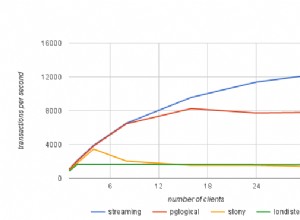
Voici votre tableau.
Shirt
id product color size stock
---------------------------------------------
1 Nike Shirt black M 5
2 Nike Shirt white L 10
3 Nike Shirt blue M 2
4 Nike Shirt blue XL 3
....
Vous voyez comment vous avez dupliqué le nom du produit "Nike Shirt" et la couleur "bleu". Dans une base de données relationnelle normalisée, nous ne voulons pas dupliquer d'informations. D'après vous, que se passerait-il si quelqu'un changeait accidentellement "Chemise Nike" en "Jupe Nike" à la ligne 4 ?
Alors, normaliser votre tableau.
Nous allons commencer par un tableau Produit.
Product
id product
------ ------------
0 Nike Shirt
Généralement, les numéros d'identification de base de données commencent par zéro, et non par un.
Ensuite, créons une table de couleurs.
Color
id color
------ -------
0 black
1 white
2 blue
Ensuite, créons une table de taille.
Size
id size
------ -----
0 XS
1 S
2 M
3 L
4 XL
5 XXL
Ok, nous avons maintenant 3 tables d'objets distinctes. Comment les assembler pour voir ce qui est en stock ?
Vous avez eu la bonne idée avec votre tableau d'origine.
Stock
id product color size stock
---------------------------------------------
0 0 0 2 5
1 0 1 3 10
2 0 2 2 2
3 0 2 4 3
Les numéros de produit, de couleur et de taille sont des clés étrangères qui renvoient aux tables Produit, Couleur et Taille. La raison pour laquelle nous faisons cela est d'éliminer la duplication des informations. Vous pouvez voir que toute information est stockée à un seul endroit et à un seul endroit.
L'identifiant n'est pas nécessaire sur la table Stock. Le produit, la couleur et la taille doivent être uniques, afin que ces 3 champs puissent constituer une clé composée vers la table Stock.
Dans un magasin de détail réel, un produit peut avoir de nombreux attributs différents. Les attributs seraient probablement stockés dans une table clé/valeur . Pour votre tableau simple, nous pouvons diviser le tableau en tableaux relationnels normalisés.