L'amélioration des performances du système, en particulier pour les structures informatiques, nécessite un processus permettant d'obtenir une bonne vue d'ensemble des performances. Ce processus est généralement appelé surveillance. La surveillance est un élément essentiel de la gestion de la base de données et les informations détaillées sur les performances de votre MongoDB ne vous aideront pas seulement à évaluer son état fonctionnel ; mais aussi donner un indice sur les anomalies, ce qui est utile lors de la maintenance. Il est essentiel d'identifier les comportements inhabituels et de les corriger avant qu'ils ne dégénèrent en défaillances plus graves.
Certains des types de pannes qui pourraient survenir sont...
- Retard ou ralentissement
- Inadéquation des ressources
- Hic du système
La surveillance est souvent centrée sur l'analyse des métriques. Certaines des mesures clés que vous voudrez surveiller incluent...
- Performance de la base de données
- Utilisation des ressources (utilisation du processeur, mémoire disponible et utilisation du réseau)
- Des revers émergents
- Saturation et limitation des ressources
- Opérations de débit
Dans ce blog, nous allons discuter en détail de ces mesures et examiner les outils disponibles de MongoDB (tels que les utilitaires et les commandes). Nous examinerons également d'autres outils logiciels tels que Pandora, FMS Open Source et Robo 3T. Par souci de simplicité, nous allons utiliser le logiciel Robo 3T dans cet article pour démontrer les métriques.
Performance de la base de données
La première chose à vérifier sur une base de données est sa performance générale, par exemple, si le serveur est actif ou non. Si vous exécutez cette commande db.serverStatus() sur une base de données dans Robo 3T, ces informations vous seront présentées indiquant l'état de votre serveur.
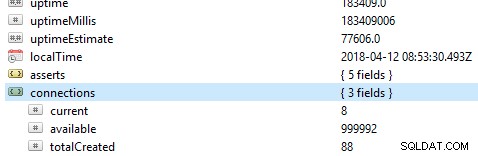

Ensembles de répliques
L'ensemble de répliques est un groupe de processus mongod qui conservent le même ensemble de données. Si vous utilisez des jeux de répliques, en particulier en mode production, les journaux d'opérations fourniront une base pour le processus de réplication. Toutes les opérations d'écriture sont suivies à l'aide de nœuds, c'est-à-dire un nœud principal et un nœud secondaire, qui stockent une collection de taille limitée. Sur le nœud principal, les opérations d'écriture sont appliquées et traitées. Cependant, si le nœud principal tombe en panne avant qu'ils ne soient copiés dans les journaux d'opérations, l'écriture secondaire est effectuée mais dans ce cas, les données risquent de ne pas être répliquées.
Indicateurs clés à surveiller...
Délai de réplication
Cela définit à quelle distance le nœud secondaire se trouve derrière le nœud principal. Un état optimal nécessite que l'écart soit le plus petit possible. Sur un système d'exploitation normal, ce décalage est estimé à 0. Si l'écart est trop important, l'intégrité des données sera compromise une fois le nœud secondaire promu au rang de nœud principal. Dans ce cas, vous pouvez définir un seuil, par exemple 1 minute, et s'il est dépassé, une alerte est définie. Les causes courantes d'un décalage de réplication important incluent...
- Shards pouvant avoir une capacité d'écriture insuffisante, souvent associée à une saturation des ressources.
- Le nœud secondaire fournit des données à un rythme plus lent que le nœud principal.
- Les nœuds peuvent également être empêchés d'une manière ou d'une autre de communiquer, peut-être en raison d'un réseau de mauvaise qualité.
- Les opérations sur le nœud principal peuvent également être plus lentes, bloquant ainsi la réplication. Si cela se produit, vous pouvez exécuter les commandes suivantes :
- db.getProfilingLevel() :si vous obtenez une valeur de 0, alors vos opérations de base de données sont optimales.
Si la valeur est de 1, cela correspond à des opérations lentes qui peuvent par conséquent être dues à des requêtes lentes. - db.getProfilingStatus() :dans ce cas on vérifie la valeur de slowms, par défaut c'est 100ms. Si la valeur est supérieure à cette valeur, il se peut que vous ayez de lourdes opérations d'écriture sur le primaire ou des ressources inadéquates sur le secondaire. Pour résoudre ce problème, vous pouvez redimensionner le secondaire afin qu'il dispose d'autant de ressources que le principal.
- db.getProfilingLevel() :si vous obtenez une valeur de 0, alors vos opérations de base de données sont optimales.
Curseurs
Si vous faites une requête de lecture, par exemple find, vous recevrez un curseur qui est un pointeur vers l'ensemble de données du résultat. Si vous exécutez cette commande db.serverStatus() et accédez à l'objet métrique puis au curseur, vous verrez ceci…

Dans ce cas, la propriété cursor.timeOut a été mise à jour de manière incrémentielle à 9 car 9 connexions sont mortes sans fermer le curseur. La conséquence est qu'il restera ouvert sur le serveur et donc consommera de la mémoire, à moins qu'il ne soit récolté par le paramètre MongoDB par défaut. Une alerte pour vous devrait identifier les curseurs non actifs et les récolter afin d'économiser de la mémoire. Vous pouvez également éviter les curseurs sans délai d'expiration, car ils conservent souvent des ressources, ce qui ralentit les performances du système interne. Ceci peut être réalisé en définissant la valeur de la propriété cursor.open.noTimeout sur une valeur de 0.
Journalisation
Considérant le moteur de stockage WiredTiger, avant que les données ne soient enregistrées, elles sont d'abord écrites sur les fichiers du disque. C'est ce qu'on appelle la journalisation. La journalisation assure la disponibilité et la pérennité des données sur un événement de panne à partir duquel une reprise peut être effectuée.
Aux fins de la récupération, nous utilisons souvent des points de contrôle (en particulier pour le système de stockage WiredTiger) pour récupérer du dernier point de contrôle. Cependant, si MongoDB s'arrête de manière inattendue, nous utilisons la technique de journalisation pour récupérer toutes les données qui ont été traitées ou fournies après le dernier point de contrôle.
La journalisation ne doit pas être désactivée dans le premier cas, car il ne faut que 60 secondes pour créer un nouveau point de contrôle. Par conséquent, si une défaillance se produit, MongoDB peut relire le journal pour récupérer les données perdues dans ces secondes.
La journalisation réduit généralement l'intervalle de temps entre le moment où les données sont appliquées à la mémoire et celui où elles sont durables sur le disque. L'objet storage.journal a une propriété qui décrit la fréquence de validation, c'est-à-dire commitIntervalMs qui est souvent définie sur une valeur de 100 ms pour WiredTiger. Le régler sur une valeur inférieure améliorera l'enregistrement fréquent des écritures, réduisant ainsi les cas de perte de données.
Performances de verrouillage
Cela peut être dû à plusieurs demandes de lecture et d'écriture provenant de nombreux clients. Lorsque cela se produit, il est nécessaire de maintenir la cohérence et d'éviter les conflits d'écriture. Pour ce faire, MongoDB utilise un verrouillage multi-granularité qui permet aux opérations de verrouillage de se produire à différents niveaux, tels que le niveau global, la base de données ou la collection.
Si vous avez des modèles de conception de schéma médiocres, vous serez vulnérable aux verrous maintenus pendant de longues durées. Cela se produit souvent lorsque vous effectuez deux ou plusieurs opérations d'écriture différentes sur un seul document dans la même collection, avec pour conséquence de se bloquer mutuellement. Pour le moteur de stockage WiredTiger, nous pouvons utiliser le système de tickets où les demandes de lecture ou d'écriture proviennent de quelque chose comme une file d'attente ou un fil.
Par défaut, le nombre simultané d'opérations de lecture et d'écriture est défini par les paramètres wiredTigerConcurrentWriteTransactions et wiredTigerConcurrentReadTransactions qui sont tous deux définis sur une valeur de 128.
Si vous augmentez trop cette valeur, vous finirez par être limité par les ressources du processeur. Pour augmenter le débit des opérations, il serait conseillé de mettre à l'échelle horizontalement en fournissant plus de fragments.
Plusieursnines Devenez un administrateur de base de données MongoDB – Amener MongoDB en productionDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer MongoDBDélécharger gratuitementUtilisation des ressources
Cela décrit généralement l'utilisation des ressources disponibles telles que la capacité du processeur/le taux de traitement et la RAM. Les performances, en particulier pour le processeur, peuvent changer radicalement en fonction des charges de trafic inhabituelles. Les choses à vérifier incluent...
- Nombre de connexions
- Stockage
- Cache
Nombre de connexions
Si le nombre de connexions est supérieur à ce que le système de base de données peut gérer, il y aura beaucoup de files d'attente. Par conséquent, cela submergera les performances de la base de données et ralentira votre configuration. Ce numéro peut entraîner des problèmes de pilote ou même des complications avec votre application.
Si vous surveillez un certain nombre de connexions pendant une certaine période et que vous remarquez ensuite que cette valeur a atteint un pic, il est toujours recommandé de définir une alerte si la connexion dépasse ce nombre.
Si le nombre devient trop élevé, vous pouvez augmenter votre capacité afin de répondre à cette augmentation. Pour ce faire, vous devez connaître le nombre de connexions disponibles dans une période donnée, sinon, si les connexions disponibles ne suffisent pas, alors les demandes ne seront pas traitées en temps opportun.
Par défaut, MongoDB prend en charge jusqu'à 1 million de connexions. Avec votre surveillance, assurez-vous toujours que les connexions actuelles ne s'approchent jamais trop de cette valeur. Vous pouvez vérifier la valeur dans l'objet de connexions.

Stockage
Chaque ligne et enregistrement de données dans MongoDB est appelé document. Les données du document sont au format BSON. Sur une base de données donnée, si vous exécutez la commande db.stats(), ces données vous seront présentées.
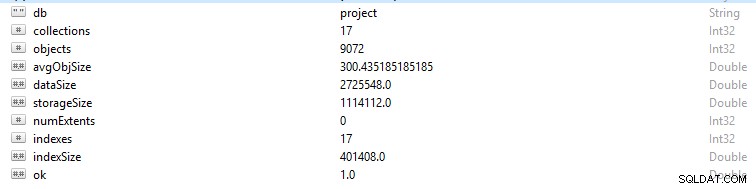
- StorageSize définit la taille de toutes les extensions de données dans la base de données.
- IndexSize indique la taille de tous les index créés dans cette base de données.
- dataSize est une mesure de l'espace total occupé par les documents dans la base de données.
Vous pouvez parfois voir un changement dans la mémoire, surtout si beaucoup de données ont été supprimées. Dans ce cas, vous devez configurer une alerte afin de vous assurer qu'elle n'est pas due à une activité malveillante.
Parfois, la taille globale du stockage peut augmenter alors que le graphique du trafic de la base de données est constant et dans ce cas, vous devez vérifier la structure de votre application ou de votre base de données pour éviter d'avoir des doublons si vous n'en avez pas besoin.
Comme la mémoire générale d'un ordinateur, MongoDB possède également des caches dans lesquels les données actives sont temporairement stockées. Cependant, une opération peut demander des données qui ne sont pas dans cette mémoire active, faisant ainsi une demande à partir du stockage sur disque principal. Cette demande ou situation est appelée erreur de page. Les demandes de défaut de page sont limitées en termes de durée d'exécution et peuvent être préjudiciables lorsqu'elles se produisent fréquemment. Pour éviter ce scénario, assurez-vous que la taille de votre RAM est toujours suffisante pour répondre aux ensembles de données avec lesquels vous travaillez. Vous devez également vous assurer qu'il n'y a pas de redondance de schéma ou d'index inutiles.
Cache
Le cache est un élément de stockage de données temporelles pour les données fréquemment consultées. Dans WiredTiger, le cache du système de fichiers et le cache du moteur de stockage sont souvent utilisés. Assurez-vous toujours que votre ensemble de travail ne dépasse pas le cache disponible, sinon les défauts de page augmenteront en nombre, ce qui entraînera des problèmes de performances.
À un moment donné, vous pouvez décider de modifier vos opérations fréquentes, mais les modifications ne sont parfois pas reflétées dans le cache. Ces données non modifiées sont appelées « données modifiées ». Il existe car il n'a pas encore été vidé sur le disque. Des goulots d'étranglement se produiront si la quantité de « données modifiées » atteint une valeur moyenne définie par une écriture lente sur le disque. L'ajout de fragments supplémentaires contribuera à réduire ce nombre.
Utilisation du processeur
Une indexation incorrecte, une structure de schéma médiocre et des requêtes conçues de manière peu conviviale nécessiteront plus d'attention du processeur, ce qui augmentera évidemment son utilisation.
Opérations de débit
Dans une large mesure, obtenir suffisamment d'informations sur ces opérations peut permettre d'éviter des revers conséquents tels que des erreurs, la saturation des ressources et des complications fonctionnelles.
Vous devez toujours prendre note du nombre d'opérations de lecture et d'écriture dans la base de données, c'est-à-dire une vue de haut niveau des activités du cluster. Connaître le nombre d'opérations générées pour les requêtes vous permettra de calculer la charge que la base de données est censée gérer. La charge peut ensuite être gérée soit en augmentant la taille de votre base de données, soit en augmentant la taille ; selon le type de ressources dont vous disposez. Cela vous permet d'évaluer facilement le rapport de quotient dans lequel les demandes s'accumulent par rapport à la vitesse à laquelle elles sont traitées. De plus, vous pouvez optimiser vos requêtes de manière appropriée afin d'améliorer les performances.
Afin de vérifier le nombre d'opérations de lecture et d'écriture, exécutez cette commande db.serverStatus(), puis accédez à l'objet locks.global, la valeur de la propriété r représente le nombre de demandes de lecture et w le nombre d'écritures.
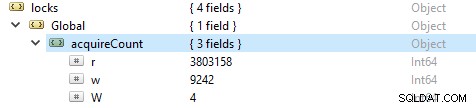
Le plus souvent, les opérations de lecture sont plus importantes que les opérations d'écriture. Les mesures des clients actifs sont signalées sous globalLock.
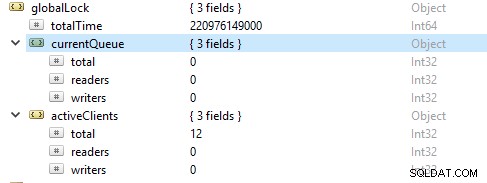
Saturation et limitation des ressources
Parfois, la base de données peut ne pas suivre le rythme d'écriture et de lecture, comme le montre le nombre croissant de requêtes en file d'attente. Dans ce cas, vous devez faire évoluer votre base de données en fournissant plus de fragments pour permettre à MongoDB de répondre aux demandes assez rapidement.
Émergences contrevenantes
Les fichiers journaux MongoDB donnent toujours un aperçu général des exceptions d'assertion renvoyées. Ce résultat vous donnera un indice sur les causes possibles d'erreurs. Si vous exécutez la commande db.serverStatus(), certaines des alertes d'erreur que vous remarquerez incluent :

- Assertions régulières :elles résultent d'un échec d'opération. Par exemple, dans un schéma, si une valeur de chaîne est fournie à un champ entier, ce qui entraîne un échec de lecture du document BSON.
- Alertes d'avertissement :il s'agit souvent d'alertes sur un problème, mais qui n'ont pas beaucoup d'impact sur son fonctionnement. Par exemple, lorsque vous mettez à niveau votre MongoDB, vous pouvez être alerté à l'aide de fonctions obsolètes.
- Alertes de message :elles résultent d'exceptions de serveur interne telles qu'un réseau lent ou si le serveur n'est pas actif.
- Assertions utilisateur :comme les assertions normales, ces erreurs surviennent lors de l'exécution d'une commande, mais elles sont souvent renvoyées au client. Par exemple, s'il y a des clés en double, un espace disque insuffisant ou aucun accès pour écrire dans la base de données. Vous choisirez de vérifier votre application pour corriger ces erreurs.



