvent être appliquées sont les suivants :
- Isolez un sous-ensemble spécifique de données sur un ensemble spécifique de partitions.
- En s'assurant que les données les plus pertinentes résident sur les partitions les plus proches géographiquement des serveurs d'applications.
- Acheminez les données vers les partitions en fonction des performances du matériel de la partition.
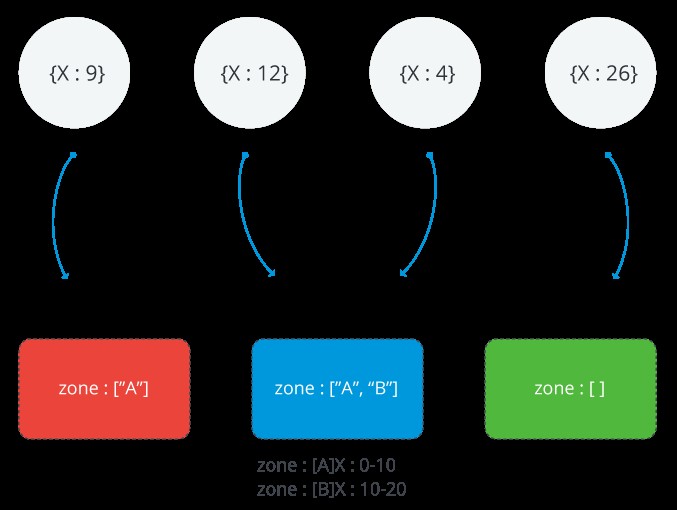
L'image suivante illustre un cluster partitionné avec trois partitions et deux zones. La zone A représente une plage avec une limite inférieure de 0 et une limite supérieure de 10. La zone B montre une plage avec une limite inférieure de 10 et une limite supérieure de 20. Les fragments ROUGE et BLEU ont la zone A. Shard BLUE a également la zone B. Shard GREEN n'a pas de zones associées. Le cluster est dans un état stable et aucun bloc ne viole aucune des zones
Portée d'une zone MongoDB
Chaque zone couvre une ou plusieurs plages de valeurs de clé de partition. Chaque plage couverte par une zone inclut toujours sa limite inférieure et exclut sa limite supérieure.
N'OUBLIEZ PAS : Les zones ne peuvent pas partager de plages et elles ne peuvent pas avoir de plages qui se chevauchent.
Ajouter des fragments à une zone
La méthode sh.addShardTag() est utilisée pour ajouter des zones à un fragment. Un seul fragment peut avoir plusieurs zones, et plusieurs fragments peuvent également avoir la même zone. L'exemple suivant ajoute la zone A à une partition.
sh.addShardTag("shard0000", "A")Supprimer des fragments d'une zone
Pour supprimer une zone d'un shard, la méthode sh.removeShardTag() est utilisée. L'exemple suivant supprime la zone A d'une partition.
sh.removeShardTag("shard0002", "A")Conseils pour les zones MongoDB
Gardez des documents simples
MongoDB est une base de données sans schéma. Cela signifie qu'il n'y a pas de schéma prédéfini par défaut. Nous pouvons ajouter un schéma prédéfini dans les versions plus récentes, mais ce n'est pas obligatoire. Ne sous-estimez pas les difficultés qui surviennent lorsque vous travaillez avec des documents et des tableaux, car il peut devenir très difficile d'analyser vos données dans le processus côté application/ETL. De plus, les tableaux peuvent nuire aux performances de réplication :pour chaque modification du tableau, toutes les valeurs du tableau sont répliquées.
Le meilleur matériel n'est pas toujours la meilleure option
L'utilisation d'un bon matériel contribue certainement à une bonne performance. Mais que peut-il se passer dans un environnement lorsqu'une instance d'une grosse machine meurt ? La réponse est "basculement".
Avoir plusieurs petites machines (au lieu d'une ou deux) dans un environnement distribué peut garantir que les pannes n'affecteront que quelques parties de la partition avec peu ou pas de perception par l'application. Mais en même temps, plus de machines impliquent une forte probabilité d'avoir une panne. Tenez compte de ce compromis lors de la conception de votre environnement. Les bons choix affectent les performances.
Ensemble de travail
Quelle est la taille de l'ensemble de travail ? Généralement, une application n'utilise pas toutes les données. Certaines données sont souvent mises à jour, tandis que d'autres ne le sont pas. Votre jeu de données de travail tient-il dans la RAM ? Les performances optimales se produisent lorsque tout le jeu de données de travail se trouve dans la RAM.



