Je voulais intervenir avec la possibilité de résoudre votre tâche avec BigQuery pur (Standard SQL)
Pré-requis / hypothèses :les données source sont dans sandbox.temp.id1_id2_pairs
Vous devez le remplacer par le vôtre ou si vous souhaitez tester avec des données factices de votre question - vous pouvez créer ce tableau comme ci-dessous (bien sûr remplacer sandbox.temp avec votre propre project.dataset )
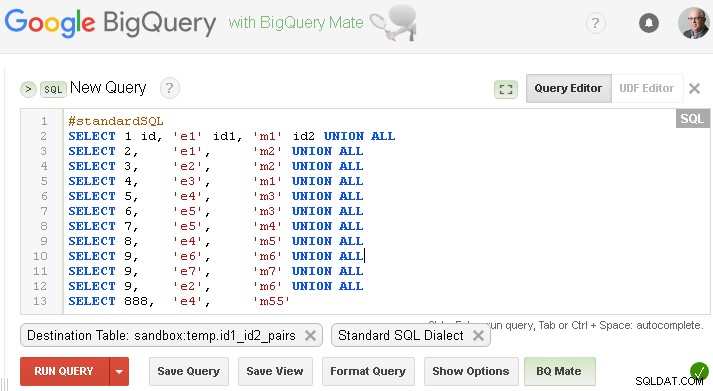
Assurez-vous de définir la table de destination respective
Remarque :vous pouvez trouver toutes les requêtes respectives (sous forme de texte) au bas de cette réponse, mais pour l'instant j'illustre ma réponse avec des captures d'écran - donc tout est présenté - requête, résultat et options utilisées
Il y aura donc trois étapes :
Étape 1 - Initialisation
Ici, nous faisons juste le regroupement initial de id1 en fonction des connexions avec id2 :
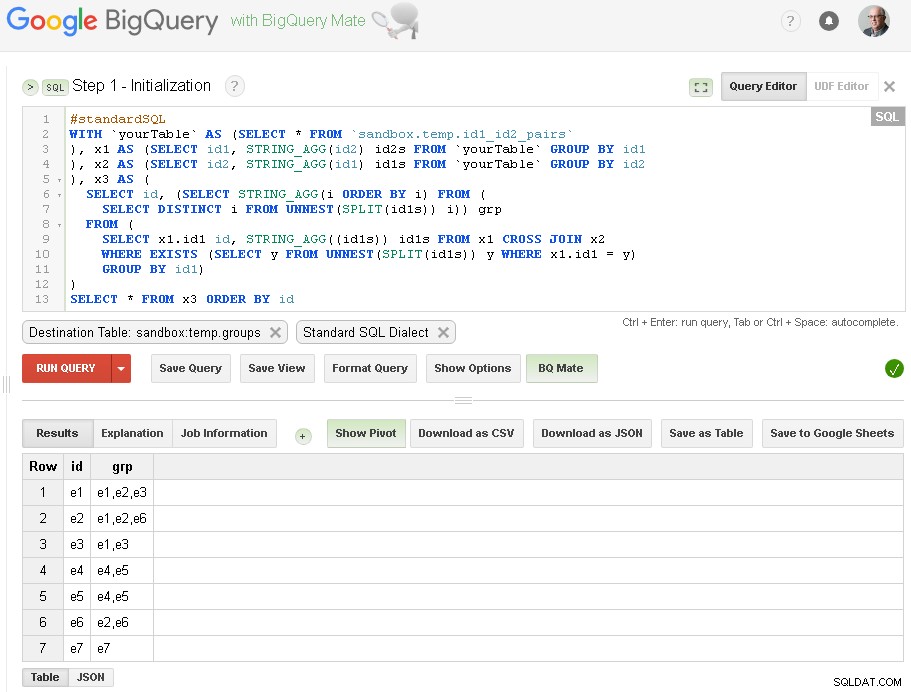
Comme vous pouvez le voir ici - nous avons créé une liste de toutes les valeurs id1 avec des connexions respectives basées sur une simple connexion à un niveau via id2
La table de sortie est sandbox.temp.groups
Étape 2 - Regrouper les itérations
À chaque itération, nous enrichirons le regroupement en fonction des groupes déjà établis.
La source de la requête est la table de sortie de l'étape précédente (sandbox.temp.groups ) et Destination est la même table (sandbox.temp.groups ) avec Remplacer
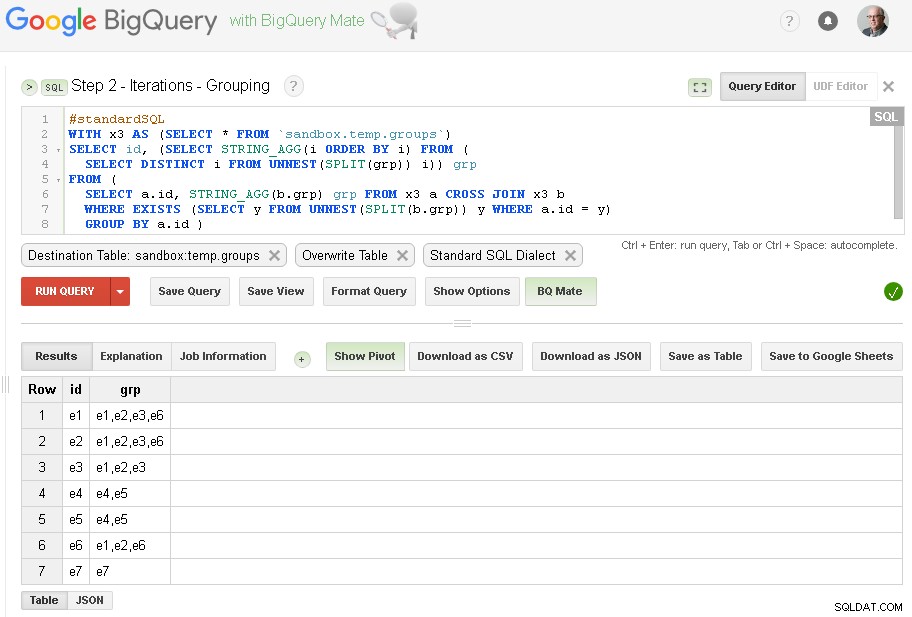
Nous continuerons les itérations jusqu'à ce que le nombre de groupes trouvés soit le même que lors de l'itération précédente
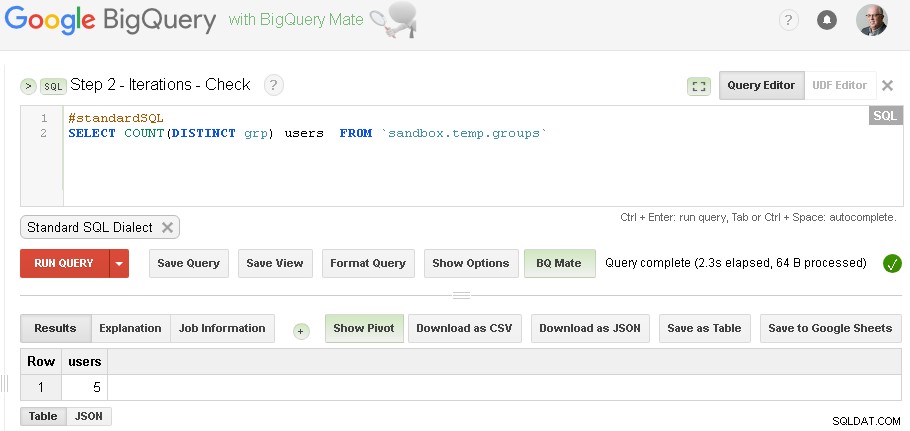
Remarque :vous pouvez simplement ouvrir deux onglets de l'interface utilisateur Web BigQuery (comme indiqué ci-dessus) et sans modifier aucun code, exécutez simplement Grouper, puis vérifiez encore et encore jusqu'à ce que l'itération converge
(pour les données spécifiques que j'ai utilisées dans la section des prérequis - j'ai eu trois itérations - la première itération a produit 5 utilisateurs, la deuxième itération a produit 3 utilisateurs et la troisième itération a produit à nouveau 3 utilisateurs - ce qui indique que nous en avons fini avec les itérations.
Bien sûr, dans le cas réel - le nombre d'itérations pourrait être supérieur à trois - nous avons donc besoin d'une sorte d'automatisation (voir la section correspondante au bas de la réponse).
Étape 3 - Regroupement final
Lorsque le regroupement id1 est terminé - nous pouvons ajouter le regroupement final pour id2
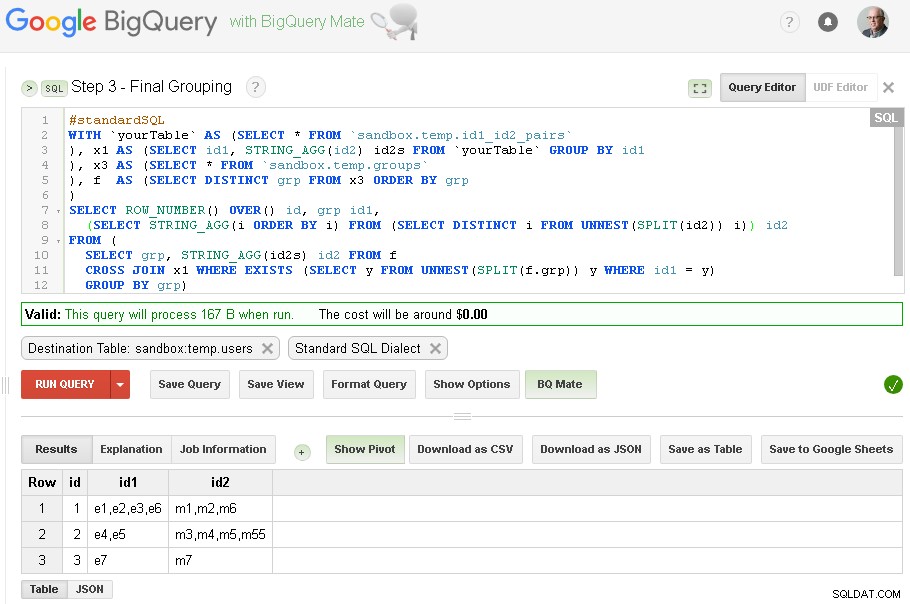
Le résultat final est maintenant dans sandbox.temp.users tableau
Requêtes utilisées (n'oubliez pas de définir les tables de destination respectives et les écrase si nécessaire selon la logique et les captures d'écran décrites ci-dessus) :
Pré-requis :
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Étape 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Étape 2 - Regroupement
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Étape 2 - Vérifier
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Étape 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automatisation :
Bien sûr, le "processus" ci-dessus peut être exécuté manuellement au cas où les itérations convergeraient rapidement - vous vous retrouverez donc avec 10 à 20 exécutions. Mais dans des cas plus réels, vous pouvez facilement automatiser cela avec n'importe quel client
de votre choix