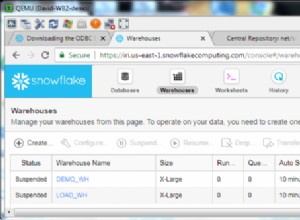
300k lignes n'est pas une table énorme. Nous voyons fréquemment des tables de 300 millions de lignes.
Le plus gros problème avec votre requête est que vous utilisez une sous-requête corrélée, elle doit donc ré-exécuter la sous-requête pour chaque ligne dans la requête externe.
Il arrive souvent que vous n'ayez pas besoin de faire tout votre travail dans une instruction SQL. Il y a des avantages à le diviser en plusieurs instructions SQL plus simples :
- Plus facile à coder.
- Plus facile à optimiser.
- Plus facile à déboguer.
- Plus facile à lire.
- Plus facile à gérer si/quand vous devez mettre en œuvre de nouvelles exigences.
Nombre d'achats
SELECT customer, COUNT(sale) AS number_of_purchases
FROM sales
GROUP BY customer;
Un index sur les ventes (client, vente) serait préférable pour cette requête.
Valeur du dernier achat
C'est le le plus grand-n-per-groupe problème qui revient fréquemment.
SELECT a.customer, a.sale as max_sale
FROM sales a
LEFT OUTER JOIN sales b
ON a.customer=b.customer AND a.dates < b.dates
WHERE b.customer IS NULL;
En d'autres termes, essayez de faire correspondre la ligne a à une ligne hypothétique b qui a le même client et une plus grande date. Si aucune ligne de ce type n'est trouvée, alors a doit avoir la plus grande date pour ce client.
Un index sur les ventes (client, dates, vente) serait le mieux pour cette requête.
Si vous avez plusieurs ventes pour un client à cette date la plus élevée, cette requête renverra plus d'une ligne par client. Vous auriez besoin de trouver une autre colonne pour briser l'égalité. Si vous utilisez une clé primaire à incrémentation automatique, elle convient comme condition de départage car elle est garantie d'être unique et elle a tendance à augmenter chronologiquement.
SELECT a.customer, a.sale as max_sale
FROM sales a
LEFT OUTER JOIN sales b
ON a.customer=b.customer AND (a.dates < b.dates OR a.dates = b.dates and a.id < b.id)
WHERE b.customer IS NULL;
Montant total des achats, lorsqu'il a une valeur positive
SELECT customer, SUM(sale) AS total_purchases
FROM sales
WHERE sale > 0
GROUP BY customer;
Un index sur les ventes (client, vente) serait préférable pour cette requête.
Vous devriez envisager d'utiliser NULL pour indiquer une valeur de vente manquante au lieu de -1. Les fonctions d'agrégation comme SUM() et COUNT() ignorent les valeurs NULL, vous n'avez donc pas besoin d'utiliser une clause WHERE pour exclure les lignes avec sale <0.
Re :votre commentaire
Les cinq principaux clients du 4e trimestre 2012
SELECT customer, SUM(sale) AS total_purchases
FROM sales
WHERE (year, quarter) = (2012, 4) AND sale > 0
GROUP BY customer
ORDER BY total_purchases DESC
LIMIT 5;
Je voudrais le tester par rapport à des données réelles, mais je pense qu'un index sur les ventes (année, trimestre, client, vente) serait le meilleur pour cette requête.
Dernier achat pour les clients avec un total d'achats > 5
SELECT a.customer, a.sale as max_sale
FROM sales a
INNER JOIN sales c ON a.customer=c.customer
LEFT OUTER JOIN sales b
ON a.customer=b.customer AND (a.dates < b.dates OR a.dates = b.dates and a.id < b.id)
WHERE b.customer IS NULL
GROUP BY a.id
HAVING COUNT(*) > 5;
Comme dans l'autre requête de plus grand n par groupe ci-dessus, un index sur les ventes (client, dates, vente) serait préférable pour cette requête. Il ne peut probablement pas optimiser à la fois la jointure et le groupe par, donc cela entraînera une table temporaire. Mais au moins, il ne fera qu'une seule table temporaire au lieu de plusieurs.
Ces requêtes sont suffisamment complexes. Vous ne devriez pas essayer d'écrire une seule requête SQL qui peut donner tout de ces résultats. Rappelez-vous la citation classique de Brian Kernighan :