Présentation
À l'heure actuelle, vos conditions de correspondance sont peut-être trop larges. Cependant, vous pouvez utiliser la distance Levenshtein pour vérifier vos mots. Il n'est peut-être pas trop facile d'atteindre tous les objectifs souhaités avec, comme la similitude sonore. Ainsi, je suggère de diviser votre problème en d'autres problèmes.
Par exemple, vous pouvez créer un vérificateur personnalisé qui utilisera une entrée appelable passée qui prend deux chaînes, puis répondra à la question de savoir si elles sont identiques (pour levenshtein qui sera une distance inférieure à une certaine valeur, pour similar_text - quelques pour cent de similarité e t.c. - à vous de définir des règles).
Similarité, basée sur les mots
Eh bien, toutes les fonctions intégrées échoueront si nous parlons de cas lorsque vous recherchez une correspondance partielle - surtout s'il s'agit d'une correspondance non ordonnée. Ainsi, vous devrez créer un outil de comparaison plus complexe. Vous avez :
- Chaîne de données (qui sera dans DB, par exemple). Il ressemble à D =D0 J1 D2 ... Dn
- Chaîne de recherche (qui sera saisie par l'utilisateur). Il ressemble à S =S0 S1 ... Sm
Ici, les symboles spatiaux signifient n'importe quel espace (je suppose que les symboles spatiaux n'affecteront pas la similarité). Aussi n > m . Avec cette définition, votre problème est sur le point de - trouver un ensemble de m mots en D qui sera similaire à S . Par set Je veux dire toute séquence non ordonnée. Par conséquent, si nous trouvons une telle séquence en D , puis S est similaire à D .
Évidemment, si n < m alors l'entrée contient plus de mots que la chaîne de données. Dans ce cas, vous pouvez soit penser qu'ils ne sont pas similaires, soit agir comme ci-dessus, mais inverser les données et les entrées (cela, cependant, semble un peu étrange, mais s'applique dans un certain sens)
Mise en œuvre
Pour faire les choses, vous devrez être capable de créer un ensemble de chaînes qui sont des parties de m mots de D . Basé sur mon cette question
vous pouvez le faire avec :
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-so pour tout tableau, getAssoc() renverra un tableau de sélections non ordonnées composé de m éléments chacun.
La prochaine étape concerne l'ordre dans la sélection des produits. Nous devrions rechercher à la fois Niels Andersen et Andersen Niels dans notre D chaîne de caractères. Par conséquent, vous devrez être en mesure de créer des permutations pour le tableau. C'est un problème très courant, mais je vais aussi mettre ma version ici :
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Après cela, vous pourrez créer des sélections de m mots puis, en permutant chacun d'eux, obtenir toutes les variantes à comparer avec la chaîne de recherche S . Cette comparaison se fera à chaque fois via un rappel, tel que levenshtein . Voici un exemple :
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Cela vérifiera la similarité, basée sur le rappel de l'utilisateur, qui doit accepter au moins deux paramètres (c'est-à-dire des chaînes comparées). Vous pouvez également souhaiter renvoyer la chaîne qui a déclenché le retour positif du rappel. Veuillez noter que ce code ne différera pas des majuscules et des minuscules - mais peut-être que vous ne voulez pas un tel comportement (il suffit alors de remplacer strtolower() ).
Un exemple de code complet est disponible dans cette liste (Je n'ai pas utilisé de bac à sable car je ne sais pas combien de temps la liste de code y sera disponible). Avec cet exemple d'utilisation :
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
vous obtiendrez un résultat comme :
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-ici est une démo pour ce code, juste au cas où.
Complexité
Puisque vous vous souciez non seulement de n'importe quelles méthodes, mais aussi de leur qualité, vous remarquerez peut-être qu'un tel code produira des opérations assez excessives. Je veux dire, au moins, la génération de parties de cordes. Ici, la complexité se compose de deux parties :
- Partie de génération de parties de chaînes. Si vous souhaitez générer toutes les parties de chaîne, vous devrez le faire comme je l'ai décrit ci-dessus. Point possible à améliorer - génération d'ensembles de chaînes non ordonnées (qui vient avant la permutation). Mais je doute toujours que cela puisse être fait car la méthode dans le code fourni ne les générera pas avec une "force brute", mais comme ils sont calculés mathématiquement (avec une cardinalité de
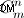 )
) - Partie de vérification de similarité. Ici, votre complexité dépend du vérificateur de similarité donné. Par exemple,
similar_text()a une complexité O(N), donc avec de grands ensembles de comparaison, il sera extrêmement lent.
Mais vous pouvez toujours améliorer la solution actuelle en vérifiant à la volée. Maintenant, ce code va d'abord générer toutes les sous-séquences de chaînes, puis commencer à les vérifier une par une. Dans le cas courant, vous n'avez pas besoin de le faire, vous pouvez donc remplacer cela par un comportement, lorsqu'après avoir généré la séquence suivante, il sera vérifié immédiatement. Ensuite, vous augmenterez les performances pour les chaînes qui ont une réponse positive (mais pas pour celles qui n'ont pas de correspondance).