Le basculement automatique pour la réplication MySQL fait l'objet de débats depuis de nombreuses années.
Est-ce une bonne ou une mauvaise chose ?
Pour ceux qui ont une longue mémoire dans le monde MySQL, ils se souviendront peut-être de la panne de GitHub en 2012, principalement causée par des logiciels prenant de mauvaises décisions.
GitHub venait alors de migrer vers une combinaison de MySQL Replication, Corosync, Pacemaker et Percona Replication Manager. PRM a décidé d'effectuer un basculement après l'échec des vérifications de l'état du maître, qui a été surchargé lors d'une migration de schéma. Un nouveau maître a été sélectionné, mais ses performances ont été médiocres en raison de caches à froid. La charge élevée de requêtes du site occupé a de nouveau provoqué l'échec des pulsations du PRM sur le maître froid, et le PRM a alors déclenché un autre basculement vers le maître d'origine. Et les problèmes ont continué, comme résumé ci-dessous.
 Source :Henrik Ingo &Massimo Brignoli à Percona Live 2013
Source :Henrik Ingo &Massimo Brignoli à Percona Live 2013 Quelques années plus tard, GitHub est de retour avec un cadre assez sophistiqué pour gérer la réplication MySQL et le basculement automatisé ! Comme le dit Shlomi Noach :
« À cet effet, nous utilisons des basculements maîtres automatisés. Le temps qu'il faudrait à un humain pour réveiller et réparer un maître défaillant est au-delà de nos attentes de disponibilité, et l'exploitation d'un tel basculement n'est parfois pas triviale. Nous nous attendons à ce que les pannes de maître soient automatiquement détectées et récupérées dans les 30 secondes ou moins, et nous nous attendons à ce que le basculement entraîne une perte minimale d'hôtes disponibles."
La plupart des entreprises ne sont pas GitHub, mais on pourrait dire qu'aucune entreprise n'aime les pannes. Les pannes perturbent toute entreprise et coûtent également de l'argent. Je suppose que la plupart des entreprises auraient probablement souhaité avoir une sorte de basculement automatisé, et les raisons de ne pas l'implémenter sont probablement la complexité des solutions existantes, le manque de compétence dans la mise en œuvre de telles solutions ou le manque de confiance dans les logiciels à prendre une décision si importante.
Il existe un certain nombre de solutions de basculement automatisées, y compris (et sans s'y limiter) MHA, MMM, MRM, mysqlfailover, Orchestrator et ClusterControl. Certains d'entre eux sont sur le marché depuis plusieurs années, d'autres sont plus récents. C'est bon signe, plusieurs solutions signifient que le marché est là et que les gens essaient de résoudre le problème.
Lorsque nous avons conçu le basculement automatique dans ClusterControl, nous avons utilisé quelques principes directeurs :
-
Assurez-vous que le maître est vraiment mort avant de basculer
Dans le cas d'une partition réseau, où le logiciel de basculement perd le contact avec le maître, il ne le verra plus. Mais le maître peut fonctionner correctement et peut être vu par le reste de la topologie de réplication.
ClusterControl rassemble des informations à partir de tous les nœuds de base de données ainsi que de tous les proxys de base de données/équilibreurs de charge utilisés, puis construit une représentation de la topologie. Il ne tentera pas de basculement si les esclaves peuvent voir le maître, ni si ClusterControl n'est pas sûr à 100 % de l'état du maître.
ClusterControl permet également de visualiser facilement la topologie de l'installation, ainsi que l'état des différents nœuds (c'est la compréhension de ClusterControl de l'état du système, basée sur les informations qu'il recueille).
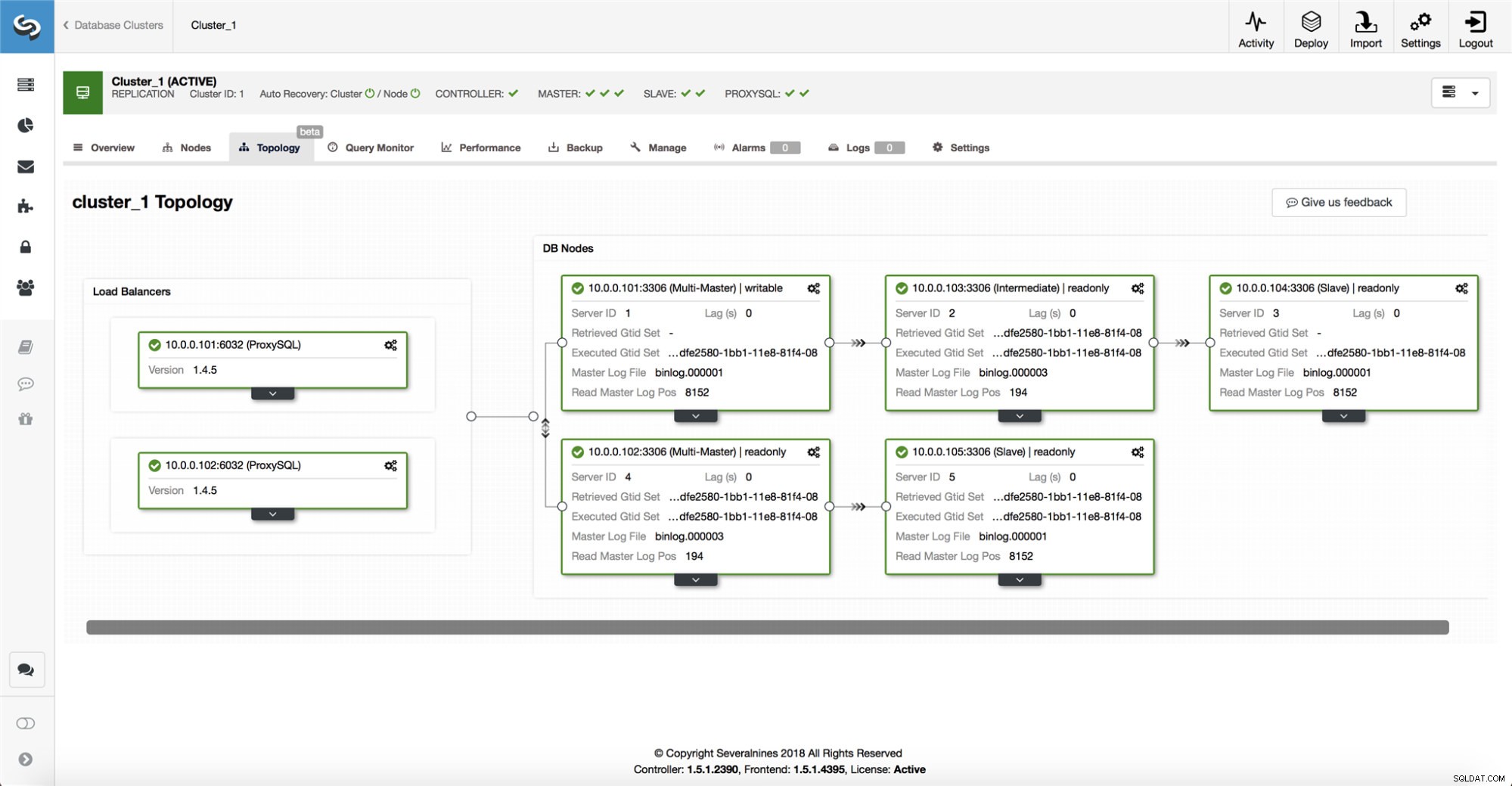
-
Basculement une seule fois
Beaucoup a été écrit sur le battement. Cela peut devenir très compliqué si l'outil de disponibilité décide d'effectuer plusieurs basculements. C'est une situation dangereuse. Chaque maître élu, quelle que soit la durée pendant laquelle il a occupé le rôle de maître, peut avoir ses propres ensembles de modifications qui n'ont jamais été répliquées sur aucun serveur. Vous pouvez donc vous retrouver avec des incohérences entre tous les maîtres élus.
-
Ne pas basculer vers un esclave incohérent
Lors de la sélection d'un esclave à promouvoir en tant que maître, nous nous assurons que l'esclave n'a pas d'incohérences, par ex. transactions errantes, car cela peut très bien interrompre la réplication.
-
N'écrire qu'au maître
La réplication va du maître vers le ou les esclaves. Écrire directement sur un esclave créerait un ensemble de données divergent, ce qui peut être une source potentielle de problème. Nous définissons les esclaves sur read_only et super_read_only dans les versions plus récentes de MySQL ou MariaDB. Nous conseillons également l'utilisation d'un équilibreur de charge, par exemple, ProxySQL ou MaxScale, pour protéger la couche application de la topologie de base de données sous-jacente et de toute modification de celle-ci. L'équilibreur de charge applique également les écritures sur le maître actuel.
-
Ne récupère pas automatiquement le maître défaillant
Si le maître est défaillant et qu'un nouveau maître a été élu, ClusterControl n'essaiera pas de récupérer le maître défaillant. Pourquoi? Ce serveur peut contenir des données qui n'ont pas encore été répliquées, et l'administrateur devra effectuer une enquête sur l'échec. Ok, vous pouvez toujours configurer ClusterControl pour effacer les données sur le maître défaillant et le faire rejoindre en tant qu'esclave au nouveau maître - si vous êtes d'accord pour perdre des données. Mais par défaut, ClusterControl laissera le maître défaillant, jusqu'à ce que quelqu'un le regarde et décide de le réintroduire dans la topologie.
Alors, devriez-vous automatiser le basculement ? Cela dépend de la façon dont vous avez configuré la réplication. Les configurations de réplication circulaire avec plusieurs maîtres accessibles en écriture ou des topologies complexes ne sont probablement pas de bons candidats pour le basculement automatique. Nous nous en tiendrons aux principes ci-dessus lors de la conception d'une solution de réplication.
Sur PostgreSQL
En ce qui concerne la réplication en continu PostgreSQL, ClusterControl utilise des principes similaires pour automatiser le basculement. Pour PostgreSQL, ClusterControl prend en charge les modèles de réplication asynchrone et synchrone entre le maître et les esclaves. Dans les deux cas et en cas de panne, l'esclave avec les données les plus à jour est élu comme nouveau maître. Les maîtres défaillants ne sont pas automatiquement récupérés/corrigés pour rejoindre la configuration de réplication.
Quelques mesures de protection sont prises pour s'assurer que le maître défaillant est en panne et le reste, par ex. il est supprimé de l'équilibrage de charge défini dans le proxy et il est tué si, par ex. l'utilisateur le redémarrerait manuellement. Il est un peu plus difficile de détecter les divisions de réseau entre ClusterControl et le maître, car les esclaves ne fournissent aucune information sur l'état du maître à partir duquel ils répliquent. Un proxy devant la configuration de la base de données est donc important car il peut fournir un autre chemin vers le maître.
Sur MongoDB
La réplication MongoDB au sein d'un jeu de répliques via l'oplog est très similaire à la réplication binlog, alors comment se fait-il que MongoDB récupère automatiquement un maître défaillant ? Le problème est toujours là, et MongoDB le résout en annulant toutes les modifications qui n'ont pas été répliquées sur les esclaves au moment de l'échec. Ces données sont supprimées et placées dans un dossier "rollback", il appartient donc à l'administrateur de les restaurer.
Pour en savoir plus, consultez ClusterControl; et n'hésitez pas à commenter ou à poser des questions ci-dessous.



