Lorsque vous installez ClusterControl, il a une configuration par défaut qui ne correspond peut-être pas à vos besoins, vous devrez donc probablement personnaliser cette installation. Pour cela, vous pouvez modifier les fichiers de configuration, mais vous pouvez également vérifier ou modifier les paramètres d'exécution de ClusterControl. Dans ce blog, nous vous montrerons où vous pouvez voir cette configuration et quelles sont les options disponibles à utiliser ici.
Où pouvez-vous voir la configuration d'exécution de ClusterControl ?
Il existe deux manières différentes de vérifier cela. Tout d'abord, vous pouvez accéder à ClusterControl -> Paramètres globaux -> Configurations d'exécution, puis choisissez votre cluster.
Une autre façon est ClusterControl -> Sélectionnez Cluster -> Paramètres -> Configurations d'exécution .
Dans les deux cas, vous irez au même endroit, la Configuration du Runtime rubrique.
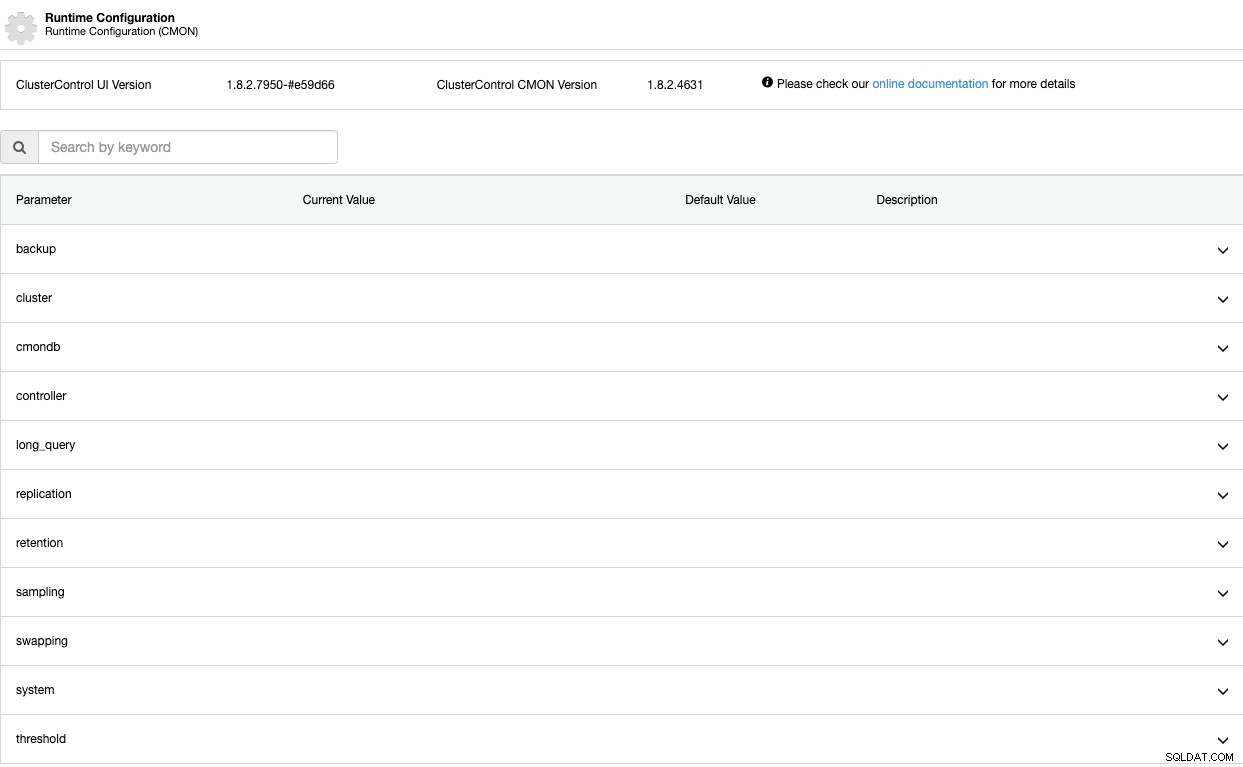
Paramètres de configuration d'exécution
Maintenant, voyons ces paramètres un par un. Gardez à l'esprit que ces paramètres dépendent de la technologie de base de données que vous utilisez, vous ne les verrez donc probablement pas tous en même temps dans le même cluster.
Sauvegarde
| Nom | Valeur par défaut | Description |
|---|---|---|
| disable_backup_email | faux | Ce paramètre contrôle si les e-mails sont envoyés ou non si une sauvegarde est terminée ou a échoué. |
| utilisateur_sauvegarde | utilisateur de sauvegarde | Le nom d'utilisateur du compte de base de données utilisé pour gérer les sauvegardes. |
| backup_create_hash | vrai | Configure ClusterControl s'il doit calculer md5hash sur les fichiers de sauvegarde créés et les vérifier. |
| pitr_retention_hours | 0 | Heures de rétention (pour effacer les anciens journaux d'archive WAL) pour PITR. |
| netcat_port | 9999,9990-9998 | Liste des ports et plages de ports Netcat utilisés pour diffuser les sauvegardes. Les valeurs par défaut sont '9999,9990-9998' et le port 9999 sera préféré s'il est disponible. |
| rép de sauvegarde | /home/user/backups | Le répertoire de sauvegarde par défaut, à pré-remplir en Frontend. |
| backup_subdir | SAUVEGARDE-%I | Définissez le nom du sous-répertoire de sauvegarde. Cette chaîne peut contenir des séparateurs de champ standard "%X", le "%06I" par exemple sera remplacé par l'ID numérique de la sauvegarde au format 6 champs qui utilise '0' comme caractères de remplissage de tête. Voici la liste des champs actuellement pris en charge par le backend :- B La date et l'heure auxquelles la création de la sauvegarde a commencé. - H Le nom de l'hôte de sauvegarde, l'hôte qui a créé la sauvegarde. - i L'identifiant numérique du cluster. - I L'identifiant numérique de la sauvegarde. - J L'ID numérique du travail qui a créé la sauvegarde. - M La méthode de sauvegarde (par exemple "mysqldump"). - O Le nom de l'utilisateur qui a lancé la tâche de sauvegarde. - S Le nom de l'hôte de stockage, l'hôte qui stocke les fichiers de sauvegarde. - % Le signe pourcentage lui-même. Utilisez deux signes de pourcentage, "%%" de la même manière que la fonction standard printf() l'interprète comme un signe de un pour cent. |
| backup_retention | 31 | Le réglage du nombre de jours de conservation des sauvegardes. Les sauvegardes correspondant à la période de rétention sont supprimées. |
| backup_cloud_retention | 180 | Le réglage du nombre de jours pendant lesquels conserver les sauvegardes téléchargées sur un cloud. Les sauvegardes correspondant à la période de rétention sont supprimées. |
| backup_n_safety_copies | 1 | Le paramètre du nombre de sauvegardes complètes terminées qui seront conservées quel que soit leur statut de conservation. |
Cluster
| Nom | Valeur par défaut | Description |
|---|---|---|
| cluster_name | Le nom du cluster pour une identification facile. | |
| enable_node_autorecovery | vrai | Paramètre de récupération automatique des nœuds. |
| enable_cluster_autorecovery | vrai | Si true, ClusterControl effectuera une récupération automatique du cluster, si false aucune récupération de cluster ne sera effectuée automatiquement. |
| répertoire de configuration | /etc/ | Le répertoire de configuration du serveur de base de données. |
| créé_par_travail | L'ID du travail a créé ce cluster. | |
| ssh_keypath | /home/user/.ssh/id_rsa | Le fichier de clé SSH utilisé pour la connexion aux nœuds. |
| server_selection_try_once | vrai | Option URI de connexion MongoDB. Définit si la sélection de serveur doit être répétée en cas d'échec jusqu'à l'expiration d'un délai de sélection de serveur, ou simplement revenir avec un échec immédiatement. |
| server_selection_timeout_ms | 30000 | Option URI de connexion MongoDB. Définit la valeur du délai d'attente jusqu'à ce que mongodriver tente de réussir une opération de sélection de serveur. |
| propriétaire | L'ID utilisateur ClusterControl du propriétaire de l'objet cluster. | |
| group_owner | L'ID de groupe ClusterControl du groupe qui possède l'objet cluster. | |
| cdt_path | L'emplacement de l'objet cluster dans l'arborescence du répertoire ClusterControl. | |
| balises | / | Un ensemble de chaînes que l'utilisateur peut spécifier. |
| acl | La liste de contrôle d'accès sous forme de chaîne contrôlant l'accès à l'objet cluster. | |
| mongodb_user | admindb | Le nom d'utilisateur MongoDB. |
| mongodb_basedir | /usr/ | Le basedir pour l'installation de MongoDB. |
| mysql_basedir | /usr/ | Le basedir pour l'installation de MySQL. |
| scriptdir | /usr/bin/ | Le répertoire des scripts d'installation de MySQL. |
| staging_dir | /home/user/s9s_tmp | Un chemin intermédiaire pour les fichiers temporaires. |
| bindir | /usr/bin | Le répertoire /bin de l'installation de MySQL. |
| monitored_mysql_port | 3306 | Le numéro de port du serveur MySQL surveillé. |
| ndb_connectstring | 127.0.0.1:1186 | Le paramètre de chaîne de connexion NDB pour le cluster MySQL. |
| ndbd_datadir | Le répertoire de données des nœuds NDBD. | |
| mgmd_datadir | Le répertoire de données des nœuds NDB MGMD. | |
| os_user | Le nom d'utilisateur SSH utilisé pour accéder aux nœuds. | |
| repl_user | cmon_replication | Le nom d'utilisateur de réplication. |
| fournisseur | Le nom du fournisseur de la base de données utilisé pour les déploiements. | |
| galera_version | Le numéro de version de Galera utilisé. | |
| version_serveur | La version du serveur de base de données utilisée pour les déploiements. | |
| postgresql_user | admindb | Le nom d'utilisateur PostgreSQL. |
| galera_port | 4567 | Le port galera à utiliser lors de l'ajout de nœuds/garbd et de la construction de wsrep_cluster_address. Ne pas modifier au moment de l'exécution. |
| auto_manage_readonly | vrai | Autoriser ClusterControl à gérer l'indicateur de lecture seule des serveurs MySQL gérés. |
| node_recovery_lock_file | Spécifiez un fichier de verrouillage et s'il est présent sur un nœud, le nœud ne récupérera pas. Il est de la responsabilité de l'administrateur de créer/supprimer le fichier. |
Cmondb
| Nom | Valeur par défaut | Description |
|---|---|---|
| cmon_db | cmon | Le nom de la base de données ClusterControl locale. |
| cmondb_hostname | 127.0.0.1 | Le nom d'hôte du serveur MySQL de la base de données ClusterControl locale. |
| mysql_port | 3306 | Le port du serveur MySQL de la base de données ClusterControl locale. |
| cmon_user | cmon | Le nom du compte pour accéder à la base de données locale ClusterControl. |
Contrôleur
| Nom | Valeur par défaut | Description |
|---|---|---|
| controller_id | 5a3a993d-xxxx | Une chaîne d'identifiant arbitraire de cette instance de contrôleur. |
| cmon_hostname | 192.168.xx.xx | Le nom d'hôte du contrôleur. |
| error_report_dir | /home/user/s9s_tmp | Emplacement de stockage des rapports d'erreurs. |
Long_query
| Nom | Valeur par défaut | Description |
|---|---|---|
| long_query_time | 0.5 | Valeur seuil pour la vérification lente des requêtes. |
| query_monitor_alert_long_running_query | vrai | Déclenche une alarme si une requête est exécutée plus longtemps que query_monitor_long_running_query_ms. |
| query_monitor_kill_long_running_query | faux | Tuer la requête si la requête s'est exécutée plus longtemps que query_monitor_long_running_query_ms. |
| query_monitor_long_running_query_time_ms | 30000 | Déclenche une alarme si une requête est exécutée plus longtemps que query_monitor_long_running_query_ms. La valeur minimale est 1000. |
| query_monitor_long_running_query_matching_info | Mettre en correspondance uniquement les requêtes avec un 'Info' correspondant uniquement à cette expression régulière POSIX. Aucune valeur par défaut, correspond à n'importe quelle information. | |
| query_monitor_long_running_query_matching_info_negate | faux | Annuler le résultat de query_monitor_long_running_query_matching_info. |
| query_monitor_long_running_query_matching_host | Mettre en correspondance uniquement les requêtes avec un 'Hôte' correspondant uniquement à cette expression régulière POSIX. Aucune valeur par défaut, correspond à n'importe quel hôte. | |
| query_monitor_long_running_query_matching_db | Mettre en correspondance uniquement les requêtes avec un 'Db' correspondant uniquement à cette expression régulière POSIX. Aucune valeur par défaut, correspond à n'importe quelle Db. | |
| query_monitor_long_running_query_matching_user | Mettre en correspondance uniquement les requêtes avec un 'utilisateur' correspondant uniquement à cette expression régulière POSIX. Aucune valeur par défaut, correspond à n'importe quel utilisateur. | |
| query_monitor_long_running_query_matching_user_negate | faux | Annuler le résultat de query_monitor_long_running_query_matching_user. |
| query_monitor_long_running_query_matching_command | Requête | Ne fait correspondre que les requêtes avec une 'Commande' correspondant uniquement à cette expression régulière POSIX. Par défaut, 'Requête'. |
Réplication
| Nom | Valeur par défaut | Description |
|---|---|---|
| max_replication_lag | 10 | Délai de réplication maximal autorisé en secondes avant l'envoi d'une alarme. |
| replication_stop_on_error | vrai | Contrôle si les procédures de basculement/basculement doivent échouer en cas d'erreurs susceptibles d'entraîner une perte de données. |
| replication_auto_rebuild_slave | faux | Si le SQL THREAD est arrêté et que le code d'erreur est différent de zéro, l'esclave sera automatiquement reconstruit. |
| replication_failover_blacklist | Liste séparée par des virgules de nom d'hôte :paires de ports. Les serveurs sur liste noire ne seront pas considérés comme candidats lors du basculement. replication_failover_blacklist est ignoré si replication_failover_whitelist est défini. | |
| replication_failover_whitelist | Liste séparée par des virgules de nom d'hôte :paires de ports. Seuls les serveurs en liste blanche seront considérés comme candidats lors du basculement. Si aucun serveur de la liste blanche n'est disponible (actif/connecté), le basculement échouera. replication_failover_blacklist est ignoré si replication_failover_whitelist est défini. | |
| replication_onfail_failover_script | Ce script est exécuté dès qu'il a été découvert qu'un basculement est nécessaire. Si le script renvoie une valeur différente de zéro ou n'existe pas, le basculement sera abandonné. Quatre arguments sont fournis au script et définis s'ils sont connus, sinon vide :arg1='tous les serveurs' arg2='maître défaillant' arg3='candidat sélectionné', arg4='esclaves de l'ancien maître (les candidats)' et passé comme ceci :'scriptname arg1 arg2 arg3 arg4' Le script doit être accessible sur le contrôleur et exécutable. | |
| replication_pre_failover_script | Ce script est exécuté avant le basculement, mais après qu'un candidat a été élu et qu'il est possible de continuer le processus de basculement. Si le script renvoie une valeur différente de zéro ou n'existe pas, le basculement sera abandonné. Quatre arguments sont fournis au script et définis s'ils sont connus, sinon vide :arg1='tous les serveurs' arg2='maître défaillant' arg3='candidat sélectionné', arg4='esclaves de l'ancien maître (les candidats)' et passé comme ceci :'scriptname arg1 arg2 arg3 arg4' Le script doit être accessible sur le contrôleur et exécutable. | |
| replication_post_failover_script | Ce script est exécuté après le basculement (un nouveau maître est élu et opérationnel). Si le script renvoie une valeur différente de zéro ou n'existe pas, le basculement sera abandonné. Quatre arguments sont fournis au script et définis s'ils sont connus, sinon vides :arg1='tous les serveurs' arg2='maître défaillant' arg3='candidat sélectionné', arg4='esclaves de l'ancien maître (les candidats)' et passé comme ceci :'scriptname arg1 arg2 arg3 arg4' Le script doit être accessible sur le contrôleur et exécutable. | |
| replication_post_unsuccessful_failover_script | Ce script est exécuté si la tentative de basculement échoue. Si le script renvoie une valeur différente de zéro ou n'existe pas, le basculement sera abandonné. Quatre arguments sont fournis au script et définis s'ils sont connus, sinon vides :arg1='tous les serveurs' arg2='maître défaillant' arg3='candidat sélectionné', arg4='esclaves de l'ancien maître (les candidats)' et passé comme ceci :'scriptname arg1 arg2 arg3 arg4' Le script doit être accessible sur le contrôleur et exécutable. |
Rétention
| Nom | Valeur par défaut | Description |
|---|---|---|
| ops_report_retention | 31 | Le réglage du nombre de jours de conservation des rapports opérationnels. Les rapports correspondant à la période de conservation sont supprimés. |
Échantillonnage
| Nom | Valeur par défaut | Description |
|---|---|---|
| enable_icmp_ping | vrai | Désactive si ClusterControl doit mesurer les temps de ping ICMP vers l'hôte. |
| host_stats_collection_interval | 30 | Paramètres pour l'intervalle de collecte de l'hôte (CPU, mémoire, etc.). |
| host_stats_window_size | 180 | Définition de la taille de la fenêtre (en secondes) pour examiner les statistiques afin de déclencher/effacer les alarmes de statistiques de l'hôte. |
| db_stats_collection_interval | 30 | Paramètres pour l'intervalle de collecte des statistiques de la base de données. |
| db_proc_stats_collection_interval | 5 | Paramètre pour l'intervalle de collecte des statistiques de processus de base de données. La valeur minimale autorisée est de 1 seconde. Nécessite un redémarrage du service cmon. |
| lb_stats_collection_interval | 15 | Paramètre pour l'intervalle de collecte des statistiques de l'équilibreur de charge. |
| db_schema_stats_collection_interval | 108000 | Paramètre pour l'intervalle de surveillance des statistiques de schéma. |
| db_deadlock_check_interval | 0 | À quelle fréquence vérifier les interblocages. Spécifié en secondes. La détection des interblocages affectera l'utilisation du processeur sur les nœuds de la base de données. |
| log_collection_interval | 600 | Contrôle l'intervalle entre les collectes de fichiers journaux. |
| db_hourly_stats_collection_interval | 5 | Contrôle le nombre de secondes entre chaque échantillon individuel dans les statistiques de la plage horaire. |
| points_de_montage_surveillés | La liste des points de montage à surveiller. | |
| monitor_cpu_temperature | faux | Surveiller la température du processeur. |
| log_queries_not_using_indexes | faux | Configurer le moniteur de requêtes pour détecter les requêtes n'utilisant pas d'index. |
| query_sample_interval | 1 | Contrôle l'intervalle de surveillance des requêtes en secondes, -1 signifie aucune surveillance des requêtes. |
| query_monitor_auto_purge_ps | faux | Si activé, la table P_S events_statements_summary_by_digest sera purgée automatiquement (TRUNCATE TABLE) toutes les heures. |
| schema_change_detection_address | Des vérifications seront exécutées (en utilisant SHOW TABLES/SHOW CREATE TABLE) pour déterminer si le schéma a changé. Les vérifications sont exécutées sur l'adresse spécifiée et sont au format HOSTNAME:PORT. Les bases de données schema_change_detection_databases doivent également être définies. Un diff d'une table modifiée est créé. | |
| schema_change_detection_databases | Liste séparée par des virgules des bases de données à surveiller pour les changements de schéma. Si vide, aucune vérification n'est effectuée. | |
| schema_change_detection_pause_time_ms | 0 | Temps de pause en ms entre chaque SHOW CREATE TABLE. Le temps de pause affectera la durée du processus de détection. |
| enable_is_queries | vrai | Spécifie si les requêtes au information_schema seront exécutées ou non. Les requêtes vers information_schema peuvent ne pas convenir lorsque vous avez de nombreux objets de schéma (des centaines de bases de données, des centaines de tables dans chaque base de données, des déclencheurs, des utilisateurs, des événements, des sprocs). Si elle est désactivée, la requête qui serait exécutée sera enregistrée afin qu'il puisse être déterminé si la requête est adaptée à votre environnement. |
Echange
| Nom | Valeur par défaut | Description |
|---|---|---|
| swap_warning | 20 | Seuil d'alarme d'avertissement pour l'utilisation du swap. |
| swap_critical | 90 | Seuil d'alarme critique pour l'utilisation du swap. |
| swap_inout_period | 0 | L'intervalle pour les alarmes d'échange d'E/S (<=0 désactive). |
| swap_inout_warning | 10240 | Le nombre de pages permutées I/O dans l'intervalle spécifié (swap_inout_period, par défaut 10 minutes) pour avertissement. |
| swap_inout_critical | 102400 | Le nombre de pages permutées I/O dans l'intervalle spécifié (swap_inout_period, par défaut 10 minutes) pour critique. |
Système
| Nom | Valeur par défaut | Description |
|---|---|---|
| cmon_config_path | /etc/cmon.d/cmon_x.cnf | Le chemin du fichier de configuration. Cette valeur de configuration est en lecture seule. |
| os | debian/redhat | Le type de système d'exploitation. Les valeurs possibles sont 'debian' ou 'redhat'. |
| libssh_timeout | 30 | La valeur du délai d'expiration du réseau pour les connexions SSH. |
| sudo | sudo -n 2>/dev/null | La commande utilisée pour obtenir les privilèges de superutilisateur. |
| ssh_port | 22 | Le port pour les connexions SSH aux nœuds. |
| local_repo_name | Les noms de référentiel local utilisés pour le déploiement du cluster. | |
| frontend_url | L'URL envoyée dans les e-mails pour diriger le destinataire vers l'interface Web de ClusterControl. | |
| purger | 7 | Combien de temps ClusterControl conservera les données. Mesurés en jours, les travaux, les messages de travail, les alarmes, les journaux collectés, les rapports opérationnels, les informations de croissance de la base de données plus anciennes seront supprimées. |
| os_user_home | /home/utilisateur | Le répertoire HOME de l'utilisateur utilisé sur les nœuds. |
| cmon_mail_sender | L'expéditeur de l'e-mail utilisé pour les e-mails envoyés. | |
| plugin_dir | Le chemin du répertoire des plugins. | |
| use_internal_repos | faux | Paramètre qui a désactivé la configuration du référentiel tiers. |
| cmon_use_mail | faux | Configuration pour utiliser la commande 'mail' pour l'envoi d'e-mails. |
| enable_html_emails | vrai | Permet l'envoi d'e-mails HTML. |
| send_clear_alarm | vrai | Active l'envoi d'e-mails en cas d'effacement des alarmes de cluster. |
| répertoire_package_logiciel | Il s'agit de l'emplacement de stockage des packages logiciels, c'est-à-dire que tous les fichiers nécessaires pour installer avec succès un nœud, s'il n'y a pas de référentiel yum/apt disponible, doivent être placés ici. S'applique principalement à MySQL Cluster ou aux anciennes installations de Codership/Galera. |
Seuil
| Nom | Valeur par défaut | Description |
|---|---|---|
| ram_warning | 80 | Seuil d'alarme d'avertissement pour l'utilisation de la RAM. |
| ram_critical | 90 | Seuil d'alarme critique pour l'utilisation de la RAM. |
| diskspace_warning | 80 | Seuil d'alarme d'avertissement pour l'utilisation du disque. |
| diskspace_critical | 90 | Seuil d'alarme critique pour l'utilisation du disque. |
| avertissement_cpu | 80 | Seuil d'alarme d'avertissement pour l'utilisation du CPU. |
| cpu_critical | 90 | Seuil d'alarme critique pour l'utilisation du CPU. |
| cpu_steal_warning | 10 | Seuil d'alarme d'avertissement pour vol de CPU. |
| cpu_steal_critical | 20 | Seuil d'alarme critique pour le vol de CPU. |
| cpu_iowait_warning | 50 | Seuil d'alarme d'avertissement pour CPU IO Wait. |
| cpu_iowait_critical | 60 | Seuil d'alarme critique pour CPU IO Wait. |
| slow_ssh_warning | 6 | Une alarme d'avertissement sera déclenchée s'il faut plus de temps que le temps spécifié pour établir une connexion SSH (secs). |
| slow_ssh_critical | 12 | Une alarme critique sera déclenchée s'il faut plus de temps que le temps spécifié pour établir une connexion SSH (secs). |
Conclusion
Comme vous pouvez le constater, de nombreux paramètres doivent être modifiés si vous devez adapter ClusterControl à votre charge de travail ou à votre activité. Passer en revue toutes les valeurs et les modifier en conséquence peut prendre du temps, mais en fin de compte, cela vous fera gagner du temps car vous pourrez tirer le meilleur parti de toutes les fonctionnalités de ClusterControl.



